


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
CONSTRUCTION OF A COMPREHENSIVE SCORING BANKING MODEL BASED ON AN INTELLIGENT ALGORITHM AND FUZZY ASSESSMENT OF THE CAUSALITY OF FACTORS

Введение
Цифровизация банковских процессов и ужесточение пруденциальных требований усилили роль количественных моделей кредитного риска, однако линейное наращивание «скоринг-поиска» вширь и вглубь необязательно конвертируется в стабильно калиброванные вероятности дефолта. Традиционный скоринг хорошо решает задачу ранжирования в стационарной среде, но сталкивается с тремя устойчивыми ограничениями в меняющейся цифровой экосистеме: зависимость от узких источников данных, повышенная чувствительность к спуровым связям при интеграции новых признаков и ухудшение согласования предсказанных вероятностей с наблюдаемыми частотами на временных сдвигах. Эти ограничения усиливаются тем, что бизнес-процесс кредитования заведомо содержит как формализуемые, так и субъективные элементы, и полностью устранить роль экспертной оценки невозможно – следовательно, модель должна быть не только точной, но и интерпретируемой и воспроизводимой в принятии решений. Практика региональных банков подтверждает, что источники данных гетерогенны: кредитные истории, анкеты заемщиков и внешние цифровые следы (операторы связи, агрегаторы платежей, социальные сети, порталы вакансий). Они различаются по полноте покрытия, структурированности и издержкам доступа; часть источников дает информативный сигнал, часть – шум, причем вклад варьирует по регионам и сегментам клиентов. Поэтому задача сегодня – не просто «расширить матрицу признаков», а научно обосновать, какие источники и в какой форме улучшают качество модели, не разрушая калибровку и интерпретируемость.
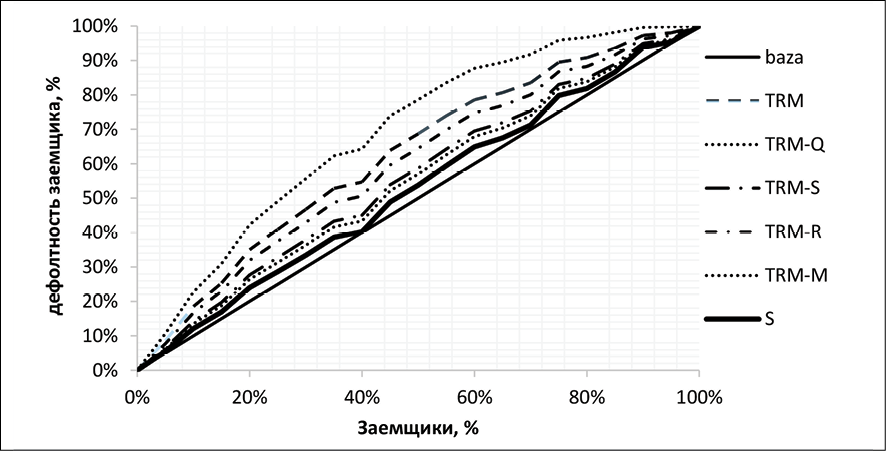
Система сопоставительных экспериментов на реальных портфелях демонстрирует неоднородный вклад дополнительных источников: модель на данных социальных сетей близка к случайной; добавление платежной системы дает результат, сопоставимый с базовой моделью; интеграция данных порталов вакансий улучшает ранжирование, но сдерживается низкой долей покрытия; наилучший прогноз достигается при использовании данных операторов связи. Это – прямое эмпирическое свидетельство несовершенства подхода «больше данных – лучше модель»: одинаковый по объему, но разный по природе источник радикально влияет на качество и переносимость.
Рассматривая научную литературу по теме исследования, можно отметить множество проблем существующих моделей, которые подчеркивают ученые. Так, Абдуллаев Н.А. подчеркивает институциональную обусловленность скоринга: перенос готовых методик между рынками требует адаптации к локальному данным и правовой среде [1]. На этом фоне Помазанов М.В. развивает оценку качества за пределами привычной разделяющей способности, включая метрики точности второго порядка и процедуры калибровки, что приближает моделирование к потребностям риск-прайсинга [2]. Коломиец А.И. систематизирует классические конструкции оценки кредитоспособности и показывает компромисс между простотой и объяснимостью, ключевой для внутренней отчетности и взаимодействия с регулятором [3]. Дорохина Е.Ю. демонстрирует переносимость скорингового принципа в проектное финансирование, где вероятностная логика позволяет стандартизировать решение при высокой разнородности объектов [4]. Тимошенко Н.В., Хаджиев М.Р. и Еремина Н.В. акцентируют роль скоринга на входном фильтре андеррайтинга и взаимосвязь качества модели и регламентов процессов [5]. Кузнецова Е.Ю. расширяет область применения скоринговых подходов к оценке организационных компетенций, что подтверждает универсальность идей агрегирования признаков в интегральные индексы [6]. Тимонин А.С. и Черненький С.В. предлагают практический протокол построения информационной модели кредитной службы и подчеркивают воспроизводимость и документирование – требования, критичные для эксплуатации и аудита [7]. Помазанов М.В., вводя Φ- и Ψ-преобразования, показывает, как корректная трансформация немонотонных переменных повышает дискриминацию, сохраняя экономическую интерпретацию факторов [8]. Расторгуев Л.М. и Микишанина Е.А. фиксируют этапы разработки и валидации моделей кредитоспособности, подчеркивая значимость отбора признаков и тестов стабильности [9]. Родионов А.В. иллюстрирует применение скоринга для управленческого контроля качества обучения: здесь скоринговая логика служит механизмом стандартизации решений в нефинансовом домене [10]. Немкина П.О. и Касаева Т.В. демонстрируют, как интегральные скоринговые оценки могут агрегировать доходы и расходы организации для сопоставимых выводов [11]. Кульшин Р.С., Тикшаев И.Д., Сидоров А.А. и Сенченко П.В. переносят скоринг в персональные рекомендации, подчеркивая конвергенцию риск-аналитики и цифровых сервисов [12].
Астахова А., Гришунин С. и Поморцев Г. строят рейтинговую модель в логике международных агентств, где ключевые – транспарентность и аудируемость, то есть не только предсказательная сила, но и объяснимость [13]. Акжигитова А.Н. показывает адаптацию скоринга для платежеспособности предприятий оборонно-промышленного комплекса, что подтверждает применимость методологии в корпоративном сегменте [14]. Касаева Т.В., Коваленко Ж.А., Немкина П.О. и Чеботарева О.Г. предлагают интегральную оценку качества финансовых потоков на основе скоринга, связывая микропоказатели и сводные индексы [15]. Кармазин А.Р. сравнивает эффективность моделей в факторинге и делает вывод, что выбор алгоритма контекстно зависим от структуры данных и бизнес-ограничений, что сочетается с тезисом о необходимости причинной интерпретации факторов, а не простого наращивания признаков [16]. Совокупно работы формируют рамку для предлагаемой интеграции нечеткой каузальности в скоринг: требуется не только высокая дискриминация, но и корректная калибровка и управленческая объяснимость, обеспечиваемые через количественную оценку причинного вклада факторов и документирование процедур моделирования.
Цель научной работы – разработать комплексную скоринговую модель, сочетающую интеллектуальный алгоритм с монотонными ограничениями и нечеткую оценку каузальности факторов.
Материалы и методы исследования
Данные: розничные договоры потребительского кредитования, 11 513 наблюдений, период открытия договоров с января по июль 2024 года; горизонты наблюдения – двенадцать месяцев; дополнительно – отложенные периоды для вневыборочной проверки. Признаки: анкетные поля, характеристики кредитной истории, агрегированные поведенческие индикаторы, метаданные из внешних источников (платежная система, социальные сети, порталы вакансий, операторы связи). Денежные величины нормировались в тысячах, доли – в процентах, счетчики – в штуках за период; сопоставимость обеспечивалась стратификацией по кварталам и фиксацией определений исходов.
Сравнивались шесть постановок: базовая традиционная модель (TRM), TRM-Q (с добавлением платежной системы), TRM-S (социальные сети), TRM-R (порталы вакансий), TRM-M (операторы связи) и S (модель только на социальных сетях). Качество ранжирования оценивалось через кривые ошибок (ROC) и связанные показатели; калибровка – по согласованию средних вероятностей с наблюдаемыми частотами и регрессии фактов на прогнозы; стабильность – на вневыборочных периодах.
Нечеткая часть методики
1. Преобразование исходных предикторов каждой модели в субнормальные нечеткие множества посредством нормирования.
2. Вычисление α-уровня и индекса нечеткости для отбора существенных предикторов.
3. Оценка истинности правила «если… то…» по импликации Гогена для связи «предиктор – дефолт».
4. Агрегирование максимумов истинности по строкам в комплексную модель.
Контур построения комплексной модели TRM-K Источник: составлено автором на основе исследуемых данных
Таким образом формировалась TRM-K – комплексная модель, включающая только факторы с максимальной причинной силой, при этом сохранялась воспроизводимость вычислений в стандартных прикладных средах (R, Excel) (рисунок). Для деловой интерпретации рассчитывались вклады факторов и сопоставлялись с изменениями потерь по портфелю на исторических данных и в пилоте, где 30% входящего потока в сентябре–октябре 2024 года обрабатывалось по новой схеме.
Результаты исследования и их обсуждение
Рассмотрим ключевые предикторы традиционной скоринговой модели (TRM), которые фиксируют фундаментальные социально-демографические и трудовые детерминанты риска (подтвержденный доход, стаж в организации, образование) и, как правило, обладают очевидной экономической монотонностью, также хорошо подходят для ограничений в интеллектуальном алгоритме (табл. 1). Напротив некоторых полей (например, «место фактического проживания» или «год рождения первого ребенка») трудно аргументировать причинный механизм устойчиво и вне конкретного региона; они информативны как корреляторы, но их влияние может быть неустойчивым на сдвигах состава заявителей. Это и подталкивает к каузальному фильтру: отделить устойчиво причинные факторы от «ситуативных корреляторов» и, следовательно, улучшить переносимость и калибровку на новых периодах.
Десяток факторов подтверждают важность стабильности занятости и доходов: суммарно поля о стаже и верифицированных доходах дают не менее 16% значимости, а вместе с индустрией и семейным доходом – порядка 31%. Это объяснимо: при прочих равных возрастают возможности обслуживания долга и снижается вероятность шоков ликвидности домохозяйства. Вместе с тем в перечень входят предикторы, чья интерпретация менее очевидна вне конкретной территории: место фактического проживания и год рождения первенца по 5% каждый – информативны для конкретного банка и периода, но их «механистическое» включение в гибкую нелинейную модель без учета причинности чревато переобучением на локальные паттерны расселения и когортные особенности. Отдельное внимание заслуживают документы и их «возраст» (лет от выдачи паспорта до обращения – 5%): это прокси переменных, связанных с жизненным циклом и формальной активностью; их вклад устойчив, но опять же зависит от регуляторной и культурной среды.
Итак, уже в традиционной модели виден структурный предел: добавление множества внешних признаков может сместить веса и ухудшить переносимость без гарантии улучшения калибровки. Эмпирические сравнения подтверждают, что модель только на социальных сетях близка к случайной, TRM-Q с платежной системой почти не отличается от базовой, TRM-R с вакансиями заметно лучше ранжирует, но охватывает лишь ~10% анкет, тогда как наилучший прирост дает TRM-M с данными операторов связи. Следовательно, требуется механизм, который, с одной стороны, извлекает добавочную информативность, а с другой – фильтрует корреляционные «шумы» и обеспечивает интерпретируемость причинного вклада. Эту роль в архитектуре исполняет нечеткая каузальность, которая будет продемонстрирована далее.
Таблица 1
Ключевые предикторы традиционной скоринговой модели (TRM) и их значимость
|
№ |
Предиктор |
Значимость, % |
|
1 |
Код времени работы в данной организации |
8 |
|
2 |
Подтвержденный доход |
8 |
|
3 |
Образование |
7 |
|
4 |
Место фактического проживания |
5 |
|
5 |
Год рождения первого ребенка |
5 |
|
6 |
Лет от даты выдачи паспорта до даты обращения |
5 |
|
7 |
Отрасль экономики |
5 |
|
8 |
Совокупный среднемесячный доход семьи |
5 |
|
9 |
Год выпуска автотранспорта |
4 |
|
10 |
Наличие автотранспорта |
4 |
Источник: составлено автором на основе исследуемых данных.
Чтобы применить инструменты нечеткого моделирования для построения комплексной модели, необходимо из имеющейся информации по моделям получить нечеткую. Делается это для того, чтобы агрегировать самую важную информацию из всех применяемых моделей в комплексную модель и получить требуемый результат.
Пусть Xij – значимость i-го предиктора в j-й частной модели (TRM, TRM-Q, TRM-S, TRM-R, TRM-M, S). Сначала переводим их в субнормальные нечеткие множества:
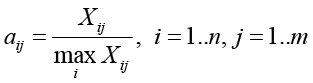 (1)
(1)
И записываем нечеткое множество модели Aj как синглтон:
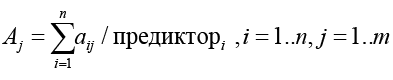 (2)
(2)
Задаем α – уровень для отбора существенных предикторов:
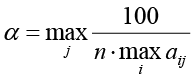 (3)
(3)
Количество оставшихся предикторов имеет смысл обозначить 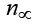 . То есть предлагается считать индекс нечеткости для множества
. То есть предлагается считать индекс нечеткости для множества 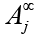 . Индекс нечеткости
. Индекс нечеткости 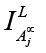 можно теперь подсчитать по стандартной формуле, например по Хэммингу. Заметим, что исследования проводились на разных наборах данных, в разное время, с различным набором предикторов, а это значит, что агрегация в комплексную модель требует определенного процесса моделирования. Нечеткие технологии управления предлагают такой инструмент, основанный на процедуре нечетких импликаций, которая реализуется в формате «Если… то…» и имеет ряд. Применительно к задаче это будет выглядеть так. Производим оценку влияния предиктора на конечный результат по формуле нечеткой импликации Гогена:
можно теперь подсчитать по стандартной формуле, например по Хэммингу. Заметим, что исследования проводились на разных наборах данных, в разное время, с различным набором предикторов, а это значит, что агрегация в комплексную модель требует определенного процесса моделирования. Нечеткие технологии управления предлагают такой инструмент, основанный на процедуре нечетких импликаций, которая реализуется в формате «Если… то…» и имеет ряд. Применительно к задаче это будет выглядеть так. Производим оценку влияния предиктора на конечный результат по формуле нечеткой импликации Гогена:
 (4)
(4)
Такой подход позволит оценить влияние каждого предиктора на конечный результат с учетом специфики каждой модели, чтобы получить комплексную модель влияния предикторов, необходимо найти максимальное влияние по каждой строке, тогда комплексная скоринговая модель будет выглядеть следующим образом:
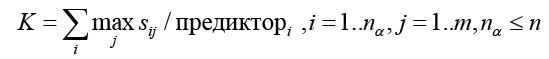 (5)
(5)
В результате проведенных процедур в комплексной модели останутся только значимые предикторы, оказывающие влияние на результат, измеряемый процентом и количеством дефолтников. Стоит отметить и то, что полученные влияния можно считать каузальными, то есть причинными. Построенная модель была реализована средствами языка R и Excel.
Таблица 2
Предикторы и их значимость в комплексной модели TRM-K (нечеткая каузальность)
|
№ |
Предиктор |
Значимость Sij, % |
|
1 |
Балл мобильных операторов |
14 |
|
2 |
Балл Мегафона |
10 |
|
3 |
Подтвержденный доход |
7 |
|
4 |
Код времени работы в организации |
6 |
|
5 |
Год рождения первого ребенка |
6 |
|
6 |
Наличие анкеты на HH.ru / Rabota66.ru |
6 |
|
7 |
Образование |
5 |
|
8 |
Среднемесячный доход на члена семьи |
4 |
|
9 |
Отрасль экономики |
3 |
|
10 |
Лет от выдачи паспорта до обращения |
3 |
Источник: составлено автором на основе исследуемых данных.
Таблица 3
Уровень потерь по розничному кредитованию (новая модель), руб.
|
Год |
Потери (TRK) |
Потери (TRK-K) |
Разница |
|
2022 |
951 750 000 |
951 750 000 |
0 |
|
2023 |
951 750 000 |
750 676 056 |
201 073 944 |
|
2024 |
1 078 650 000 |
850 766 197 |
227 883 803 |
Источник: составлено автором на основе исследуемых данных.
Продемонстрируем результаты работы того, как нечеткая каузальность меняет приоритеты факторов в комплексной модели TRM-K (табл. 2). В отличие от «важности признаков» в конкретной частной модели здесь показана степень причинной силы μ (в терминах истинности по импликации Гогена) и итоговая значимость, которая уже учитывает конкуренцию источников и устойчивость сигнала. Концептуально это решает две практические задачи. Первая – отбор факторов для нормативов и автоматических правил: высокий μ означает, что регуляторные, лимитные и пороговые решения могут безопасно опираться на этот фактор. Вторая – калибровка вероятностей: веса факторов в процедуре калибровки возрастают с μ, что снижает систематические ошибки на краях распределений. Приведем десять предикторов с наибольшей значимостью в TRM-K, полученной из экспериментов, где источники включали мобильных операторов, порталы вакансий и другие внешние каналы. По сравнению с таблицей 1 видно, что верхушку занимают поведенческие и инфраструктурные индикаторы мобильной связи и устойчивые «якоря» платежеспособности (доход, стаж у работодателя), тогда как некоторые демографические прокси отступают, поскольку не выдерживают проверку на устойчивую причинность.
Переразметка приоритетов под действием нечеткой каузальности показательна. Вершину занимает «балл мобильных операторов» с 14% и специфический «балл Мегафона» с 10%: поведенческий след связи выявляет регулярность платежной активности, контактности и устойчивости доходов через прокси-маркеры; при этом высокие значения μ подтверждают устойчивый причинный вклад этих сигналов в риск. Подтвержденный доход (7%) и стаж у работодателя (6%) сохраняют ключевые позиции: их μ стабильно высоки, и они естественные кандидаты для монотонных ограничений. Наличие анкеты на порталах вакансий (6%) оказывается более значимым, чем владение автомобилем и некоторые демографические поля из базовой модели: хотя покрытие низкое (около 10% анкет), сам факт присутствия анкеты несет сильный сигнал «формализованной трудовой активности», который причинно связан с платежной дисциплиной. Напротив, «место проживания» из первой десятки TRM исчезает из топ-10 TRM-K: нечеткий фильтр «наказывает» неустойчивые корреляции, очищая состав предикторов. Суммарно три верхних фактора обеспечивают 31% объяснения, а вся десятка – 64%, что согласуется с улучшением разделяющей способности и калибровки при переходе от традиционной постановки к комплексной. Это проявляется и на полевых метриках: в пилоте (30% входа, сентябрь–октябрь 2024) проблемность снизилась с 7,1% до 5,6% (–1,5 п.п., –21,1% относительно), а пересчет исторических потерь показал экономический эффект в сотни миллионов рублей на горизонте двух лет. Эти цифры административно значимы: они поддерживают принятие решений о масштабировании подхода и включении показателей мобильной связи и формализованной занятости в регламенты.
Итоговая комплексная модель TRK-K, построенная с учетом каузальности связи «фактор → риск», отличается от традиционной как составом предикторов, так и распределением их весов. В пилоте на 30% входящего потока (сентябрь–октябрь 2024) проблемность снизилась с 7,1% до 5,6% (–1,5 п.п., –21,1% относительно). Пересчёт потерь по портфелю указывает на суммарный эффект 429 млн руб. за 2023–2024 годы при неизменности 2022 года (табл. 3); это подтверждает практическую полезность перехода на TRK-K в розничном сегменте.
Заключение
Исследование показало, что классический скоринг ограничен как источниками данных, так и способностью переносить правила на новые периоды без потери калибровки. Интеграция интеллектуального алгоритма с монотонными ограничениями и нечеткой оценкой каузальности факторов решает эту проблему: факторы получают градуированные степени причинной силы, используются в отборе и калибровке, а итоговая модель сохраняет объяснимость для деловых решений. На реальных данных регионального банка комплексная модель TRM-K перестроила приоритеты в пользу поведенческих сигналов связи и формализованной занятости, что сопровождалось снижением проблемности с 7,1% до 5,6% в пилотном периоде и существенным уменьшением потерь в ретро-оценке.
Методологический вклад – формализация нечеткого агрегирования по импликации Гогена как воспроизводимого способа отделить устойчивый причинный вклад от корреляционного шума при объединении разнородных источников. Управленческий вклад – совместимость с требованиями к документации, стабильности и калибровке, а также численно выраженная интерпретируемость для кредитного комитета.
Conflict of interest
Acknowledgements
Financing
Библиографическая ссылка
Назаров Д.М. ПОСТРОЕНИЕ КОМПЛЕКСНОЙ СКОРИНГОВОЙ БАНКОВСКОЙ МОДЕЛИ НА ОСНОВЕ ИНТЕЛЛЕКТУАЛЬНОГО АЛГОРИТМА И НЕЧЕТКОЙ ОЦЕНКИ КАУЗАЛЬНОСТИ ФАКТОРОВ // Фундаментальные исследования. 2025. № 10. С. 36-42;URL: https://fundamental-research.ru/en/article/view?id=43913 (дата обращения: 10.07.2026).
DOI: https://doi.org/10.17513/fr.43913