


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
AN APPROACH FOR CLUSTERING OF THE THEMATIC USER PROFILES AND ITS APPLICATION FOR INTERNET TRAFFIC ANALYSIS

В связи с интенсивным развитием телекоммуникационных технологий, увеличением скоростей передачи данных и пропускной способности каналов связи все большую актуальность приобретает задача изучения информационных потребностей пользователей.
По оценке фонда «Общественное мнение» [7] сотрудник офиса ежедневно тратит 1,5 часа рабочего времени на решение личных вопросов, общение в социальных сетях, чтение новостей, посещение развлекательных порталов и т.д. В целом такое положение дел приводит к снижению эффективности использования рабочего времени сотрудниками организации, потерям времени, связанным с нецелевым использованием ресурсов Интернет и увеличению нагрузки на каналы связи [2, 6]. Вопросы, связанные с оптимизацией потребления Интернет-трафика, и методика поэтапного сокращения затрат на Интернет-трафик и потерь рабочего времени, связанных с нецелевым использованием ресурсов сети Интернет, детально описаны в [2].
В данной статье рассмотрено применение методов интеллектуального анализа данных (data mining) для оценки эффективности использования сотрудниками организации своего рабочего времени и ресурсов сети Интернет путем построения тематических профилей пользователей, определения их информационных потребностей, а также формирования кластеров пользователей со схожими тематическими предпочтениями.
Исходными данными для анализа является информация, полученная из журнальных файлов (log-файлов) прокси-сервера [4]. Данные о каждом обращении пользователя к ресурсам Интернет обрабатываются прокси-сервером и сохраняются в виде текстового log-файла. Каждому запросу в log-файле соответствует одна строка.
Имея достаточно данных о посещенных пользователем веб-страницах, можно вполне успешно определить тематические категории, отражающие интересы и предпочтения данного пользователя, а также сделать вполне обоснованные предположения об эффективности его работы [1, 5]. Задача осложняется тем, что количество пользователей организации может исчисляться сотнями, а число посещенных ими веб-страниц – тысячами. При этом размеры сжатого дневного журнала прокси-сервера могут достигать 100 МБ и более. Для обработки и анализа таких объемов информации необходимо использовать автоматизированные методы, базирующиеся на применении машинного обучения.
Первоначальным этапом решения задачи data mining является процесс конструирования признаков (feature engineering). Это самый трудоемкий и одновременно самый ответственный этап, от которого напрямую зависит конечный результат всей работы. В нашем случае в качестве объектов выступают пользователи организации, а в качестве признаков – тематические категории посещенных ими веб-ресурсов. Такое признаковое описание позволяет формировать тематические профили пользователей. Тематический профиль пользователя – это векторное представление его интересов и тематических предпочтений, составленное на основе анализа посещенных веб-страниц. Совокупность тематических профилей пользователей образует матрицу, где каждая строка соответствует пользователю, а каждый столбец – признаку, в качестве которого выступает тематическая категория (рис. 1).
Значения признаков вычисляются исходя из частот обращения пользователя к ресурсам, входящим в каждую тематическую категорию, и объемов входящего трафика. Для улучшения качества будущей модели производят нормализацию значений признаков, приводя их к диапазону [0...1].
После окончания этапа конструирования признаков (feature engineering), как правило, производят отбор подмножества наиболее информативных и достоверных признаков для построения модели. Это позволяет снизить объемы обрабатываемой информации, избежать переобучения и в целом улучшить качество модели. В нашем случае будем группировать ресурсы по тематическим категориям, т.к. разумно предположить, что пользователи, интересующиеся одной тематикой, могут получать информацию из различных источников. Признаки, встречающиеся не более чем у одного пользователя, будем считать неинформативными.
В результате получим матрицу «пользователь/категория», состоящую только из информативных признаков. Как правило, матрица обладает большой размерностью, и при этом является разреженной (sparse matrix). Поэтому следует использовать реализации алгоритмов машинного обучения, способные работать с такими матрицами.
Для того чтобы получить первоначальное представление о кластерной структуре исследуемых данных, воспользуемся агломеративным алгоритмом иерархической кластеризации и разобьем исходное множество объектов на несколько кластеров. Для этого вычислим попарные расстояния между объектами, построив матрицу расстояний. В качестве меры расстояния воспользуемся расстоянием Евклида. На рис. 2 представлены гистограммы распределения расстояний между объектами.
Преобладание больших расстояний между объектами свидетельствует о неоднородности исследуемых данных. То есть информационные потребности пользователей в целом довольно сильно различаются.
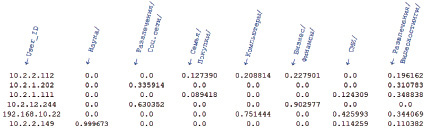
Рис. 1. Тематические профили пользователей. Векторное представление
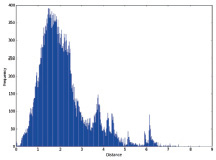
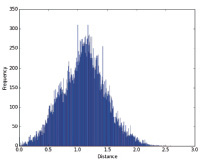
Рис. 2. Гистограммы расстояний между объектами: исходные данные без нормализации (слева), нормализованные исходные данные (справа)
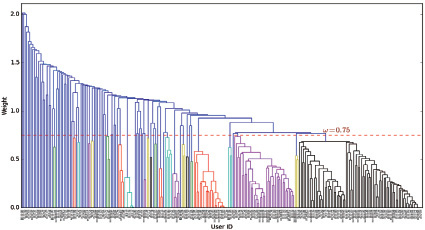
Рис. 3. Таксономия пользователей на основе анализа их тематических предпочтений. Иерархия составлена агломеративным усредняющим методом
Результаты работы алгоритма иерархической кластеризации удобно представлять графически в виде дендрограммы. При этом, как правило, задают некоторое пороговое значение уровня значимости для выделения отдельных кластеров. На рис. 3 представлена дендрограмма, изображающая кластеры, полученные при заданном пороговом значении, равном 0,75. Кластеры выделены различными цветами.
Из дендрограммы видно, что около половины объектов формируют четко выраженные кластеры. Остальная же часть объектов довольно разнородна. Это может свидетельствовать о том, что интересы и предпочтения данной части пользователей довольно индивидуальны (уникальны).
Имея представление о желаемом количестве кластеров, воспользуемся методом k-средних (k-means) [3] для проверки достоверности полученных ранее результатов и оценки их правдоподобности. Введем функционал качества кластеризации Φ0, равный сумме средних внутрикластерных расстояний [3]:
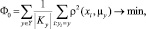 (*)
(*)
где 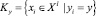 – кластер с номером y ∈ Y, Xl – множество некластеризованных объектов; µy – центры кластеров y, ρ – евклидова метрика расстояния.
– кластер с номером y ∈ Y, Xl – множество некластеризованных объектов; µy – центры кластеров y, ρ – евклидова метрика расстояния.
Экспериментируя с количеством кластеров и оценивая значения функционала качества (*), а также других статистических характеристик, таких как внутрикластерная дисперсия и стандартное отклонение, выберем наиболее подходящую модель кластеризации.
На рис. 4 представлены результаты кластеризации, полученные с помощью онлайн сервиса BigML Machine Learning Made Easy [8] для 16 кластеров.
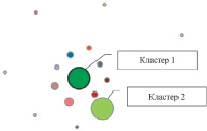
Рис. 4. Результаты работы алгоритма KMeans для 16 кластеров
Как видно из рис. 4, основная масса объектов (пользователей) разделилась на две большие группы (кластеры 1 и 2). Остальные объекты образуют мелкие кластеры. В целом такая картина подтверждает вышеописанные результаты, полученные с помощью алгоритма иерархической кластеризации.
Центры кластеров позволяют судить о признаках (рубриках), оказавших наибольшее влияние на их формирование. В частности, на формирование кластеров 1 и 2 (рис. 4) наибольшее влияние оказали рубрики «Интернет», «Социальные сети» и «Хостинги видео» соответственно. Чтобы детально оценить тематические предпочтения пользователей, входящих в эти кластеры, абстрагируемся от остальных признаков и представим объекты в виде трехмерной диаграммы, где каждая ось соответствует одному из признаков (рис. 5).
На рис. 5 видны три кластера. Пользователи кластера 1 преимущественно посещают Интернет-порталы, пользуются поисковыми системами. Пользователи кластера 2, напротив, уделяют большую часть времени просмотру видео и нахождению в социальных сетях. На предыдущем этапе с использованием метода k-means эти кластеры были объединены в один. Кластер 3 состоит из активных пользователей социальных сетей. Здесь вес остальных рубрик достаточно низкий, что вполне объяснимо, т.к. данная категория пользователей получает большую часть нужной им информации именно из социальных сетей, в том числе это касается и просмотра видео.
Говоря о нецелевом использовании ресурсов Интернет и эффективности использования рабочего времени сотрудниками, можно установить некоторый порог, поместив в начало координат сферу радиуса R. Объекты (пользователей), выходящие за границы этой сферы, будем считать расходующими ресурсы Интернет на нецелевые нужды.
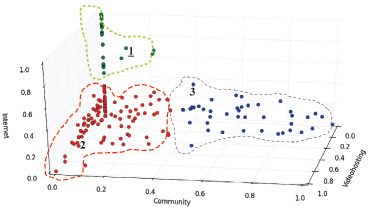
Рис. 5. Кластеры пользователей, соответствующие рубрикам «Интернет», «Соц. сети» и «Хостинги видео»
Результаты кластеризации, безусловно, зависят от многих факторов, в том числе от процесса подготовки исходных данных и выбранного метода кластеризации. Но в целом можно считать, что полученные кластеры позволяют достаточно адекватно определить предпочтения пользователей относительно выбора информационных ресурсов, просматриваемых в сети Интернет. Исследовав набор тематических категорий, оказавших наибольшее влияние на формирование кластеров, можно сделать вывод не только об информационных потребностях пользователей, но и о том, насколько эффективно сотрудники организации используют свое рабочее время.
Рецензенты:
Старовиков М.И., д.п.н., к.ф.-м.н., доцент, профессор кафедры физики и информатики, ФГБОУ ВПО «Алтайская государственная академия образования им. В.М. Шукшина», г. Бийск;
Попок Н.И., д.т.н., профессор, нач. лаборатории ОА «ФНПЦ «Алтай», г. Бийск.
Библиографическая ссылка
Паутов К.Г., Попов Ф.А. МЕТОД КЛАСТЕРИЗАЦИИ ТЕМАТИЧЕСКИХ ПРОФИЛЕЙ ПОЛЬЗОВАТЕЛЕЙ И ЕГО ПРИМЕНЕНИЕ ДЛЯ АНАЛИЗА ИНТЕРНЕТ-ТРАФИКА // Фундаментальные исследования. 2015. № 7-4. С. 765-769;URL: https://fundamental-research.ru/en/article/view?id=38817 (дата обращения: 03.08.2026).