


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
INVESTIGATION OF THE EFFECT OF MULTIDIMENSIONAL DATA TO ASSESSMENT COMPETENCE USING IRT-MODELS

Одним из условий применения IRT-моделей является необходимость соблюдения условия «одномерности» используемых эмпирических данных – ответы на задания конструкта должны зависеть только от одной латентной переменной (параметра). Но, несмотря на кажущуюся простоту, данное условие трудновыполнимо. Например, даже ответ на такой простой вопрос «сколько будет 2 + 2?» обусловлен не только умением складывать числа, но и рядом других латентных параметров: умением читать, знанием цифр и пр. Поэтому в настоящий момент считается, что если задание диагностирует исследуемый латентный параметр (главный), влияние других незначительно, задание удовлетворяет статистическим проверкам на соответствие [9], то его можно использовать для оценки латентного параметра. Однако некоторые теоретические исследования показывают, что игнорирование условия одномерности, а также локально-зависимых заданий [15] в ряде случаях приводит к необъективному оцениванию [14] либо к завышению надежности набора заданий (конструкта) [13].
В работе [2] рассматривается применение IRT-моделей для оценки компетенций студентов вузов. Базовая модель для оценки компетенций (латентная модель экзаменационных заданий, mRSM) формулируется в следующем виде [1]:
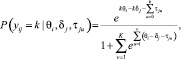 (1)
(1)
где yij – ответ, который дал i-й студент на j-е задание, 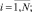
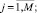 N – количество студентов; M – количество заданий; θi – латентный параметр (компетентность) i-го студента; τju – параметр (сложность категории) «шага» шкалы оценки по каждому экзаменационному заданию j; δj – параметр задания; k – оценка за задание; K – максимальная оценка.
N – количество студентов; M – количество заданий; θi – латентный параметр (компетентность) i-го студента; τju – параметр (сложность категории) «шага» шкалы оценки по каждому экзаменационному заданию j; δj – параметр задания; k – оценка за задание; K – максимальная оценка.
Исходными данными являются оценки за ответы на выполненные экзаменационные задания. Экзаменационное задание по своей природе является собирательным, поэтому возникает вопрос об исследовании влияния множества компетенций на полученную экзаменационную оценку. Для этого можно использовать подход, рассмотренный в работах [6, 8], суть которого заключается в добавлении к исследуемой модели дополнительного параметра для учета влияния других латентных переменных – γ. Тогда модель (1) можно записать в следующем виде (TmRSM):
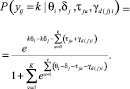 (2)
(2)
Однако при использовании модели (2) возникают три существенные сложности:
1) увеличение числа параметров приводит к увеличению вычислительной сложности алгоритма;
2) использование большого числа параметров в некоторых случаях может не только не привести к повышению согласия эмпирических данных и модели, но и ухудшить его;
3) возрастает «сложность» задания исходных данных и интерпретации результатов. Поэтому задача определения «границ» использования одномерной модели является важной и зачастую определяющей для успешного применения модели в практической деятельности.
План исследования
Для анализа используются эмпирические данные об оценках студентов направления подготовки «Прикладная информатика», профиль подготовки «Информационные системы и технологии в управлении», квалификация (степень) бакалавр.
Статистический анализ применимости моделей проводится с использованием fit-статистик Infit, OutFit, InFit(t), OutFit(t) – считается, что следует использовать задания, у которых значения Infit и OutFit находятся в диапазоне 0,4–1,6, а InFit(t) и OutFit(t): –2,5...+2,5 [9].
Для сравнения моделей между собой использован ряд критериев, связанных с понятием информационной энтропии и расстоянием Кульбака – Лейблера [7]. При применении критериев лучшей считается модель, в достаточной мере полно описывающая данные с наименьшим количеством параметров. В работе использованы критерии Акаике, Байесовский и их модификации: состоятельный критерий Акаике, скорректированный критерий Акаике и скорректированный Байесовский критерий [4, 12] (табл. 1).
Также для сравнения можно использовать информационную функцию, введенную А. Бирнбаумом. По одному из определений, количество информации, обеспеченное j-м заданием в конкретной точке θ, – это величина, обратно пропорциональная стандартной ошибке измерения данного значения θ с помощью задания j [3]. Информационная функция задания показывает соответствие количества информации, получаемой при оценивании параметра θ с помощью задания j и может быть выражена следующей формулой:
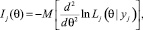 (3)
(3)
где 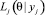 – есть функция правдоподобия задания j.
– есть функция правдоподобия задания j.
Таблица 1
Информационные критерии
|
Информационный критерий |
Формула |
|
Акаике (AIC) |
|
|
Скорректированный Акаике (AICc) |
|
|
Байесовский (BIC) |
|
|
Скорректированный Байесовский (aBIC) |
|
|
Состоятельный Акаике (CAIC) |
|
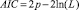
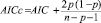
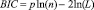
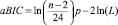
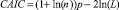
где p – количество оцениваемых параметров модели; L – максимизированное значение функции правдоподобия, n – размер выборки.
Значения этой функции являются своеобразной характеристикой эффективности j-го задания: чем больше количество информации, тем лучше, образно говоря, работает задание на рассматриваемом интервале оси θ. Информация, полученная при измерении данного θ с помощью всего конструкта, складывается из отдельных значений ординат информационных функций, построенных для каждого задания [5]:
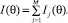 (4)
(4)
Оценка параметров моделей, расчеты статистик и значений критериев производились с помощью программы, написанной на языке R [11].
Результаты исследования и их обсуждение
Рассмотрим компетенцию ПК-1. Определены 8 экзаменационных заданий, которые сформировали конструкт для оценки компетенции: правоведение, основы бизнеса, информационная безопасность, проектирование информационных систем, предметно-ориентированные экономические информационные системы, защита информации в банках, автоматизированные банковские системы, налогообложение. Дополнительно построена матрица (табл. 2), в которой цифрой 1 обозначены компетенции, влияющие на оценку соответствующего задания.
В табл. 3 приведены значения статистик параметров моделей, рассчитанные по экзаменационным оценкам.
Таблица 2
Матрица влияния компетенций на экзаменационные задания конструкта
|
Задание |
ПК-1 |
ПК-2 |
ПК-4 |
ПК-5 |
ПК-6 |
ПК-8 |
ПК-11 |
ПК-13 |
ПК-14 |
ПК-15 |
ПК-18 |
ПК-19 |
ПК-22 |
|
1 |
1 |
1 |
1 |
||||||||||
|
2 |
1 |
||||||||||||
|
3 |
1 |
||||||||||||
|
4 |
1 |
1 |
1 |
1 |
1 |
||||||||
|
5 |
1 |
1 |
1 |
1 |
1 |
||||||||
|
6 |
1 |
1 |
1 |
1 |
|||||||||
|
7 |
1 |
1 |
1 |
1 |
1 |
1 |
|||||||
|
8 |
1 |
1 |
Таблица 3
Значения fit-статистик
|
Экзаменационное задание |
Значения статистик |
||||||||
|
mRSM |
TmRSM |
||||||||
|
Наименование |
Параметр |
Outfit |
Outfit (t) |
Infit |
Infit (t) |
Outfit |
Outfit (t) |
Infit |
Infit (t) |
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Правоведение |
δ1 |
0,99 |
–0,04 |
1,01 |
0,09 |
0,85 |
–0,92 |
0,93 |
–0,58 |
|
τ11 |
1,54 |
1,61 |
1,03 |
0,31 |
0,89 |
–0,05 |
0,90 |
–0,88 |
|
|
τ12 |
0,85 |
–1,24 |
0,91 |
–1,74 |
0,88 |
–0,90 |
0,96 |
–0,83 |
|
|
Основы бизнеса |
δ2 |
0,86 |
–0,89 |
0,90 |
–0,75 |
0,67 |
–2,17 |
0,76 |
–2,14 |
|
τ21 |
1,08 |
0,40 |
0,92 |
–0,57 |
0,84 |
–0,55 |
0,87 |
–0,92 |
|
|
τ22 |
0,82 |
–0,71 |
0,91 |
–1,18 |
1,02 |
0,15 |
0,94 |
–0,73 |
|
|
Информационная безопасность |
δ3 |
1,41 |
2,24 |
1,23 |
1,80 |
1,69 |
3,91 |
1,49 |
3,44 |
|
τ31 |
1,70 |
1,58 |
1,31 |
1,80 |
1,78 |
1,79 |
1,22 |
1,32 |
|
|
τ32 |
1,39 |
1,32 |
1,11 |
1,21 |
1,12 |
0,55 |
1,08 |
0,91 |
|
|
Проектирование информационных систем |
δ4 |
0,76 |
–1,10 |
0,77 |
–2,06 |
0,81 |
–1,67 |
0,82 |
–1,54 |
|
τ41 |
0,73 |
–1,21 |
0,80 |
–1,35 |
0,80 |
–0,93 |
0,82 |
–1,32 |
|
|
τ42 |
0,87 |
–0,54 |
0,90 |
–1,75 |
0,91 |
–0,25 |
0,97 |
–0,57 |
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Предметно-ориентированные экономические информационные системы |
δ5 |
0,96 |
–0,18 |
1,00 |
0,06 |
0,89 |
–0,53 |
0,97 |
–0,18 |
|
τ51 |
0,92 |
–0,41 |
0,98 |
–0,22 |
0,83 |
–1,04 |
0,93 |
–0,69 |
|
|
τ52 |
0,87 |
–0,80 |
0,96 |
–0,69 |
0,95 |
–0,23 |
1,03 |
0,54 |
|
|
Защита информации в банках |
δ6 |
1,50 |
2,42 |
1,41 |
2,28 |
1,44 |
2,21 |
1,42 |
2,37 |
|
τ61 |
1,70 |
1,52 |
1,36 |
1,41 |
1,48 |
1,16 |
1,35 |
1,47 |
|
|
τ62 |
1,28 |
1,36 |
1,16 |
1,64 |
1,26 |
1,26 |
1,13 |
1,35 |
|
|
Автоматизированные банковские системы |
δ7 |
1,06 |
0,42 |
1,12 |
0,87 |
1,24 |
1,34 |
1,17 |
1,16 |
|
τ71 |
0,70 |
–1,87 |
0,74 |
–2,29 |
0,97 |
–0,14 |
0,95 |
–0,32 |
|
|
τ72 |
1,04 |
0,27 |
0,99 |
–0,05 |
0,97 |
–0,06 |
1,05 |
0,63 |
|
|
Налогообложение |
δ8 |
0,97 |
–0,17 |
1,00 |
0,03 |
0,98 |
–0,06 |
0,96 |
–0,25 |
|
τ81 |
0,76 |
–0,80 |
1,06 |
0,45 |
1,00 |
0,09 |
1,01 |
0,08 |
|
|
τ82 |
0,91 |
–0,29 |
0,95 |
–0,59 |
1,36 |
1,35 |
1,03 |
0,36 |
|
Анализируя таблицу, видно, что в целом обе модели достаточно хорошо описывают эмпирические данные, превышения значений статистик для некоторых параметров объясняются влиянием многомерности, к чему особенно чувствительна Outfit-статистика.
В табл. 4 приведены значения информационных критериев – мер относительно качества моделей, учитывающих степень «подгонки» модели под данные с корректировкой (штрафом) на используемое количество оцениваемых параметров.
Даже если исключить из рассмотрения AICc, который накладывает очень большой штраф на количество параметров, все равно увеличение количества параметров является очень существенным и сказывается на значениях всех прочих информационных критериев, согласно которым следует выбрать mRSM.
На рис. 1 в графическом виде представлены оценки компетенций студентов в логитах, рассчитанные по двум моделям.
Таблица 4
Значения информационных критериев
|
Информационный критерий |
TmRSM |
mRSM |
|
Акаике (AIC) |
1964,5 |
1775,37 |
|
Скорректированный Акаике (AICc) |
4187,83 |
1788,12 |
|
Байесовский (BIC) |
2292,48 |
1846,67 |
|
Скорректированный Байесовский (aBIC) |
1925,19 |
1766,83 |
|
Состоятельный Акаике (CAIC) |
2407,48 |
1871,67 |
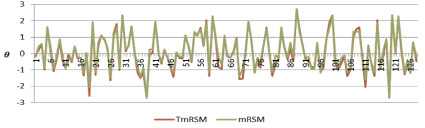
Рис. 1. График оценок компетенций студентов
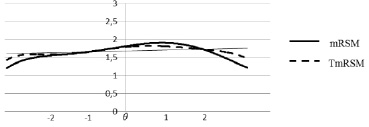
Рис. 2. Графики информационных функций конструкта
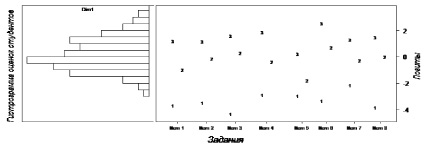
Рис. 3. Карта Райта
Абсолютная максимальная разница в оценках составила 0,6 логита, средняя разница – 0,13 логита, наибольшая разница проявляется на концах шкалы, при оценке θ в диапазоне (–1,5; +1,5) логита разница не превышает среднюю. Корреляция оценок – 0,99. В подавляющем большинстве случаев разница в оценке не превышает среднюю ошибку вычисления. На рис. 2 представлены графики информационных функций конструкта.
Для обеих моделей информационные функции имеют один выраженный максимум, что говорит о хорошем качестве конструкта. Сравнивая точности измерения компетенций, можно отметить, что у mRSM наибольшая точность достигается в диапазоне (примерно) θ ∈ (–0,5; +2), в диапазоне θ ∈ (–1,2; +0,5) точности равны, а по краям шкалы TmRSM показывает большую точность измерения. Однако данные различия не являются значительными, и в общем случае нельзя сделать однозначный вывод о том, какой модели следует отдать предпочтение. На рис. 3 представлена карта Райта для набора заданий оценки компетенции ПК-1. Оценки большинства студентов находятся в диапазоне (–2; +2) логита, где по точности mRSM не уступает TmRSM.
Результаты расчётов и анализа по остальным компетенциям ФГОС «Прикладная информатика» аналогичны приведённым для компетенции ПК-1.
Выводы
В статье с практической точки зрения рассмотрена проблема игнорирования условия одномерности при использовании одномерной IRT-модели оценки компетенции. Проведено сравнение одномерной модели mRSM с многомерной TmRSM, учитывающей влияние нескольких латентных переменных – компетенций. Проведенные расчеты показывают, что TmRSM в некоторых случаях более точно позволяет оценить компетенции, особенно у студентов с низким и/или высоким уровнем освоения компетенции, однако для студентов со средним уровнем освоения компетенции (а таких большинство) более предпочтительной является одномерная модель. Оценки компетенций студентов, полученные по mRSM и TmRSM, обладают очень высоким коэффициентом корреляции – минимальное значение 0,985 (по компетенции ПК-15), а абсолютная разница оценок в 96 % случаев не превышает ошибку измерения. Разумеется, нельзя не списывать со счетов и размер выборки – расчеты, проведенные на имитационных данных, например в работе [10], показывают, что с увеличением объема выборки расхождение в оценках параметров моделей растет. Но при небольшом и среднем размере выборки применение одномерной модели не приводит к существенному ухудшению точности оценки. В совокупности с усложнением процедуры оценки и алгоритмов расчетов TmRSM использование одномерной модели для практического применения следует считать допустимым.
Рецензенты:
Пархомов В.А., д.ф.-м.н., профессор кафедры информатики и кибернетики, ФГБОУ ВПО «Байкальский государственный университет экономики и права», г. Иркутск;
Боровский А.В., д.ф.-м.н., профессор кафедры информатики и кибернетики, ФГБОУ ВПО «Байкальский государственный университет экономики и права», г. Иркутск.
Библиографическая ссылка
Родионов А.В. ИССЛЕДОВАНИЕ ВЛИЯНИЯ МНОГОМЕРНОСТИ ДАННЫХ НА ОЦЕНКУ КОМПЕТЕНЦИЙ С ИСПОЛЬЗОВАНИЕМ IRT-МОДЕЛЕЙ // Фундаментальные исследования. 2015. № 10-2. С. 299-304;URL: https://fundamental-research.ru/en/article/view?id=39168 (дата обращения: 02.08.2026).