


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
THE DEVELOPMENT MANAGEMENT OF THE TERRITORY COMPETITIVENESS WITH THE USE OF ECONOMIC MODELS AND ASSAY TECHNOLOGIES OF BIG DATA

При оценке потребности гармоничного функционирования всех систем, влияющих на социально-экономический уровень развития территории, актуальным представляется формирование новых подходов в аналитике процессов и явлений в сфере прошлых и текущих периодов, а также в прогнозировании будущих.
В первую очередь необходимо принять во внимание, что потоки информации, необходимой для учета и последующей обработки, возрастают с каждым днем, и существующими методами все их учесть и обработать уже сейчас становится затруднительным.
Вместе с тем очевидна необходимость создания современных механизмов и инструментов управления, обладающих способностями учитывать большие потоки разнообразных быстроменяющихся данных [1].
С развитием информационных и компьютерных технологий становится возможным получать, хранить и обрабатывать одновременно не связанные между собой массивы данных, а также анализировать их с точки зрения не только решения тех или иных задач, но и выявления новых [8].
В настоящее время специалисты по информационным технологиям всего мира разрабатывают приложения, которые позволят переложить потенциал этих технологий в практическую плоскость применения. Основные области, в которых идут работы, это: маркетинг, энергетика, промышленность, государственное управление, жилищно-коммунальное хозяйство, банковская и страховая деятельность, био- и нанотехнологии, геоинформационные технологии, безопасность различных сфер жизнедеятельности, здравоохранение и др. Безусловно, многие из этих областей имеют общие характеристики и свойства, однако возможности использования технологий анализа Больших данных позволяют не тратить время на их выявление для каждой сферы в отдельности. Самые актуальные и эффективные корреляции компьютерные алгоритмы обработки Больших данных обнаружат сами [2].
Современные тенденции свидетельствуют о том, что исключительно актуальными становятся приложения, работающие в режиме real time, а сам термин «Большие данные» в ближайшем будущем будет трансформирован просто в «данные» ввиду стремительного развития программно-аппаратных средств [3].
Для разработки конкретных IT-приложений необходимо тем или иным образом локализовать задачи и области исследования для каждого научного коллектива и формировать команды из представителей специалистов сферы IT и специалистов в каждой конкретной прикладной тематике.
В качестве одного из важных направлений в современных условиях выступает социально-экономическое развитие территории [4, 5, 9]. По всему миру постепенно внедряются технологии государственного мониторинга, регулирования и управления на основе Больших данных. Существует мнение, что разработка самых важных государственных реформ в любой стране мира должна обязательно строиться с учетом инноваций в информационных технологиях. Быстроменяющиеся условия, быстроменяющиеся данные и их объемы, автоматизированный процесс непрерывного анализа Больших данных в динамике – это передовые мировые тенденции государственного управления и управления конкурентоспособностью территории сегодня.
Стремительный рост потоковых данных не позволяет специалистам на местах анализировать полный объем информации, что, безусловно, сказывается на точности прогнозов и эффективности разрабатываемых программ по развитию территорий [6], поэтому задача современных руководителей государственного и муниципального сектора – обеспечить доступ автоматизированной системы анализа во все имеющиеся хранилища данных. В итоге органы управления получат доступ в интерактивную модель информационных потоков, с помощью которой можно иметь точное представление о текущей ситуации, делать точные прогнозы, которые будут учитывать как факторы, традиционно влияющие на основные показатели территории, так и элементы из области неопределенности. Речь идет о том, что в структурно ограниченных данных, например статистических, на основе стандартных методов анализа мы можем выделить факторы влияния, их ограничения, критические значения и риски. Однако все эти колебания будут находиться внутри представленных показателей, так же, как и их всевозможные корреляции. Области неопределенности появляются, когда мы подключаем к обработке неструктурированные массивы данных и, выявляя определенные зависимости внутри них, получаем новые вероятностные элементы, способные повлиять на саму исследуемую систему и найти возможные точки бифуркации. Таким образом, положив в основу сбора и мониторинга больших массивов данных принцип real time, мы получаем возможность выявлять не только сами эти области неопределенности, но и вероятности возникновения новых. Следовательно, можно сделать предположение, что совокупность подхода анализа Больших данных в реальном времени и принципов просчета вероятности появления корреляций внутри этих данных представляет собой форму когнитивного прогнозирования, отличающуюся способностью быстро адаптироваться не только к меняющейся среде, но и к обучению на основе данных прошлых и настоящих периодов.
В настоящее время особо актуальными являются задачи формирования потоковых данных о состоянии территории, где в области практической реализации лежат проекты в сфере создания государственных систем аналитики, способных собирать и переводить большой массив данных о территориях в единый формат. Это имеет существенное значение, поскольку при смешивании данных разных массивов между собой возрастает вероятность дополнительной погрешности и ошибки. Для создания системы сбора и анализа потоковых данных предлагается методология, состоящая из следующих этапов.
Первый этап – формирование набора индикаторов социально-экономического уровня региона, который строится на основании существующих статистических показателей.
Второй этап представляет собой формирование новых индикаторов на основе экспертного подхода, которые будут включать в себя данные о сферах деятельности на территории: социально-экономической, промышленной, финансовой, ЖКХ и др.
Третий этап – это постепенное, но повсеместное внедрение системы электронной отчетности (стоит отметить, что в настоящее время, как показывает опыт, большую сложность представляет реализация в сельских территориях).
Четвертый этап – это определение значимости полученных индикаторов и выявление новых с помощью анализа большого массива данных, не ограниченного статистическими границами.
Пятый этап – обучение аналитической системы и наладка ее взаимодействия с программным анализом Больших данных в реальном времени.
Шестой этап – прогнозирование и стратегическое планирование.
Необходимо отметить, что формирование универсальной системы потоковых данных для области государственного и муниципального управления в настоящее время представляется весьма сложной задачей в силу отсутствия инструментальных возможностей получения информации в режиме реального времени по целому ряду направлений. Но вместе с тем, по мнению автора, при наличии государственной программы по сбору информации, основанной на принципах программы интернет вещей, эта задача может быть решена в обозримом будущем в РФ.
Наиболее показательным с точки зрения значимости и эффективности применения технологий Больших данных является четвертый этап. Определение значимости тех или иных показателей – это задача, имеющая два подхода к решению. Первый подход заключается в определении экспертного сообщества на основе анализа больших массивов данных и последующем выявлении их мнения относительно значимости того или иного индикатора. Второй подход – это формирование точного запроса при анализе Больших данных для определения значимости индикатора без учета статуса эксперта. Оба подхода имеют свои достоинства и недостатки, поэтому целесообразно предположить, что их параллельное использование при решении сходных задач может давать более точные результаты и с точки зрения значимости имеющихся индикаторов, и с точки зрения возможности возникновения новых индикаторов, способных повлиять на систему в тех или иных условиях.
Разработанная аддитивно взвешенная экономико-математическая модель управления развитием конкурентоспособности территории имеет следующий вид [7]:
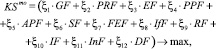 (*)
(*)
где KSmo – конкурентоспособность муниципального образования (территории); ξ – коэффициент значимости группы факторов (определяется экспертным путем посредством анкетирования); GF – географический фактор; PRF – природно-ресурсный фактор; EF – экологический фактор; PPF – фактор промышленного производства; APF – фактор агропромышленного производства; SF – социальный фактор; FEF – финансово-экономический фактор; IfF – инфраструктурный фактор; RF – фактор развития муниципального образования (территории); IF – инновационный фактор; InF – инвестиционный фактор; DF – духовный фактор.
К недостаткам данной модели относится то, что коэффициенты значимости, которые, по сути, во многом определяют значение функции и, соответственно, влияют на принятие управленческих решений, в формуле являются константами, традиционно определяемыми экспертным путем. Как показывает исследовательский анализ, значение этих коэффициентов изменяется во времени и по нелинейной зависимости. И зачастую весовые коэффициенты представляют собой сложную нелинейную функцию.
Достичь более точных результатов, используя аддитивно взвешенные уравнения, возможно, адаптируя и применяя технологии обработки и анализа Больших данных. С их использованием появляется возможность уже на данном этапе научных исследований определять значимости ξ соответствующих факторов практически в реальном времени. Для этого нам потребуется сформировать критерии запросов в интернет-пространстве по выявлению экспертного сообщества по тому или иному фактору, а затем по персональному контенту определить важность необходимого фактора по мнению пользователя с нужными признаками. В этой же связи целесообразно сформировать и запустить алгоритм поиска значимых корреляций без учета привязки к экспертам. Таким образом, появляется возможность выявить пиковые корреляционные значения тех или иных соотношений мнений экспертов и интернет-контента в целом. На основе результатов такого анализа формируются коэффициенты значимости и проводится расчет модели. В то же время при анализе потоковой информации в реальном времени можно прогнозировать возникновение непредвиденных ранее факторов и условий для изменения самой модели конкурентоспособности или возникновения критических величин значимости того или иного фактора (что может свидетельствовать о вероятности того или иного чрезвычайного происшествия, вспышек эпидемий, возникновения экологической катастрофы, социальных возмущений и др.).
Таким образом, применение новых технологий обработки и анализа Больших данных (BIG DATA) позволит получить качественно новые результаты в управлении сложными системами в ключевых отраслях экономики, социальной сферы, науки и техники, государственного и муниципального управления.
Рецензенты:
Дровянников В.И., д.э.н., профессор, проректор по учебной и воспитательной работе, Международный институт рынка, г. Самара;
Герасимов Б.Н., д.э.н., профессор кафедры менеджмента, Самарский институт бизнеса и управления, г. Самара.
Библиографическая ссылка
Рамзаев М.В. УПРАВЛЕНИЕ РАЗВИТИЕМ КОНКУРЕНТОСПОСОБНОСТИ ТЕРРИТОРИИ С ИСПОЛЬЗОВАНИЕМ ЭКОНОМИЧЕСКИХ МОДЕЛЕЙ И ТЕХНОЛОГИЙ АНАЛИЗА БОЛЬШИХ ДАННЫХ // Фундаментальные исследования. 2015. № 6-1. С. 180-183;URL: https://fundamental-research.ru/en/article/view?id=38417 (дата обращения: 02.08.2026).