


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
THE FEATURES OF THE GRAPHICS PACKAGE «NOVOSPARK VISUALIZER»

Визуализация является одним из мощных средств интерпретации данных. Под визуализацией данных мы понимаем такой способ представления многомерного распределения данных на двумерной плоскости, при котором качественно отражены основные закономерности, присущие исходному распределению – его кластерная структура, топологические особенности, внутренние зависимости между признаками, информация о расположении данных в исходном пространстве и т.д. Однако исследователь при анализе данных довольно часто сталкивается с многомерностью их описания. Возникает проблема поиска подходящих способов графического представления многомерного объекта.
К настоящему времени разработано много программных и алгоритмических средств визуализации многомерных структур. Однако в ряде задач не удаётся успешно применить обычную технику визуализации. Это связано с тем, что исследователя, как правило, интересуют специфические свойства объектов, которые не удаётся выявить с помощью стандартных подходов. В этом случае возникает потребность в разработке специальных видов представления, ориентированных на конкретную задачу.
Краткое описание системы «Novo Spark Visualizer»
В настоящее время на рынке программных продуктов появился современный инструмент визуализации «Novo Spark Visualizer», позволяющий производить качественный анализ многомерных данных на графическом образе. Визуальный анализ может сыграть важную роль в любом научном эксперименте, особенно там, где необходима быстрая оценка главных аспектов набора данных.
Интуитивный пользовательский интерфейс пакета представляет собой удобную оболочку для работы со сложными наборами многомерных данных и изучения их свойств и взаимозависимостей. Продукт позволяет визуально сравнивать отдельные наблюдения или целые наборы данных. Данные могут быть созданы внутри аппликации либо импортированы из множества источников, включая текстовые файлы со значениями, разделенными запятой или другими разделителями, а также текстовые файлы с фиксированной шириной столбцов, базы данных Microsoft Access. Инструментом поддерживаются все стандартные операции редактирования, позволяющие группировать исходные данные по нескольким критериям и изучать их поведение.
Пакет предназначен для визуализации многомерных данных, отображаемых из n-мерного пространства переменных в двумерные (2D) или трехмерные (3D) геометрические места точек (проекции), именуемые визуализированными графическими образами, которые образуют соответствующие им ментальные ассоциаты в мозгу человека, являющиеся, по свой сути, визуальными когнитивными образами.
Основной идеей визуализационного подхода является представление каждого многомерного наблюдения в виде двумерной кривой. В этом случае, если два наблюдения близки по значениям, их кривые будут очень похожи друг на друга, в то время как если наблюдения отличаются сильно, то и кривые будут очень отличаться. Возможность представить образ в трехмерном пространстве позволяет смотреть на него с разных позиций [6].
Функциональность пакета «Novo Spark Visualizer»
Пакет «Novo Spark Vizualizer» имеет следующие способы использования:
– Визуализация данных.
– Идентификация кластеров данных.
– Сравнение наблюдений.
– Сравнение наборов данных.
– Поиск выбросов.
– Наблюдение за процессом.
Рассмотрим данные способы:
Визуализация данных
Иногда для быстрой оценки основных аспектов нового набора данных достаточно только одного взгляда на его визуальное представление.
Идентификация кластеров данных
Если определен критерий сортировки данных, то на основе этого можно визуализировать кластеры данных. Следующие два образа (рис. 2, 3) демонстрируют, как кластеры могут выглядеть в трехмерном виде и двумерном горизонтальном виде сверху [5].
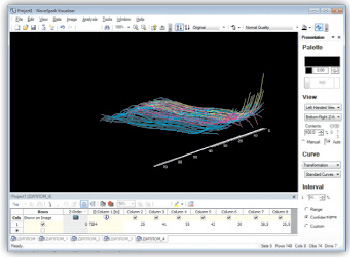
Рис. 1. Визуализация данных
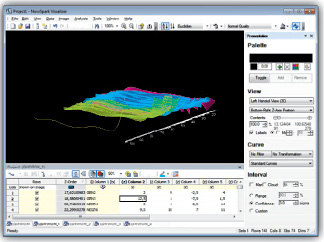
Рис. 2. Кластеры в трехмерном виде
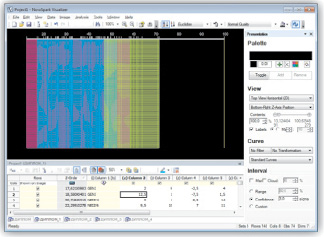
Рис. 3. Кластеры в двумерном горизонтальном виде сверху
Сравнение наблюдений
Для сравнения индивидуальных наблюдений можно использовать их «спектральное» представление, которое подчеркивает отличительные характеристики каждой кривой и помогает более детально исследовать их визуальные свойства. Цветная палитра акцентирует уровни изменения значений кривых. Производя воображаемое растяжение кривых вдоль Z-оси и глядя сверху на результат этой операции, можно получить цветные полоски, представляющие собой спектр каждого наблюдения [3].
Из рис. 4 видно, что при сопоставлении полихроматических рядов 2-х горизонтальных спектров, построенных по единой технологии, можно найти основания для их объективной классификации и соизмерения. Для этого могут быть использованы многоэтапные (многоуровневые) процедуры сравнения по качественным хроматическим признакам [2].
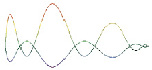

Рис. 4. «Спектры» многомерных наблюдений
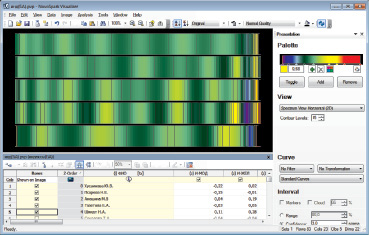
Рис. 5. Спектральное сравнение наблюдений
Образ на рис. 5 представляет собой пример визуализации медицинских показателей физиологических реакций бронхолегочной системы в ответ на психофизиологическое воздействие (аудиовизуальную стимуляцию) пяти пациентов в спектральном виде, т.е. каждая цветная полоска в спектральном виде соответствует показателям одного пациента. Сравнение выборочных данных для четырех форм бронхиальной астмы по визуальной близости спектров наблюдений в [1].
Импорт данных из внешнего источника
Аппликация позволяет импортировать табличные данные из текстового файла или базы данных, поддерживая разнообразные форматы данных.
Программа предоставляет интуитивный интерфейс для выбора источника данных и предварительного просмотра результатов импорта. Несколько файлов или таблиц баз данных могут быть импортированы в один и тот же проект.
Создание нового набора данных
В качестве альтернативы можно ввести данные вручную, например, если внешний источник данных не существует или не доступен для чтения. Новый набор данных будет автоматически приведен к структуре таблиц, уже загруженных в тот же проект.
Редактирование данных
Продукт поддерживает все виды редактирования данных, предоставляя возможность экспериментировать с ними и смотреть, как изменения в данных влияют на их визуальное представление. Таким образом, возможно не только построить любую выборку внутри аппликации, но и посмотреть, как образ этой выборки меняется в соответствии с изменениями, показывая поведение данных в различных сценариях.
Специализированный пакет прикладных программ «Novo Spark Visualizer» обладает рядом достоинств: сравнительно невысокой стоимостью, развитым интерактивным инструментарием динамической визуализации многомерных данных и удобным интерфейсом по обработке визуализированной информации. Исходя из вышесказанного, можно сделать вывод, что «Novo Spark Visualizer» оптимально подходит для решения функциональных задач [1].
Решение прикладных задач на базе пакета «Novo Spark Visualizer»
В технологии визуализации исходных данных по реальным объектам можно выделить несколько основных этапов:
1. Формирование функционально полной совокупности исходных данных.
2. Разбиение исходных данных на кластеры.
3. Сравнение выборочных данных.
На базе пакета «Novo Spark Visualizer» авторами был успешно решен ряд прикладных задач анализа и интерпретации многомерных данных в социальной сфере [4] и медицине [7].
Выводы
Представление многомерного наблюдения в виде двумерного образа (кривой) гарантирует, что близким по значениям наблюдениям A и B будут соответствовать визуально близкие образы-кривые; для сильно различающихся по значениям наблюдений их образы-кривые будут заметно отличаться. Становится возможным автоматически классифицировать наблюдения, определять наиболее важные переменные в модели, производить кластеризацию данных, визуально сравнивать индивидуальные наблюдения и целые наборы данных, а также выполнять много других задач в работе с многомерными данными.
Результаты проведенных авторами исследований позволяют уверенно утверждать, что представленные в статье подходы являются перспективными направлениями в области анализа и представления многомерных экспериментальных данных [1, 2].
Исследование выполнено при финансовой поддержке РФФИ в рамках научных проектов № 15-07-08922 и № 14-07-00675.
Рецензенты:
Берестнева О.Г., д.т.н., профессор, ФГАОУ ВО «Национальный исследовательский Томский политехнический университет» Министерства образования и науки РФ, г. Томск;
Фокин В.А., д.т.н., доцент, профессор кафедры биологической и медицинской кибернетики, ГБОУ ВПО «Сибирский государственный медицинский университет» Министерства здравоохранения и социального развития РФ, г. Томск.
Библиографическая ссылка
Осадчая И.А. ВОЗМОЖНОСТИ ГРАФИЧЕСКОГО ПАКЕТА «NOVO SPARK VISUALIZER» // Фундаментальные исследования. 2015. № 8-3. С. 501-505;URL: https://fundamental-research.ru/en/article/view?id=38927 (дата обращения: 18.06.2026).