


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
A MODEL OF INFLUENCE OF TEXT COMMENTS ON THE PSYCHO-EMOTIONAL STATE OF ONLINE MEDIA AUDIENCE

В настоящее время растет количество ресурсов, в которых пользователи интернета могут получать новости и свободно высказывать свое мнение о них. В связи с этим существует и продолжает расширяться спектр атак на информационно-психологическую безопасность личности человека. Защита человека от психологического воздействия является актуальной проблемой, так как методы, используемые для изменения состояния информационной среды и условий жизнедеятельности, способствуют нарушению ценностей, адаптивности функционирования и развития. Через комментарии к статьям СМИ можно воздействовать на объект посредством написания негативных сообщений, которые отрицательно влияют на психологическое и эмоциональное состояние человека [3].
Исходя из вышесказанного, цель работы определена как разработка модели влияния текстовых комментариев на психоэмоциональное состояние аудитории интернет-СМИ.
В соответствии с целью мы определили объект и предмет исследования. Объектом данного исследования являются интернет-СМИ, а предметом исследования – методы автоматизированной оценки психоэмоциональной тональности и классификация комментариев источника аудитории СМИ.
В работе под определением Интернет-СМИ мы будем рассматривать множество сайтов в информационно-телекоммуникационной сети Интернет, деятельность которых связана с периодическим распространением массовой информации под постоянным наименованием (названием).
Исходя из определения, интернет-ресурсы могут быть причислены к профессиональной журналистике, если целевые функции отвечают требованиям, предъявляемым выборными демократиями к прессе, которая должна информировать граждан, а также способствовать их свободам и самоуправлению. Интернет-СМИ описываются с помощью формулы Лассуэлла по пяти главным классификационным признакам: канал, аудитория, коммуникатор, контент, эффекты [7, 8].
Для дальнейшей классификации медийного поля интернета были взяты следующие типы ресурсов:
- индексирующие и классифицирующие информацию по категориям (index and category sites) – Yahoo!;
- информационные агентства (mainstream news sites) – CNN, BBC, MSNBC, Интерфакс, ИТАР-ТАСС, РИА «Новости» и др.;
- метамедийные сайты (meta and comment sites) – это ресурсы экспертного характера, посвященные исключительно СМИ и журналистике;
- сайты, предназначенные для обмена информацией и для дискуссий (share and discussion sites) [2].
Существующие методы
В последние годы ведется много исследований в области определения тональности текстов. Данные разбиваются на две категории (положительные и отрицательные), либо на три (положительные, отрицательные и нейтральные). Много работ посвящено тоновой классификации комментариев на продукты и фильм, анализу блогов и новостей. Были исследованы длинные тексты, принадлежащие некоторой заранее определенной предметной области. Для исследований разрабатывались тренировочные корпусы текстов, обладающие следующими параметрами:
- корпуса отзывов с вручную проставленными потребителями оценками;
- узкотематические корпуса отзывов;
- корпуса общезначимых новостей.
В статье [6] авторы разработали систему определения тональности с помощью глубокого сантимент-анализа, на основе лингвистического анализа текста на естественном языке. Как показывают результаты, с помощью этого метода можно достичь достаточно высокой точности на текстах новости СМИ. Но одной из причин ошибок является ограниченность используемого эмотивного пространства: часть лексики не попадает в пространство хорошо-плохо. Разграничение текста только на негативный и позитивный при разметке словаря сужает способы обработки данных и не решает вопрос, который лежит в области понимания и восприятия информации мозгом человека.
В работах [4, 5] авторы получили результаты для ДСМ-метода решения задачи определения тональности и сравнили его с результатами частотного классификатора и с методом опорных векторов. Результаты, полученные на тестовой коллекции с использованием ДСМ-метода, лучше результатов базового классификатора, на 4 % лучше результатов SVM-классификатора без подбора оптимального числа характеристик.
Промышленные системы автоматической обработки текста используют следующую схему обработки текстов, состоящую из трех этапов:
- морфологический анализ (определение морфологических характеристик каждого слова – часть речи, падеж, склонение, спряжение и т.д.) и морфемный анализ (приставка, корень, суффикс и окончание);
- синтаксический анализ;
- задачи семантического анализа (поиск фрагментов, формализация, реферирование и т.д.).
Разработка модели
В настоящее время разработано немалое количество различных методов, используемых для решения сходных задач. Ниже мы рассмотрим некоторые методы и их адаптацию к данной работе.
Поиск по неоднородным данным со сложной признаковой структурой может проводиться различными методами. Наиболее часто используемым является мера информативности термина. TF-IDF – статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален количеству употребления этого слова в документе и обратно пропорционален частоте употребления слова в других документах коллекции.
Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу, при расчёте меры близости документов при кластеризации [12, 15].
TF – частота слова. Оценивается важность слова в пределах отдельного документа.
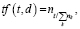 (1)
(1)
где nt есть число вхождений слова в документ, а в знаменателе – общее число слов в данном документе.
IDF – обратная частота документа. Обратное значение частоты, с которой слово встречается в корпусе документов. Учёт IDF понижает вес часто употребляемых слов.
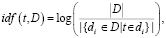 (2)
(2)
где |D| – количество документов в корпусе, 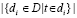 – количество документов, в которых встречается термин t [13, 16].
– количество документов, в которых встречается термин t [13, 16].
Методы, основанные на модели векторного пространства, используют формируемый заранее вектор признаков документа, включающий в себя список наиболее значимых терминов. Дальнейшее сравнение документов проводится путем оценки сходства между полученными векторами с использованием меры косинусного сходства. Косинусное сходство – это метод, основанный на модели векторного пространства, который использует формируемый заранее вектор признаков документа, включающий в себя список наиболее значимых терм, где сравнение документов проводится путем оценки сходства между полученными векторами с использованием измерения косинуса угла между ними [11].
Если даны два вектора признаков, A и B, то косинусное сходство может быть представлено, используя скалярное произведение и норму.
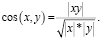 (3)
(3)
Для задачи кластеризации данных и выделения новых признаков объекта были взяты карты Кохонена. Самоорганизующиеся карты – это тип нейронных сетей, которые используют неконтролируемое обучение. Обучающее множество таких моделей состоит из значений входных переменных, в процессе обучения нет сравнивания выходов нейронов с эталонными значениями. Такая сеть способна понимать структуру данных [10, 14].
Приложения, основанные на снижении размерности данных, используют метод факторизации, который позволяет найти компактный способ описания данных, сохраняющий большую часть содержащейся в них информации. Использование низкоразмерных представлений позволяет экономить вычислительные ресурсы и уменьшить число операций в случаях, когда оно зависит от размерности данных. Одним из таких методов факторизации матриц являются неотрицательные матричные разложения.
Задача неотрицательного матричного разложения (NMF) ставится как оптимизационная: необходимо найти неотрицательные факторы, доставляющие минимум некоторому функционалу потерь. Выбор данной функции оказывает большое влияние на получаемое решение. В разных прикладных областях для построения неотрицательного матричного разложения используются разные функции потерь: в тематическом моделировании используется дивергенция Кульбака-Лейблера, в биологических приложениях – норма Фробениуса, в анализе аудиозаписей – дивергенция Итакуры – Сайто, в некоторых задачах машинного зрения – метрика EMD [9].
Подход к решению
Вместо традиционных методов определения тональности текста, таких как классификация векторов семантических дифференциалов или ДСМ-метод, в нашем подходе используется многоэтапное преобразование данных, основанное на психоэмоциональных показателях, с их дальнейшей классификацией.
Мы выделили четыре стадии преобразования данных (рисунок):
- выделение слов из комментария и их лемматизация;
- вычисление для каждого уникального слова вектора эмоциональных показателей tf-idf;
- инициализация самоорганизующейся карты кохонена и ее обучение на полученных из предыдущего этапа векторов;
- снижение размерности весовых показателей синапсов самоорганизующейся карты неотрицательным матричным разложением до двухмерного представления.
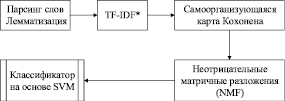
Схема преобразования данных
Начальным этапом преобразования данных является выделение слов из текста, где каждое слово будет преобразовано в нормальную форму.
В данной работе мы учитываем эмоциональную окраску каждого слова с целью определения психоэмоциональной значимости относительно окраски корпуса текстов. В результате была произведена корректировка формулы вычисления TF-ID. Каждому слову в словаре будет назначаться 11-мерный вектор, где каждый его элемент, характеризует одну из базовых эмоций: Удивление, Печаль, Гнев, Отвращение, Презрение, Горе-страдание, Стыд, Интерес-волнение, Вина, Смущение, Радость (классификация эмоций по К. Изарду [1]).
После дополнений формулы, она приобрела следующий вид:
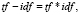 (4)
(4)
где множители принимают следующий вид:
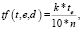 (5)
(5)
где k – количество раз использования термина в тексте d, te – коэффициент e-ой эмоции термина t, n – количество слов в документе.
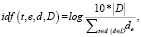 (6)
(6)
где t – термин, e – номер эмоции, d – текст, D – корпус исследуемых текстов, 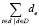 – сумма e-ых эмоциональных коэффициентов всех текстов, которые содержат термин t.
– сумма e-ых эмоциональных коэффициентов всех текстов, которые содержат термин t.
Механизм машинной синестезии изображения с целью выявления скрытых эмоциональных характеристик слов предлагаем основывать на картах Кохонена. В начале инициализируем нейронную сеть с весовыми коэффициентами равными обратным значениям коэффициентов сети, обученной на всем эталонном корпусе слов. Обратное значение вычисляется как 1-wij, где wij – вес i-го нейрона j-го синапса. Далее на вход сети поочередно поступают психоэмоциональные вектора слов, содержащихся в тексте. Результатом данного этапа является кластеризация данных в многомерном пространстве по показателям признаков.
Далее, полученное многомерное пространство будет сжато NMF методом. Оптимальность функции потерь в конкретной прикладной задаче зависит от структуры шума, содержащегося в данных. В данном исследовании была использована норма Фробениуса, для преобразования данных синаптических весов нейронной сети в двухмерное изображение.
Итогом работы алгоритма является преобразование изображения в n-мерный вектор, где n = h*d, h – высота изображения, d – ширина изображения, который подается на вход классификатору. Классификатор основан на методе опорных векторов, ядро представлено сигмоидальной функцией. Классификатор обучается на размеченной эталонной выборке текстов, которые были получены путем социально-психологического опроса. Тексты разделены на три класса: негативные, нейтральные и позитивные.
Выводы
Практическая значимость исследования заключается прежде всего в создании методики психоэмоциональной оценки текстовых сообщений, автоматизация которой в дальнейшем позволит включить её в качестве модуля в состав автоматизированной системы фильтрации пропагандистских, агитационных, рекламных и прочих материалов, вызывающих негативное психоэмоциональное воздействие на личность человека. Это позволит сократить время обработки процедуры анализа, сократить количество экспертов, работающих на данном этапе процедуры, а также значительно повысить объёмы анализируемой информации. И таким образом, общий процент фильтрации сообщений, не удовлетворяющих требованиям пользователя, будет повышаться.
Библиографическая ссылка
Монахов Ю.М., Маков Е.О. МОДЕЛЬ ВЛИЯНИЯ ТЕКСТОВЫХ КОММЕНТАРИЕВ НА ПСИХОЭМОЦИОНАЛЬНОЕ СОСТОЯНИЕ АУДИТОРИИ ИНТЕРНЕТ-СМИ // Фундаментальные исследования. 2017. № 11-1. С. 98-102;URL: https://fundamental-research.ru/en/article/view?id=41905 (дата обращения: 17.06.2026).
DOI: https://doi.org/10.17513/fr.41905