


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
ECONOMETRIC MODELING OF DEMAND ON ELECTRICITY: VERIFICATION OF ADEQUACY

Необходимым условием устойчивого развития государства является стабильность электроэнергетической сферы, составляющей основу функционирования экономики. Надёжное и доступное электроснабжение – неотъемлемая часть успешного конкурентного развития производства и качества жизни современного общества. Необходимость моделирования и прогнозирования спроса на электроэнергию состоит в значительных издержках, связанных с недостаточным или избыточным строительством электростанций. В условиях ужесточения экологических требований, решение о строительстве новых электростанций должно быть эмпирически обосновано [1].
Моделированию спроса на электроэнергию посвящено множество работ [2, 3]. Подробный обзор мировой эконометрической практики приведен в книге Э.Р. Берндта «Практика эконометрики: классика и современность». Автор обсуждает технику выбора инструментов эконометрических исследований на разнообразных классических и современных статистических данных. В частности, для моделирования спроса на электроэнергию приводятся данные временных рядов по США за 1951–1984 гг., заимствованные из работы Нельсона – Пека (Nelson, Peck) [4]. В книге предлагается приобрести навыки построения и исследования эконометрических моделей, опираясь на опыт авторов статьи.
Данная статья посвящена вопросам методики проверки адекватности модели прогнозирования спроса на электроэнергию Фишера – Кайсена (F.M. Fisher, C. Kaysen) в Excel. Выбор табличного процессора MS Excel обусловлен тем, что он является наиболее доступным средством для числовой обработки экономической информации и особенно эффективен на этапе изучения эконометрических методов [5].
Материалы и методы исследования
В качестве модели прогнозирования спроса на электроэнергию выбрана спецификация множественной линейной регрессии:
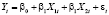 ,
, 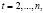 (1)
(1)
с переменными:
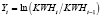 ,
,
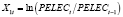 ,
,
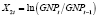 ,
,
где KWH – общее количество электроэнергии, используемой всеми потребителями за год (в млн киловатт-часов); PELEC – средняя цена электроэнергии за 1 кВТ•час (в центах); GNP – валовой национальный продукт США (в млн долл.). Формирование переменных в форме процентных изменений позволяет решить проблему мультиколлинеарности. Уравнения наблюдений модели (1) в матричной форме:
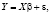
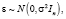
где Y – (n×1) – вектор-столбец значений эндогенной переменной, X – (n×k)-матрица регрессоров, ε – (n×1)-вектор-столбец возмущений, β – (k×1)-вектор-столбец параметров модели, σ2 – дисперсия возмущений, In – (n×n)-единичная матрица, n – объем выборки, k – число параметров модели. Модель оценивается методом наименьших квадратов (значок «Т» означает операцию транспонирования):
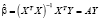 (2)
(2)
– МНК-оценки параметров,
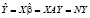 (3)
(3)
– оценки (прогнозы) вектора значений эндогенной переменной.
Точное совпадение фактических данных и прогнозных значений – явление маловероятное. Оценки и прогнозы эндогенных переменных не совпадают с их истинными значениями в силу разных причин: ограниченность выборочных данных, ошибки спецификации (пропуск существенных регрессоров, неправильный выбор уравнения регрессии), ошибки измерений. Обозначим [6]: вектор остатков регрессии (отклонений на интервале оценивания, t ≤ n)
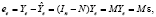
где 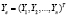 ,
, 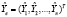 ,
, 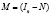 идемпотентная матрица, вектор ошибок прогнозов (отклонений на интервале прогнозирования, например, для t > n)
идемпотентная матрица, вектор ошибок прогнозов (отклонений на интервале прогнозирования, например, для t > n)
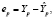
где
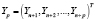 ,
, 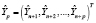 ,
,
p – период упреждения. Автоковариационная матрица вектора отклонений 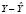 для любого интервала:
для любого интервала:
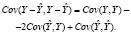 (4)
(4)
На интервале оценивания:
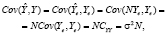 (5)
(5)
поэтому автоковариационная матрица вектора остатков (4), с учетом (5), принимает вид:
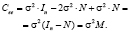 (6)
(6)
На интервале прогнозирования:
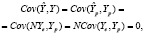 (7)
(7)
в силу некоррелированности возмущений в различных наблюдениях, поэтому автоковариационная матрица вектора ошибок прогнозов, с учетом (4)–(7) равна
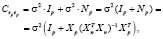 (8)
(8)
где Xp – матрица регрессоров на интервале прогнозирования, Xn – матрица регрессоров на интервале оценивания. Несмещенная оценка дисперсии возмущений, вычисляемая через вектор остатков регрессионной модели
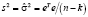 , (9)
, (9)
позволяет оценить автоковариационные матрицы всех случайных векторов.
Проверка адекватности модели по выборочным данным базируется на построении интервальных оценок. Для построения интервальной оценки эндогенной переменной на интервале прогнозирования, применяется процедура трансформации дроби Стьюдента
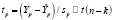
в интервальную оценку
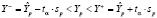 , (10)
, (10)
где 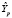 – прогноз значения эндогенной переменной для момента t = p > n, tα – квантиль уровня значимости α, Yp – истинное значение эндогенной переменной на момент t = p, sp – стандартная ошибка прогноза,
– прогноз значения эндогенной переменной для момента t = p > n, tα – квантиль уровня значимости α, Yp – истинное значение эндогенной переменной на момент t = p, sp – стандартная ошибка прогноза, 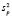 – оценка дисперсии ошибки прогноза – диагональный элемент оценки матрицы (8) (
– оценка дисперсии ошибки прогноза – диагональный элемент оценки матрицы (8) (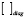 – диагональный элемент матрицы):
– диагональный элемент матрицы):
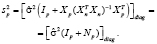 (11)
(11)
Алгоритм проверки адекватности модели состоит из следующих шагов [7]:
1) результаты наблюдений разделяют на две части: обучающую (90–95 % наблюдений) и контролирующую выборки (оставшиеся наблюдения);
2) по обучающей выборке выполняется оценка параметров модели (по формуле (2));
3) по оцененной модели строится прогноз значений эндогенной переменной из контролирующей выборки и доверительные интервалы для их истинных значений (формулы: (3), (9), (11), (10));
4) выполняется проверка: если значения эндогенной переменной из контролирующей выборки накрываются доверительными интервалами – модель признается адекватной, в противном случае подлежит доработке.
Результаты исследования и их обсуждение
Для оценки модели использованы ежегодные данные временных рядов по данным США за 1951–1984 гг. В качестве обучающей выборки в работе [4] предлагается использовать наблюдения с 1951 по 1973 г. (n = 22), контролирующей – с 1974 г. по 1984 г. (p = 11).
Результаты оценивания модели по обучающей выборке в Excel при помощи функции ЛИНЕЙН приведены в табл. 1.
Таблица 1
Результат функции ЛИНЕЙН
|
0,45043 |
–0,41043 |
0,049294 |
|
0,216209 |
0,162311 |
0,008312 |
|
0,473976 |
0,020244 |
#Н/Д |
|
8,560016 |
19 |
#Н/Д |
|
0,007016 |
0,007786 |
#Н/Д |
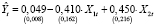 ,
,
s = 0,02, R2 = 0,474, F = 8,560. (12)
Прогноз эндогенной переменной по значениям регрессоров из контролирующей выборки по формуле (12) приведен в табл. 2.
Таблица 2
Точечный прогноз эндогенной переменной
|
Год |
Вектор значений эндогенной переменной Y |
Матрица регрессоров Xp |
Прогноз эндогенной переменной |
||
|
1974 |
–0,004 |
1 |
0,155 |
–0,006 |
–0,017 |
|
1975 |
0,024 |
1 |
0,071 |
–0,012 |
0,015 |
|
1976 |
0,060 |
1 |
0,004 |
0,053 |
0,071 |
|
1977 |
0,049 |
1 |
0,046 |
0,054 |
0,055 |
|
1978 |
0,035 |
1 |
0,004 |
0,049 |
0,070 |
|
1979 |
0,026 |
1 |
–0,004 |
0,028 |
0,064 |
|
1980 |
0,011 |
1 |
0,083 |
–0,004 |
0,014 |
|
1981 |
0,025 |
1 |
0,051 |
0,019 |
0,037 |
|
1982 |
–0,029 |
1 |
0,059 |
–0,015 |
0,018 |
|
1983 |
0,030 |
1 |
–0,014 |
0,036 |
0,071 |
|
1984 |
0,058 |
1 |
0,000 |
0,066 |
0,079 |
Для построения доверительных интервалов значений эндогенной переменной, необходимо вычислить стандартные ошибки прогнозов по формуле (11). Для вычисления Np в Excel используются функции ТРАНСП, МУМНОЖ и МОБР категорий «Ссылки и массивы» и «Математические» соответственно. В табл. 3 представлены значения диагональных элементов проекционной матрицы Np, значения стандартных ошибок прогнозов, левая и правая границы доверительных интервалов и истинные значения эндогенной переменной.
Таблица 3
Интервальные оценки эндогенной переменной
|
Год |
Np |
sp |
Y- |
Y+ |
Yp |
|
1974 |
1,816579 |
0,033974 |
–0,08828 |
0,053936 |
–0,00409 |
|
1975 |
0,591807 |
0,025541 |
–0,03884 |
0,068078 |
0,023847 |
|
1976 |
0,162967 |
0,021831 |
0,025557 |
0,116943 |
0,060068 |
|
1977 |
0,481826 |
0,024643 |
0,002932 |
0,106088 |
0,048969 |
|
1978 |
0,14264 |
0,021639 |
0,02443 |
0,115013 |
0,035079 |
|
1979 |
0,067088 |
0,020912 |
0,0198 |
0,107338 |
0,026013 |
|
1980 |
0,678001 |
0,026223 |
–0,04112 |
0,068647 |
0,011211 |
|
1981 |
0,361146 |
0,023618 |
–0,01261 |
0,086253 |
0,024827 |
|
1982 |
0,507091 |
0,024852 |
–0,03383 |
0,070201 |
–0,02866 |
|
1983 |
0,053016 |
0,020773 |
0,027746 |
0,114705 |
0,030455 |
|
1984 |
0,237543 |
0,02252 |
0,031869 |
0,126139 |
0,057546 |
Как следует из табл. 3, значения эндогенных переменных из контролирующей выборки накрываются доверительными интервалами для всех рассматриваемых наблюдений. Это подтверждает адекватность модели Фишера – Кайсена спроса на электроэнергию.
Реализация матричного алгоритма в Excel затратна по времени. Поэтому для вычисления стандартных ошибок прогнозов на практических занятиях рекомендуется использовать легко реализуемый метод Салкевера (Salkever) [8, 9].
В методе Салкевера, для оценки стандартной ошибки прогноза на момент t = n + 1, в матрицу регрессоров добавляется строка значений регрессоров Xt и столбец фиктивных переменных
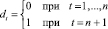 , (13)
, (13)
в вектор-столбец значений эндогенной переменной добавляется значение Yn+1. По сформированным таким способом данным, при помощи функции ЛИНЕЙН, оценивается модель, проверяемая на адекватность. Если исходная спецификация включает свободный член, то он учитывается параметром КОНС = 1. Стандартный протокол функции ЛИНЕЙН включает ошибку прогноза на момент t = n + 1 – оценка параметра при фиктивной переменной (13) и стандартную ошибку прогноза – стандартная ошибка параметра при фиктивной переменной. Справедливость этого утверждения можно показать на модели с фиктивной переменной [10]:
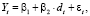
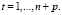 (14)
(14)
Упорядочим наблюдения таким образом, что, dt = 0 при t = 1,...,n, dt = 1, при, 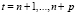 . Обозначим
. Обозначим
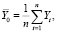
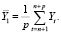
В соответствии с (2)
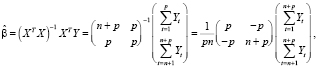
где
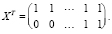
Таким образом, оценка свободного члена модели (14) равна
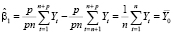 , (15)
, (15)
оценка параметра при фиктивной переменной:
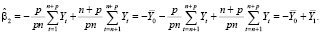 (16)
(16)
Автоковариационная матрица оценок параметров:
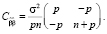
С учетом структуры вектора Y в методе Салкевера, для периода упреждения p = 1:
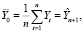
где 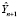 – прогноз значения эндогенной переменной модели;
– прогноз значения эндогенной переменной модели;
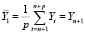
– значение эндогенной переменной на интервале прогнозирования. Таким образом, оценка параметра (16) при фиктивной переменной равна ошибке прогноза эндогенной переменной:
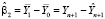 , (17)
, (17)
и, следовательно, дисперсия оценки параметра при фиктивной переменной равна дисперсии ошибки прогноза (с учетом некоррелированности ошибок):
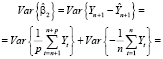
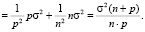 (18)
(18)
В соответствии с (11), дисперсия ошибки прогноза вычисляется по формуле
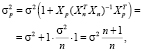 (19)
(19)
где 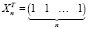 ,
, 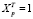 . С учетом значения p = 1, формула (18) дисперсии оценки параметра при фиктивной переменной для модели (14) принимает вид (19) и совпадает с дисперсией ошибки прогноза. Этот же результат подтверждается эмпирической проверкой. Сформируем вспомогательную матрицу регрессоров с блочной структурой [11]:
. С учетом значения p = 1, формула (18) дисперсии оценки параметра при фиктивной переменной для модели (14) принимает вид (19) и совпадает с дисперсией ошибки прогноза. Этот же результат подтверждается эмпирической проверкой. Сформируем вспомогательную матрицу регрессоров с блочной структурой [11]:
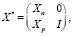
где Xn – (n×k)-матрица значений регрессоров из обучающей выборки (n = 22), Xp – (p×k)-матрица значений регрессоров из контролирующей выборки (p = 3), 0 – (n×p) – нулевая матрица, I – (p×p)-единичная матрица. В табл. 4 приведены элементы вспомогательной матрицы X* для контролирующей выборки, включающей три наблюдения.
Таблица 4
Вспомогательная матрица регрессоров
|
t |
Xt1 |
Xt2 |
Xt3 |
dt1 |
dt2 |
dt3 |
|
|
1 |
0,0758 |
–0,0097 |
0,0363 |
0 |
0 |
0 |
|
|
2 |
0,1065 |
–0,0262 |
0,0372 |
0 |
0 |
0 |
|
|
3 |
0,0683 |
–0,0134 |
–0,0121 |
0 |
0 |
0 |
|
|
4 |
0,1589 |
–0,0770 |
0,0650 |
0 |
0 |
0 |
|
|
5 |
0,0940 |
–0,0523 |
0,0212 |
0 |
0 |
0 |
|
|
6 |
0,0535 |
–0,0154 |
0,0180 |
0 |
0 |
0 |
|
|
7 |
0,0206 |
0,0078 |
–0,0043 |
0 |
0 |
0 |
|
|
8 |
0,0956 |
–0,0354 |
0,0582 |
0 |
0 |
0 |
|
|
9 |
0,0629 |
0,0583 |
0,0212 |
0 |
0 |
0 |
|
|
10 |
0,0482 |
–0,0076 |
0,0260 |
0 |
0 |
0 |
|
|
11 |
0,0733 |
–0,0309 |
0,0562 |
0 |
0 |
0 |
|
|
12 |
0,0683 |
–0,0319 |
0,0394 |
0 |
0 |
0 |
|
|
13 |
0,0729 |
–0,0371 |
0,0514 |
0 |
0 |
0 |
|
|
14 |
0,0627 |
–0,0385 |
0,0586 |
0 |
0 |
0 |
|
|
15 |
0,0815 |
–0,0584 |
0,0580 |
0 |
0 |
0 |
|
|
16 |
0,0600 |
–0,0329 |
0,0267 |
0 |
0 |
0 |
|
|
17 |
0,0904 |
–0,0591 |
0,0451 |
0 |
0 |
0 |
|
|
18 |
0,0883 |
–0,0468 |
0,0275 |
0 |
0 |
0 |
|
|
19 |
0,0577 |
–0,0270 |
–0,0018 |
0 |
0 |
0 |
|
|
20 |
0,0545 |
0,0054 |
0,0333 |
0 |
0 |
0 |
|
|
21 |
0,0816 |
0,0108 |
0,0550 |
0 |
0 |
0 |
|
|
22 |
0,0713 |
–0,0054 |
0,0561 |
0 |
0 |
0 |
|
|
23 |
–0,0041 |
0,1549 |
–0,0064 |
1 |
0 |
0 |
|
|
24 |
0,0238 |
0,0715 |
–0,0119 |
0 |
1 |
0 |
|
|
25 |
0,0601 |
0,0043 |
0,0527 |
0 |
0 |
1 |
|
В табл. 5 приводится протокол оценки модели спроса на электроэнергию (1) при помощи функции ЛИНЕЙН методом Салкевера.
Таблица 5
Вспомогательная матрица регрессоров
|
–0,01118 |
0,009226 |
0,013084 |
0,45043 |
–0,41043 |
0,049294 |
|
0,021831 |
0,025541 |
0,033974 |
0,216209 |
0,162311 |
0,008312 |
|
0,66172 |
0,020244 |
#Н/Д |
#Н/Д |
#Н/Д |
#Н/Д |
|
7,433304 |
19 |
#Н/Д |
#Н/Д |
#Н/Д |
#Н/Д |
|
0,015231 |
0,007786 |
#Н/Д |
#Н/Д |
#Н/Д |
#Н/Д |
Заключение
Сравнение результатов оценивания с табл. 1 и 3 (третий столбец) показывает, что оценки параметров и их стандартные ошибки при регрессорах [ ]diag исходной модели и вспомогательной модели Салкевера совпадают. Стандартные ошибки оценок параметров при фиктивных переменных (отмеченные жирным шрифтом в табл. 5) равны стандартным ошибкам прогнозов, приведенных в табл. 3, используемым для построения интервальных оценок в алгоритме проверки адекватности, но их вычисление намного эффективнее матричного метода при реализации в Excel.
Библиографическая ссылка
Бабешко Л.О. ЭКОНОМЕТРИЧЕСКОЕ МОДЕЛИРОВАНИЕ СПРОСА НА ЭЛЕКТРОЭНЕРГИЮ: ПРОВЕРКА АДЕКВАТНОСТИ // Фундаментальные исследования. 2018. № 12-1. С. 47-52;URL: https://fundamental-research.ru/en/article/view?id=42350 (дата обращения: 03.07.2026).