


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
ANALYSIS OF THE EFFECT OF TEXT REPRESENTATION MODELS ON THE QUALITY OF REVIEW SENTIMENT CLASSIFICATION

В современном мире мнения, содержащиеся на таких веб-ресурсах, как социальные сети, блоги и форумы, оказывают сильное влияние на людей при выборе товаров и услуг, при формировании отношения к определенным явлениям, организациям или персонам. В связи с этим активно развивается одно из направлений компьютерной лингвистики – автоматический анализ мнений в текстах, который применяется при проведении маркетинговых, экономических, социальных и других видов исследований [7]. Одной из основных задач анализа мнений является классификация текстов по тональности, т.е. определение выраженной в тексте эмоциональной оценки по отношению к некоторому объекту.
В настоящей работе рассматривается бинарная шкала тональности, включающая два значения – позитивное и негативное. Классификация осуществляется на основе ДСМ-метода автоматического порождения гипотез, предложенного В.К. Финном в конце 1970-х гг. [1]. Целью работы является исследование влияния векторной и графовой моделей представления текстов на качество классификации отзывов по тональности.
Модели представления текста
Модель представления текстового документа является важной составляющей в процессе его компьютерной обработки. Выбор модели определяет эффективность выделения смыслового содержания и структуры документа. В настоящей работе исследуются две модели – векторная и графовая. Выбор моделей обусловлен существенным их различием в способности отражения структуры документа. Сравнительный анализ данных моделей позволит оценить эффективность использования информации о связях между терминами в задаче классификации по тональности.
Векторная модель – алгебраическая модель для представления текстовых документов в виде векторов в пространстве признаков. Предложена Дж. Солтоном в 1975 году [9]. В векторной модели документ рассматривается как множество терминов, в качестве которых могут выступать отдельные слова или словосочетания. Каждая компонента вектора признаков соответствует отдельному термину. Числовое значение компоненты совпадает с весом термина, который характеризует важность данного термина для представления содержащего его документа. Если термин не встречается в документе, то его вес в этом документе равен нулю.
Векторная модель имеет ряд недостатков:
1) теряются взаимосвязи между словами;
2) если документы имеют одинаковый смысл, но состоят из разных слов, то сложно выявить сходство документов;
3) сложность представления больших документов.
Модель представления текста в виде графа позволяет устранить указанные недостатки. Такое представление эффективно моделирует связи между терминами и отражает информацию о структуре документа. При этом вершинам графа ставятся в соответствие отдельные термины, а ребрам – связи между ними. В настоящей работе каждый текст представлялся в виде графа совместно встречающихся слов. Множество вершин графа формировалось из уникальных слов, входящих в текст. Для расстановки ребер проводилось сканирование текста окном заданного размера. Ребро между двумя вершинами в графе устанавливалось в том случае, если соответствующие этим вершинам слова в тексте одновременно находились в пределах сканирующего окна. Данный подход является достаточно простым в реализации и основан на наблюдении из [8], что между двумя находящимися рядом словами часто существует семантическая связь.
Сравнительный анализ рассмотренных моделей осуществлялся в рамках задачи классификации текстов по тональности на основе ДСМ-метода.
ДСМ-метод
ДСМ-метод автоматического порождения гипотез является представителем логического подхода в интеллектуальном анализе данных. Преимуществом ДСМ-метода по сравнению со статистическими методами является прозрачность процесса логического вывода и хорошая интерпретируемость генерируемых гипотез [3]. ДСМ-метод реализует синтез трех познавательных процедур – эмпирической индукции, структурной аналогии и абдукции [1]. В настоящей работе рассматриваются две процедуры – индукции и аналогии.
Идея метода заключается в следующем [3]. Имеются две коллекции текстов: обучающая и тестовая. В процедуре индукции осуществляется поиск максимальных общих фрагментов текстов обучающей коллекции. Такие общие фрагменты называются гипотезами. Например, для текстов «Один из лучших фильмов, которые видел в последнее время» и «Давно не видел настолько хорошего фильма» гипотезой будет множество, состоящее из трех слов: <фильм, видеть, хороший>. Для каждого класса тональности формируется отдельное множество гипотез. В процедуре аналогии осуществляется поиск этих гипотез в текстах классифицируемой коллекции. В результате для одного и того же текста могут быть найдены как позитивные, так и негативные гипотезы. В этом случае возникает ситуация конфликта. Для ее разрешения гипотезы передаются в функцию разрешения конфликтов [4], которая присваивает тексту определенный класс тональности на основе некоторого критерия, например соотношения мощностей множеств гипотез каждого класса, найденных в классифицируемом тексте.
В работе осуществляется формирование гипотез с учетом векторной и графовой моделей представления текстов. При использовании графовой модели предполагается получение гипотез, отличных от гипотез в векторной модели, за счет наличия информации о связях между словами. Преимуществом графовых гипотез является более точная передача семантики текстов вследствие наличия близко расположенных терминов, образующих осмысленные словосочетания.
Методика проведения эксперимента
В ходе исследования использовались следующие материалы, инструменты и методы.
1. Коллекции отзывов.
Обучающая коллекция составлена из корпуса текстов семинара РОМИП-2011 [6], который содержит отзывы интернет-пользователей на фотокамеры, книги и фильмы. Отзывы собраны с сайтов imhonet.ru и market.yandex.ru. Каждый отзыв имеет оценку по шкале тональности: в категории «камеры» – от 1 до 5, в категории «книги» и «фильмы» – от 1 до 10. Для товаров категории «камеры» пятибалльная шкала приведена к двухбалльной по схеме: {1, 2} → «–», {4, 5} → «+»; для товаров категории «книги» и «фильмы» десятибалльная шкала приведена к двухбалльной по схеме: {1…4} → «–», {7…10} → «+». С целью учета близкого контекста отзывы поделены на предложения, и дальнейший анализ осуществлялся на уровне предложения. Характеристики обучающей коллекции представлены в табл. 1.
Таблица 1
Характеристики текстовых коллекций
|
Параметр |
Предметная область |
|||
|
Камеры |
Книги |
Фильмы |
||
|
Количество отзывов |
позитивных |
3 387 |
3 000 |
1 500 |
|
негативных |
3 951 |
2 060 |
1 500 |
|
|
Количество предложений |
позитивных |
14 384 |
11 149 |
12 847 |
|
негативных |
13 524 |
11 076 |
12 716 |
|
|
Среднее количество слов в отзыве |
позитивном |
37 |
32 |
125 |
|
негативном |
30 |
50 |
103 |
|
|
Среднее количество слов в предложении |
позитивном |
9 |
9 |
15 |
|
негативном |
9 |
10 |
12 |
|
При классификации тестовой коллекции оценивалось отдельно каждое предложение отзыва. Для получения оценки отзыва в целом производилось суммирование оценок его предложений: отзыву присваивался класс тональности, которому принадлежало наибольшее количество предложений отзыва. В случае равенства количества предложений в каждом классе отзыву присваивался класс последнего предложения. Если ни одному из предложений не был присвоен класс тональности, то отзыву присваивалась позитивная тональность.
2. Словари и морфологическая обработка.
Использовались два словаря: статистический и экспертный. При составлении статистического словаря каждое слово текстов обучающей коллекции взвешивалось с помощью функции отношения шансов OR (Odds Ratio) [2]. Слова сортировались по убыванию весов. В словарь добавлялось по 30 % слов с наибольшим весом из каждого класса тональности. В качестве экспертного словаря использовался словарь оценочной лексики, отдельный для каждой предметной области [5]. Информация о размерах словарей представлена в табл. 2. На этапе предварительной обработки каждое слово отзыва преобразовывалось к начальной форме при помощи морфологического анализатора Mystem от компании Яндекс.
Таблица 2
Размер словарей, слов
|
Словарь |
Предметная область |
||
|
Камеры |
Книги |
Фильмы |
|
|
Статистический |
5 888 |
9 565 |
15 413 |
|
Экспертный |
1 224 |
2 124 |
2 384 |
3. Построение моделей текста.
При реализации векторной модели каждый текст представлялся в виде бинарного вектора признаков, в качестве которых использовались уникальные слова. При реализации графовой модели каждый текст представлялся в виде неориентированного графа. Сканирование текста осуществлялось окном размером пять слов. Данный размер окна оказался оптимальным по качеству классификации и времени работы программы при проведении предварительных экспериментов.
Качество классификации оценивалось с помощью F1-меры [6]. Для получения объективных оценок применялась процедура пятикратного скользящего контроля, которая заключается в разбиении обучающей коллекции на пять равных частей и объявлении поочередно каждой из частей в качестве тестовой, остальных – в качестве обучающих.
4. Функции разрешения конфликтов.
Разрешение конфликтов гипотез осуществлялось с помощью функций из [2]. Наилучшие результаты по F1-мере получены с помощью следующих функций:
1) отношение шансов (Odds Ratio, OR):
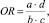 (1)
(1)
где a – количество документов позитивного класса, содержащих гипотезу h; b – количество документов позитивного класса, не содержащих гипотезу h; c – количество документов негативного класса, содержащих гипотезу h; d – количество документов негативного класса, не содержащих гипотезу h;
2) релевантная частота (Relevance Frequency, RF):
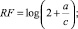 (2)
(2)
3) произведение количества терминов в гипотезе t на значение функции OR (t·OR).
В качестве терминов в исследовании рассматривались отдельные слова.
Результаты экспериментов
Эксперименты проводились при объединении статистического и экспертного словарей, что обеспечивает совместное использование статистической информации о текстах и экспертных знаний в предметной области. Результаты по количеству гипотез представлены в табл. 3, по качеству классификации – в табл. 4.
Использование модели представления текстов в виде графа по сравнению с векторной моделью привело к сокращению количества гипотез от 25 до 43 %. Это объясняется уменьшением количества допустимых связей между словами за счет использования окна фиксированного размера, что приводит к уменьшению количества возможных комбинаций слов в гипотезах. Качество классификации текстов для наилучшей функции OR изменилось от –1,2 до 0,4 %. Наличие информации в виде связей между словами привело к сокращению количества гипотез, обеспечив сохранение качества классификации на приемлемом уровне.
Анализ множеств гипотез для каждой из рассматриваемых моделей представления текстов показал, что данные множества различны и одно из них не является подмножеством другого: имеются как одинаковые гипотезы, так и разные. Многие гипотезы в векторной модели состоят из слов, не имеющих логической связи между собою. Напротив, многие гипотезы в графовой модели представляют собой словосочетания из семантически связанных слов. Среднее расстояние между двумя наиболее удаленными друг от друга словами гипотезы, полученной пересечением двух и более текстов, для векторной модели составляет 8,3 слов, для графовой – 2,1 слова. В табл. 5 приведен пример гипотез, состоящих из семантически связанных и семантически не связанных слов для конкретного отзыва.
Таблица 3
Количество гипотез
|
Гипотезы |
Камеры |
Книги |
Фильмы |
|||
|
Вектор. модель |
Граф. модель |
Вектор. модель |
Граф. модель |
Вектор. модель |
Граф. модель |
|
|
Позитивные |
37 499 |
20 318 |
15 915 |
11 837 |
35 394 |
19 781 |
|
Негативные |
28 402 |
17 218 |
15 836 |
11 836 |
26 647 |
17 184 |
Таблица 4
Значения F1-меры, %
|
Функция разрешения конфликтов |
Камеры |
Книги |
Фильмы |
Среднее |
||||
|
Вектор. модель |
Граф. модель |
Вектор. модель |
Граф. модель |
Вектор. модель |
Граф. модель |
Вектор. модель |
Граф. модель |
|
|
OR |
80,2 |
80,2 |
72,1 |
72,5 |
64,1 |
62,9 |
72,1 |
71,9 |
|
RF |
78,5 |
78,8 |
70,0 |
70,1 |
58,7 |
58,7 |
69,1 |
69,2 |
|
t·OR |
79,6 |
77,9 |
71,1 |
69,0 |
63,5 |
61,1 |
71,4 |
69,3 |
Таблица 5
Примеры гипотез из семантически связанных и семантически не связанных слов
|
Отзыв |
Модель представления текста |
|
|
векторная |
графовая |
|
|
«Мне фильм абсолютно не понравился, напомнил картину «Код да Винчи»: когда герои каждую секунду открывают потайные двери, обнаруживают загадки, и на месте их сразу же отгадывают» |
Семантически связанные: фильм, не понравиться фильм, напоминать картина, напоминать герой, секунда картина, фильм дверь, герой Семантически не связанные: место, обнаруживать место, фильм, герой место, секунда загадка, фильм картина, место дверь, фильм герой, напоминать обнаруживать, фильм |
Семантически связанные: фильм, не понравиться фильм, напоминать картина, напоминать герой, секунда Семантически не связанные: место, обнаруживать |
Вследствие того, что мощность множества гипотез в векторной модели больше мощности множества гипотез в графовой модели, в первом случае в процессе выполнения процедуры аналогии ДСМ-метод находит большее количество гипотез в классифицируемых текстах, чем во втором случае. Однако достаточно часто метод в обоих случаях присваивает тексту одинаковый класс тональности. Среднее количество одинаково классифицированных текстов для функции OR изменяется от 92 до 96 % в зависимости от предметной области.
Сравнительный анализ использования векторных и графовых моделей в задаче классификации текстов по тональности на основе ДСМ-метода выявил в случае графовой модели существенное уменьшение количества гипотез и, соответственно, времени их обработки, при сохранении качества классификации на приемлемом уровне. Данная модель позволила исключить многие гипотезы, состоящие из слов, взятых из разного контекста.
Заключение
В работе проведен сравнительный анализ векторной и графовой моделей представления текстов в задаче классификации отзывов по тональности с использованием ДСМ-метода. Графовое представление текстов позволило получить более качественные по смысловому содержанию гипотезы при выполнении процедуры индукции за счет наличия информации о структуре текста. При этом меньшего количества графовых гипотез оказалось достаточным для достижения качества классификации отзывов, сопоставимого с качеством классификации в случае использования векторных гипотез.
Работа выполнена в рамках государственного задания Минобрнауки РФ, проект № 586.
Рецензенты:
Страбыкин Д.А., д.т.н., профессор, заведующий кафедрой электронных вычислительных машин, Вятский государственный университет, г. Киров;
Прозоров Д.Е., д.т.н., профессор кафедры радиоэлектронных средств, Вятский государственный университет, г. Киров.
Библиографическая ссылка
Вычегжанин С.В., Котельников Е.В. АНАЛИЗ ВЛИЯНИЯ МОДЕЛЕЙ ПРЕДСТАВЛЕНИЯ ТЕКСТОВ НА КАЧЕСТВО КЛАССИФИКАЦИИ ОТЗЫВОВ ПО ТОНАЛЬНОСТИ // Фундаментальные исследования. 2015. № 11-2. С. 247-251;URL: https://fundamental-research.ru/en/article/view?id=39319 (дата обращения: 16.07.2026).