


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
RETRIEVAL AND RANKING OF DOCUMENTS USING MULTI-AGENT SYSTEM

Основная задача информационного поиска – нахождение максимального количества документов, релевантных информационным потребностям пользователя. Однако количество документов, содержащих ключевые слова, может быть велико и будет увеличиваться с увеличением общего количества документов в сети Интернет. Следовательно, ранжирование документов по степени их релевантности является актуальным сейчас и сохранит свою актуальность в будущем.
Подавляющее множество документов в сети содержит неструктурированную информацию, а потому выявление степени соответствия документа запросу – задача нетривиальная и предполагает использование интеллектуальных методов. В настоящее время разработано большое количество методов, в том числе интеллектуальных, оценки релевантности результатов информационного поиска [4, 5]. Однако эти методы имеют большую вычислительную сложность, а потому малоприменимы при большом количестве полученных результатов.
В настоящей работе для реализации системы используется мультиагентный подход, при котором запрашиваемые действия выполняются некоторым количеством отдельно функционирующих агентов. Подход обеспечивает не только снижение сложности системы, но и возможность распараллеливания процесса поиска для сокращения времени обработки запроса.
Целью настоящего исследования является ранжирование извлеченных неструктурных документов по увеличению их релевантности исходному поисковому запросу в рамках мультиагентной интеллектуальной системы информационного поиска.
Построение модели мультиагентной интеллектуальной системы информационного поиска
Мультиагентный подход эффективен в том случае, если структура системы и взаимодействие между объектами хорошо проработаны. Рассмотрим функции, которые должна выполнять интеллектуальная система информационного поиска.
Система, предназначенная для осуществления автоматического информационного поиска, должна реализовать пять основных этапов обработки:
● ввод ключевых слов;
● поиск в Интернете по ключевому слову;
● извлечение требуемой информации из Веб-источников;
● интеллектуальный анализ добытых текстов;
● сохранение выходных данных в базе данных [1].
Эти действия могут осуществляться пятью агентами: интерфейсным, поисковым, агентом извлечения информации, агентом интеллектуальной обработки текстов и агентом ранжирования документов. В соответствии с мультиагентной технологией все агенты общаются друг с другом с помощью сообщений. Использование ограниченного количества агентов, выполняющих не сильно связанные операции, позволяет сократить количество передаваемой между ними информации и, следовательно, уменьшить суммарное время поиска релевантных запросу документов.
Первый агент – интерфейсный – обеспечивает интерфейс пользователя, позволяющий взаимодействовать с системой через графические тексто-ориентированные интерфейсы путем ввода ключевого слова.
Второй агент – поисковый – отправляет ключевое слово в поисковую машину Google, которая возвращает ссылки, собирая URL доступных веб-сайтов в Интернете, и передает их третьему агенту.
Третий агент – извлечения информации – автоматически извлекает тексты по URL-ссылкам, в том числе большое количество различных неструктурированных текстовых ресурсов, и передает их для дальнейшей обработки.
Четвертый агент – интеллектуальной обработки текстов – извлекает полезную информацию из текста, используя лексемизацию (удаление знаков препинания, специальных символов и замену отступов и других нетекстовых символов одним пробелом) и фильтрацию стоповых слов (удаление слов, которые не относятся к документам). А также вычисляет веса терминов в документах (TF-IDF) [1] для дальнейшей оценки степени релевантности документа.
И, наконец, пятый агент выполняет операцию ранжирования документов, используя для оценки соответствия документа запросу системы нечеткого вывода Мамдани и Сугено.
Поскольку агент может выполнять более чем одну операцию, модель, представляющая процесс поиска, должна быть иерархической (двухуровневой). В качестве такой модели будем использовать нечеткий метаграф, который также позволит отобразить нечеткую характеристику соответствия документа запросу.
Метаграф представляет собой иерархическую структуру, основанную на графе, в которой каждый узел является множеством, имеющим один или более элементов. Эта модель сохраняет все свойства графов [2–3, 6–7].
Структура нечеткого метаграфа 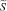 , представляющего собой модель процесса поиска, описывается следующим образом:
, представляющего собой модель процесса поиска, описывается следующим образом:
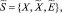
где 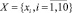 – множество операций, осуществляемых в процессе поиска и интеллектуальной обработки документов;
– множество операций, осуществляемых в процессе поиска и интеллектуальной обработки документов; 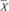 – нечеткое множество на X – множество операций, осуществляемых в процессе поиска и интеллектуальной обработки документов с учетом неопределенности
– нечеткое множество на X – множество операций, осуществляемых в процессе поиска и интеллектуальной обработки документов с учетом неопределенности 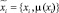 , где μ – функция принадлежности,
, где μ – функция принадлежности, 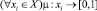 (таблица);
(таблица); 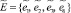 – множество сообщений, передаваемых между агентами:
– множество сообщений, передаваемых между агентами:
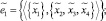
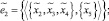
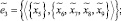
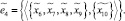
Каждому агенту в модели соответствует подмножество операций, которые он выполняет:
● интерфейсному агенту – 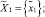
● поисковому агенту – 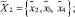
● агенту извлечения документов – 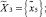
● агенту интеллектуальной обработки текстов – 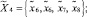
● агенту ранжирования результатов поиска – 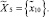
Полученный нечеткий метаграф мультиагентной системы информационного поиска показан на рис. 1.
Условные обозначения элементарных операций поиска
|
Элемент множества |
Обозначение |
Моделируемая операция |
|
|
UI |
Ввод ключевого словосочетания через интерфейс пользователя |
|
|
GIS |
Передача ключевого сочетания Google |
|
|
CURL |
Получение ссылок на документы |
|
|
SURL |
Сохранение ссылок |
|
|
RD |
Извлечение документов по ссылке |
|
|
DT |
Лексемизация текста документа |
|
|
DF |
Фильтрация текста документа |
|
|
DS |
Выделение частей речи в тексте документа |
|
|
TW |
Вычисление веса каждого термина в документе |
|
|
OE |
Оценка соответствия документа ключевым словам |

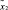
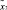
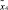
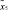
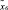
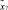
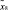
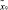
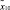
Мультиагентная система, построенная по указанной модели, включает систему принятия решения о степени соответствия документа запросу.
Система принятия решений о степени соответствия документа запросу
В основу системы принятия решения о степени соответствия документа запросу, включенной в агент 5, положены системы нечеткого вывода Мамдани и Сугено. Исходными данными для систем нечеткого вывода являются оценки весов соответствия для каждого термина запроса и для каждого документа из найденных [1], рассчитанные агентом 4. Применение при этом интеллектуальной обработки текстов позволяет получить более точные оценки весов терминов.
Правила для систем нечеткого вывода автоматически формируются в процессе поиска с использованием модели процесса интеллектуального поиска – нечеткого метаграфа. Количество правил зависит от количества терминов в запросе.
Для получения интегрированной оценки степени релевантности документа di запросу q в эксперименте используем косинусную меру оценки сходства, описанную в [5]:
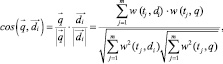
где w(tj, di) – вес j-го термина в i-м документе di; w(tj, q) – вес j-го термина в запросе q.
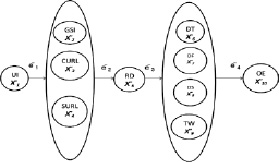
Рис. 1. Структура процесса интеллектуального информационного поиска в виде нечеткого метаграфа
Выбор этой меры обусловлен ее сравнительной простотой, что позволяет применять ее совместно с системами нечеткого вывода.
Экспериментальные исследования применения систем нечеткого вывода Мамдани и Сугено для получения оценок степени релевантности найденных документов запросу
Вычислительный эксперимент был проведен на наборе документов, извлеченных мультиагентной системой по ключевому словосочетанию «Компьютерные науки».
Таким образом, вектор запроса q = (tj),  включал два термина (m = 2):
включал два термина (m = 2):
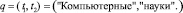 .
.
С помощью мультиагентной системы было получено множество D документов (примерно 1,5 млн), содержащих заданные термины. Для каждого документа di ∈ D в системе были определены веса терминов t1 и t2 – w(t1, di) и w(t2, di). Веса тех же терминов в запросе были приняты одинаковыми: w(t1, q) = 0,7, w(t2, q) = 0,7.
В системах нечеткого вывода Мамдани и Сугено были использованы правила:
1. Если (w (t1, q) – высокое) и (w(t1, di) – высокое), то (cos (q, di) – высокая оценка).
2. Если (w(t1, q) – низкое) и (w(t1,di) – низкое), то (cos (q, di) – низкая оценка).
3. Если (w(t2, q) – высокое) и (w(t2, di) – высокое), то (cos (q, di) – высокая оценка).
4. Если (w(t2, q) – низкое) и (w(t2, di) – низкое), то (cos(q, di) – низкая оценка).
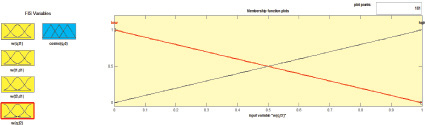
Рис. 2. Функция принадлежности входа w(t2, q)
а б

в г
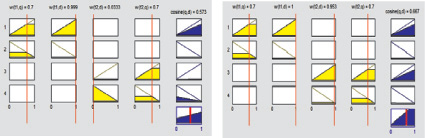
Рис. 3. Результаты оценки соответствия документа запросу с использованием системы нечеткого вывода Мамдани: a – оценка для наименее соответствующего документа; б – оценка для наиболее соответствующего документа; в–г – распределение оценок для 35 документов по терминам t1 и t2
В процессе нечеткого вывода типа Мамдани для входных лингвистических переменных w(t1, q), w(t2, q), w(t1, di) и w(t2, di) использовались треугольные функции принадлежности, как показано в примере на рис. 2 (форма функции показана в нотации пакета MATLAB).
В эксперименте с применением системы нечеткого вывода типа Мамдани веса терминов, полученные после интеллектуальной обработки текстов документов, пересчитывались с использованием треугольной функции принадлежности и приведенных выше правил. Далее были рассмотрены первые 35 документов. Расчет балла соответствия для документа, наименее соответствующего запросу из первых 35, показан на рис. 3, а (значение центроида 0,573).
Расчет балла соответствия для документа, наиболее соответствующего запросу, показан на рис. 3, б (значение центроида 0,666). Оценки балла соответствия для остальных 33-х документов распределены в диапазоне значений равном 0,093. Графически распределение результатов вычисления косинусного сходства для 35 документов по двум терминам «Компьютерная», «наука», показаны на рис. 3, в–г.
Во втором эксперименте применялась система нечеткого вывода Сугено. Также были рассмотрены первые 35 документов. Расчет балла соответствия для документа, наименее соответствующего запросу, показан на рис. 4, а (значение центроида 0,714). Расчет балла соответствия для документа, наиболее соответствующего запросу, показан на рис. 4, б (значение центроида 0,999). Оценки балла соответствия для остальных 33-х документов распределены в диапазоне значений равном 0,285, что примерно в 3 раза больше, чем в предыдущем эксперименте. Графически распределение результатов вычисления косинусного сходства для 35 документов по двум терминам «Компьютерная», «наука» показаны на рис. 4, в–г.
Выполненные эксперименты позволяют сделать вывод, что для оценки балла ранжирования документа с использованием метода сходства (косинус) можно использовать оба типа систем нечеткого вывода. Однако система нечеткого вывода Сугено обеспечивает лучшие результаты, чем система Мамдани, поскольку обеспечивает оценку, близкую к оценкам, получаемым аналитическими способами с существенно большей вычислительной сложностью [4, 5].

а б

в г
Рис. 4. Результаты оценки соответствия документа запросу с использованием системы нечеткого вывода Сугено: a – оценка для наименее соответствующего документа; б – оценка для наиболее соответствующего документа; в–г – распределение оценок для 35 документов по терминам t1 и t2
Выводы
Выполнена декомпозиция интеллектуальной поисковой системы для мультиагентной реализации по принципу выделения обобщенных операций, что позволяет сократить объем информации, передаваемой агентами в процессе работы. Для описания структуры поиска построен нечеткий метаграф, который учитывает неопределенность оценки соответствия результатов поиска введенным ключевым словам.
Для получения оценки соответствия документа запросу в условиях неопределенности исходных оценок соответствия предложено использовать системы нечеткого логического вывода Мамдани и Сугено и косинусную меру оценки сходства. Выполненные эксперименты позволяют сделать вывод, что для ранжирования найденных документов целесообразно использовать систему нечеткого вывода Сугено, которая обеспечивает оценку, близкую к оценкам, получаемым аналитическими способами, с существенно меньшей вычислительной сложностью.
Рецензенты:
Черненький В.М., д.т.н., профессор, заведующий кафедрой «Системы обработки информации и управления», Московский государственный технический университет им. Н.Э. Баумана, г. Москва;
Карпенко А.П., д.ф.-м.н., профессор, заведующий кафедрой «Системы автоматизированного проектирования», Московский государственный технический университет им. Н.Э. Баумана, г. Москва.
Библиографическая ссылка
Иванова Г.С., Андреев А.М., Шоуман М.А. ПОИСК И РАНЖИРОВАНИЕ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МУЛЬТИАГЕНТНОЙ СИСТЕМЫ // Фундаментальные исследования. 2015. № 10-3. С. 489-494;URL: https://fundamental-research.ru/en/article/view?id=39243 (дата обращения: 31.07.2026).
DOI: https://doi.org/10.17513/fr.39243