


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
MODEL OF MULTILINGUAL INTELLIGENT INFORMATION SEARCH WITH THE MULTI-AGENT REALIZATION

Многоязыковой информационный поиск – процесс поиска информации в сети Интернет на нескольких языках. При автоматическом многоязыковом поиске пользователь вводит запрос на одном языке, а поисковая система должна обеспечивать перевод запроса на указанные языки и предоставлять ранжированные результаты на всех выбранных языках.
Большинство широко известных поисковых систем, таких как Yandex, Google и др., не реализуют всех функций автоматического многоязыкового поиска. Так, например, поисковые системы Yandex и Google не обеспечивают поиск по переводам введенных терминов. А объявленная возможность многоязыкового поиска Google [3] предполагает поиск по введенному запросу среди документов на других языках. Отсутствие многоязыкового поиска в указанных системах предполагает выполнение перевода терминов и ранжирование результатов поисков на различных языках вручную.
Немногочисленные существующие многоязыковые поисковые системы имеют существенные недостатки, а именно значительное время поиска и сложные методы ранжирования найденных документов, применение которых дополнительно увеличивает время отклика системы.
Уменьшить время многоязыкового поиска можно, используя распараллеливание обработки. С этой целью целесообразным представляется применение мультиагентных платформ для реализации поисковых систем. Помимо обычного распараллеливания мультиагентная организация при наличии соответствующих ресурсов позволяет выполнить масштабирование системы.
Однако для разработки эффективной мультиагентной реализации системы необходимо исследовать процесс многоязыкового информационного поиска и построить его модель.
Целью настоящего исследования является разработка структурной модели процесса многоязыкового интеллектуального поиска, которая позволит проанализировать процесс поиска и выполнить его декомпозицию для последующей реализации взаимодействующими мультиагентами. Кроме этого, модель процесса должна учитывать неопределенность характеристик документов, на базе которых выполняется оценка релевантности документов запросу.
Модель процесса интеллектуального информационного поиска на трех языках
В [1] рассмотрена модель процесса интеллектуального информационного поиска текстовых документов с помощью мультиагентной системы на одном языке. При этом предполагается выполнение следующих операций:
- ввод запроса;
- поиск в Интернете по ключевым словам;
- извлечение информации из Веб-источников;
- интеллектуальный анализ извлеченных документов;
- получение оценок релевантности документов запросам;
- ранжирование документов по степени релевантности.
Модель представляет собой нечеткий метаграф, поскольку указанная модель является иерархической и позволяет отобразить совокупность операций, выполняемых в процессе поиска одним мультиагентом. Неточность оценок релевантности документов в этой модели отображается в виде нечеткого множества вершин нечеткого метаграфа.
Модель многоязыкового информационного поиска на базе мультиагентной реализации имеет свои особенности. Так, эта модель помимо необходимости перевода терминов, задаваемых пользователем на одном языке, должна учитывать:
- необходимость отдельных поисков в Интернете по запросу на каждом языке;
- особенности интеллектуального анализа текстов на различных языках;
- необходимость совместного ранжирования полученных результатов.
Первая операция многоязыкового поиска – ввод запроса. Эту операцию целесообразно выполнять отдельным интерфейсным агентом.
Следующая операция – перевод на указанные языки. Эту операцию должен выполнять агент-переводчик. Анализ показал, что при переводе по возможности следует использовать словарь терминов (устоявшихся словосочетаний), а не отдельных слов [6, 9]. Это обеспечит лучшее качество перевода и исключит извлечение нерелевантных документов.
Операции поиска выполняются отдельно с разными переводами запроса. Однако за счет индексирования и других приемов ускорения время поиска по сравнению с временем выполнения других операций невелико, а потому поиск целесообразно выполнять одним агентом, обращаясь для получения ссылок к одной из поисковых систем (Google, Yandex и т.п.).
Операции извлечения и анализа текстов выполняются для каждого языка отдельно, поскольку документы на различных языках будут обрабатываться с использованием соответствующих правил языков. Интеллектуальный анализ текстов включает лексемизацию, фильтрацию и лемматизацию, что позволяет увеличить точность оценки релевантности документов [7, 8].
В [2] для оценки релевантности документов предложено использовать векторную меру и статистические веса появления терминов в документах. Неточность этих оценок частично скомпенсирована за счет использования экспертной системы на базе нечеткого логического вывода Сугено [2]. Правила для системы нечеткого логического вывода формируются с использованием характеристик вершин нечеткого метаграфа.
Операция оценки релевантности уже не зависит от языка, поскольку на этом этапе для всех документов должна использоваться единая мера сходства. Однако выполнение этой операции разными агентами для различных языков увеличит возможности распараллеливания процесса.
Операции извлечения, анализа текстов и оценки релевантности передают друг другу большие объемы информации (тексты документов). Передача этих данных различными агентами через сообщения нецелесообразна, поэтому эти операции следует выполнять одним агентом для каждого языка.
Операция ранжирования должны выполняться над всеми документами сразу, поэтому ее также должен выполнять один агент.
Тогда структура нечеткого метаграфа  , представляющего собой модель процесса многоязыкового интеллектуального поиска, описывается следующим образом:
, представляющего собой модель процесса многоязыкового интеллектуального поиска, описывается следующим образом:
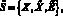
где 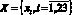 – множество операций, осуществляемых в процессе поиска и интеллектуальной обработки документов;
– множество операций, осуществляемых в процессе поиска и интеллектуальной обработки документов; 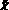 – нечеткое множество на X – множество операций (табл. 1), осуществляемых в процессе поиска и интеллектуальной обработки документов с учетом неопределенности
– нечеткое множество на X – множество операций (табл. 1), осуществляемых в процессе поиска и интеллектуальной обработки документов с учетом неопределенности 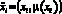 , где ? – функции принадлежности, ?xi ? X??: xi ? [0, 1];
, где ? – функции принадлежности, ?xi ? X??: xi ? [0, 1];
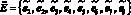 – множество сообщений, передаваемых между мультиагентами:
– множество сообщений, передаваемых между мультиагентами:
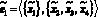 – передается запрос;
– передается запрос;
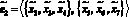 – передаются запрос и его переводы;
– передаются запрос и его переводы;
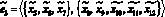 – передаются извлеченные тексты документов;
– передаются извлеченные тексты документов;
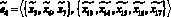 – передаются извлеченные тексты документов;
– передаются извлеченные тексты документов;
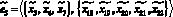 – передаются извлеченные тексты документов;
– передаются извлеченные тексты документов;
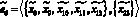 – передаются оценки релевантности документов;
– передаются оценки релевантности документов;
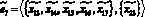 – передаются оценки релевантности документов;
– передаются оценки релевантности документов;
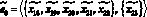 – передаются оценки релевантности документов.
– передаются оценки релевантности документов.
Таблица 1
Условные обозначения элементарных операций поиска
|
Элемент множества |
Обозначение |
Операция |
|
|
UI |
Ввод ключевых слов пользователем |
|
|
AR, RU, EN |
Перевод ключевых слов на остальные языки |
|
|
URL |
Поиск ссылок на каждом языке |
|
|
RD |
Извлечение документов |
|
|
DT |
Лексемизация документов |
|
|
DF |
Фильтрация документов |
|
|
DS |
Лемматизация документов |
|
|
TW |
Вычисление весов терминов |
|
|
OE |
Вычисление оценок релевантности и ранжирование результатов |
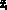
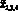
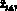
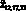
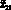
Каждому агенту в модели соответствует подмножество операций:
- интерфейсному агенту –
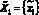 ;
; - агенту-переводчику –
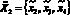 ;
; - поисковому агенту –
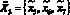 ;
; - агенту извлечения документов и интеллектуальной обработки текстов на арабском языке –
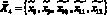 ;
; - агенту извлечения документов и интеллектуальной обработки текстов на русском языке –
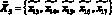 ;
; - агенту извлечения документов и интеллектуальной обработки текстов на английском языке –
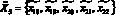 ;
; - агенту ранжирования результатов поиска –
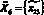 .
.
Аналогично могут быть построены модели информационного поиска, рассчитанные на большее количество языков. Для добавления еще одного языка следует добавить словари для перевода терминов на этот язык и интеллектуального агента, умеющего выполнять анализ текстов на этом языке.
Реализация системы многоязыкового интеллектуального поиска на мультиагентной платформы JADA
Процесс многоязыкового информационного поиска был реализован в виде мультиагентной системы. В качестве программной среды при этом была использована среда JADE (Java Agent Development Framework) [5]. Эта среда является программным обеспечением для разработки агентских приложений в соответствии со спецификациями FIPA [4] для взаимозаменяемых интеллектуальных мультиагентных систем.
На рис. 2 показан вывод агента-переводчика пользовательского запроса «database».
Выполненная реализация позволила исследовать процесс интеллектуального многоязыкового информационного поиска. Так, в табл. 2 показаны результаты вычисления весов терминов для запроса «Искусственный интеллект». Указанный запрос был переведен на английский и арабский языки, и полученные три запроса были переданы поисковой системе Google. Анализ представленных результатов подтверждает необходимость совокупного ранжирования полученных документов, поскольку среди первых 7 найденных документов на каждом языке присутствуют документы с низкими характеристиками весов терминов, т.е. документы, которые на основании вычисленных характеристик релевантности должны быть признаны нерелевантными.
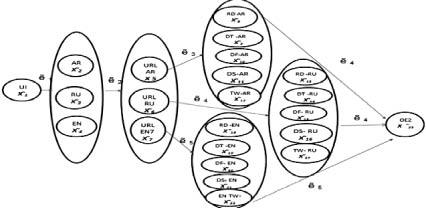
Рис. 1. Модель процесса интеллектуального информационного поиска на трех языках: RU – русском; EN – английском; AR – арабском
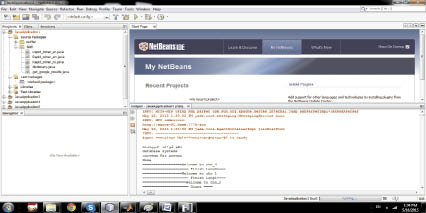
Рис. 2. Вывод агента-переводчика пользовательского запроса со словом «database»
Таблица 2
Взвешенные нормализованные веса терминов для первых семи документов, найденных по запросу «Интеллект искусственный»
|
Арабский язык. Нормализованный вес термина |
Английский язык. Нормализованный вес термина |
Русский язык. Нормализованный вес термина |
|||
|
|
|
Artifici |
Intellig |
Интеллект |
искусственный |
|
0,812 |
0,583 |
0,456 |
0,494 |
0,781 |
0,625 |
|
0 |
0 |
0,832 |
0,555 |
0,707 |
0,707 |
|
0,657 |
0,478 |
0,024 |
0,975 |
0,707 |
0,707 |
|
0 |
0 |
0,618 |
0,786 |
0,708 |
0,707 |
|
0,994 |
0,110 |
0 |
0 |
0,723 |
0,690 |
|
0 |
0 |
0,678 |
0,735 |
0,707 |
0,707 |
|
0,942 |
0,099 |
0,707 |
0,707 |
0,669 |
0,706 |
На рис. 3 показана диаграмма прироста времени поиска при добавлении одного языка. За счет распараллеливания обработки этот прирост составляет примерно 25 ± 10 %, что зависит от количества документов, найденных в Интернете по конкретному запросу на добавленном языке.
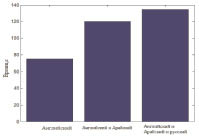
Рис. 3. Зависимость времени работы системы от количества используемых языков
Эксперимент был осуществлен с использованием следующего оборудования: ЦП Intel (R) core (TM) i7-2670 QM CPU @2.20 GHZ, установленная память (ОЗУ): 6.00 ГБ и тип ОС: 64-битная операционная система.
Заключение
В статье предложена модель многоязыкового интеллектуального информационного поиска в виде нечеткого метаграфа, которая позволяет отобразить основные особенности указанного процесса с учетом последующей реализации поисковой системы на мультиагентной платформе.
Исследование выполненной реализации позволяет сделать вывод об обязательности ранжирования совокупности результатов выполнения многоязыковых поисковых запросов.
Статистическая обработка результатов исследования мультиагентной реализации позволяет сделать вывод о том, что прирост времени при добавлении одного языка зависит от количества документов на этом языке, найденных при выполнении запросов, и составляет примерно 25 ± 10 %.
Библиографическая ссылка
Шоуман М.А. МОДЕЛЬ ПРОЦЕССА МНОГОЯЗЫКОВОГО ИНТЕЛЛЕКТУАЛЬНОГО ИНФОРМАЦИОННОГО ПОИСКА С УЧЕТОМ МУЛЬТИАГЕНТНОЙ РЕАЛИЗАЦИИ // Фундаментальные исследования. 2015. № 12-4. С. 724-728;URL: https://fundamental-research.ru/en/article/view?id=39612 (дата обращения: 29.07.2026).
DOI: https://doi.org/10.17513/fr.39612