


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
METHODOLOGICAL ASPECTS OF CONCEPTUAL ANALYSIS AND MODELING OF TEXT STRUCTURES

Важность и значимость анализа и обработки текстовых и других слабоструктурированных данных постоянно возрастает в связи с развитием глобальных информационных сетей. Все теоретические исследования последнего времени в области интеллектуального анализа текстов в той или иной степени опираются на системный подход к естественному языку. На основе системного подхода к моделированию и представлению текстовых данных были сформулированы основные теоретические положения построения систем анализа и обработки текстовых структур [6]. К таким основам относятся системное и потоковое представление текстов, теория нечеткости, теория обучающихся систем.
Как и любая модель, модели текста являются его упрощением и отражением только некоторых внутренних свойств. Принцип системного рассмотрения текста предполагает выделение множества различных отдельных характеристик или их совокупности, построение на их основе нескольких моделей текста, описывающих текст с разной степенью детализации с различных точек зрения.
Принцип нечеткой логики предполагает взаимное дополнение и пересечение построенных моделей, возможность одновременного использования нескольких из них.
Построенные системы должны соответствовать принципу обучающихся систем, согласно которому система улучшает свое функционирование на основе полученной в результате работы информации и тем самым предусматривать возможность работы в условиях неполной исходной информации. В большей степени это касается задач идентификации, поскольку при идентификации, по определению, исходят из неполной информации, и требуется по имеющимся данным выявить некоторые идентификационные признаки, по которым в дальнейшем может быть проведена идентификация объектов.
При построении систем анализа и обработки текстов возникают задачи, которые можно разделить на три большие группы: задачи кластеризации, то есть разбиение корпуса текстовых данных на отдельные кластеры (группы, классы); задачи классификации – отнесение неизвестного текста к одному из заданных классов и задачи идентификации – определение значимых признаков, структур и основных параметров текстовых данных. Такое разделение на задачи и принципы носит условный характер для большей наглядности и простоты изложения. Традиционно задачи кластеризации и классификации рассматривают в единой системе, кластеризацию данных также называют автоматической классификацией, поскольку процедура предполагает отнесение каждого объекта к конкретному классу. Методы решения задач во многом совпадают или требуют незначительной модификации, при рассмотрении задач другого типа.
В последнее время в связи с развитием вычислительной техники, увеличением ее быстродействия, появлением суперкомпьютеров, а также возникновением новых подходов к процессам обработки данных (распараллеливание задач и другие), на первый план выходит не проблема расчетов, а проблема моделирования. Причем развитие подхода к моделированию состоит не просто в усложнении моделей, а в использовании иных приемов. Модель может не быть сложной, но она должна учитывать все особенности объектов с точки зрения рассматриваемых задач. При разработке и проектировании систем анализа и обработки текстовых данных необходимо предусмотреть следующие возможности:
1. Построение совокупности моделей текстовых данных, характеризующих различные параметры текстов и отражающие особенности текстов на разных уровнях иерархической системы.
2. Реализация нескольких алгоритмических подходов для решения задач классификации, кластеризации и идентификации с возможностью их и модификаций с точки зрения быстродействия реализации и представления получаемых результатов.
3. Методика выбора из всей совокупности используемых моделей и алгоритмов необходимого подмножества, наилучшим образом отвечающего поставленным задачам.
4. Модификация отобранных моделей и алгоритмов в зависимости от целей конкретных задач и дополнительных условий (точности, времени выполнения и т.п.).
Подобные системы могут быть отнесены к системам семиотического типа [2], которые можно представить набором моделей, правилами выбора моделей и функциями модификаций отдельных моделей и системы в целом.
Методологию анализа и моделирования текстов, ее основные задачи и принципы можно представить в единой таблице, показанной на рисунке.
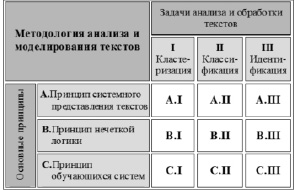
Обобщенная схема методологии анализа и моделирования текстов
I. Задачи кластеризации
A.I. Для решения задачи кластеризации на основе принципа системного представления текстов целесообразно использовать структурно ориентированные алгоритмы сжатия и понятие Колмогоровской сложности [1, 5].
В.I. Методы кластеризации на основе нечетких отношений не требуют предварительного выявления признаков текстов, при их применении может быть использован подход на основе алгоритмов сжатия. Для этого необходимо составить матрицу отношений между текстами, элементами которой могут служить степени сжатия объединенных текстов. Степень сжатия определяется с применением выбранного заранее контекстно зависимого компрессора [10].
Для решения задачи нечеткой кластеризации предложено большое количество методов, таких как Метод fuzzy c-means (FCM), Kernel Fuzzy Clustering, Метод Густафсона-Кесселя и другие [9]. Большинство этих методов предполагает векторное представление данных, поэтому для их применения необходима предварительная обработка рассматриваемых текстов и формирование признакового пространства.
С.I. Задачи кластеризации по своей сути предполагают обучение без учителя, решение задачи кластеризации на основе принципа обучающихся систем позволяет обратиться к самообучающимся методам нейросетевых технологий, например, могут быть применены самоорганизующиеся карты Кохонена [11].
II. Задачи классификации
A.II. Для решения задачи классификации по предметным областям (задачи категоризации) успешно применяется системное представление текстов, в первую очередь, векторное представление и использование N-грамм. При этом повышение эффективности различных методов классификации может быть достигнуто за счет применения расширенных моделей текста, лучше отражающих его глубинную структуру, например, таких как деревья и спектры N-грамм [4].
В.II. Существует большое число методов классификации, таких как метод опорных векторов, ближайших соседей, которые могут быть обобщены и адаптированы для случая нечеткого представления. Например, для решения задач нечеткой классификации текстов предложено использовать модификацию метода k ближайших соседей, которая предполагает вычисление степени принадлежности как отношения проголосовавших соседей за определенный класс к общему числу голосующих [12].
С.II. По многим аспектам задачи идентификации тесно связаны с задачами классификации: отнесение по некоторым данным неизвестного объекта к тому или иному классу. При этом, в зависимости от выбранного идентификационного признака, объект может быть отнесен к нескольким классам – налицо задача нечеткой классификации. Можно утверждать, что задача идентификации в смысле отнесения к группе объектов по сходству признаков является задачей нечеткой классификации.
III. Задачи идентификации
A.III. При решении задач идентификации могут быть использованы разнообразные модели текстовых структур, такие как взаимная информация, Марковская модель текста, модели, основанные на N-граммах, энтропийные характеристики вычисления символьного разнообразия [8]. Выбор модели или их совокупности зависит от целей идентификации, особенностей идентифицируемых текстов и т.п. [7].
В.III. и С.III. В задачах классификации и идентификации обычно предполагается наличие обучающих выборок, на основе которых обучается классификатор или выявляются идентификационные признаки. Использование одновременно нескольких подходов к обучению позволяет в лучшей мере определить значимые особенности данных, а также решать задачи при неполной или недостоверной исходной информации.
В таблице приведены некоторые базовые методы, использующиеся при решении основных задач обработки текстовых данных, на основе рассмотренных принципов.
Однако приведенное обобщение (рисунок) нельзя рассматривать как полное и окончательное. В дальнейшем таблица может быть расширена введением других принципов и рассмотрением новых задач. Так во многих задачах может оказаться перспективным использование знаний о предметной области, то есть применение различных онтологий и тезаурусов [3]. Другим направлением может являться развитие методов решения задач автоматического аннотирования и реферирования, которые по многим параметрам близки к задаче идентификации как к задаче выявления значимых признаков, но большая специфичность используемых приемов и техник позволяет рассматривать аннотирование и реферирование как отдельный тип задач и, соответственно, рассмотреть особенности ее решения на основе указанных принципов.
Совокупность методов анализа и обработки текстовых данных
|
Задачи. Принципы |
I Кластеризация |
II Классификация |
III Идентификация |
|
А. Принцип системного представления текстов |
AI |
AII |
АIII |
|
Сжатие для представления текстов. Методы, основанные на Колмогоровской сложности |
Векторное представление, N-граммы, деревья и спектры N-грамм. Потоковое представление |
Взаимная информация, информационные портреты. Энтропийные характеристики символьного разнообразия |
|
|
В. Принцип нечеткой логики |
ВI |
ВII |
ВIII |
|
Метод fuzzy c-means (FCM). Метод Kernel Fuzzy Clustering. Метод Густафсона-Кесселя Кластеризация на основе нечетких отношений |
Нечеткие модификации метода k ближайших соседей (k-nearest neighbor, k-NN) |
Нечеткие модификации метода k ближайших соседей (k-nearest neighbor, k-NN) |
|
|
С. Принцип обучающихся систем |
СI |
СII |
СIII |
|
Нейросетевые технологии. Технологии на основе решающих деревьев |
Метод опорных векторов. Нейросетевые технологии |
Метод опорных векторов. Нейросетевые технологии. Взаимная информация |
Предложенные методологические аспекты анализа и моделирования текстов позволяет обобщить основные принципы для решения задач анализа текстов и формализовать выбор моделей и методов обработки текстов при решении конкретных прикладных задач. Рассмотренная методология позволяет обозначить прикладные аспекты анализа и моделирования текстовых структур, а именно, в задачах нечеткой идентификации потоковых текстовых сообщений, информационно-поисковых системах и в системах, связанных с обеспечением информационной безопасности.
Рецензенты:
Баландин Д.В., д.ф.-м.н., профессор, заведующий кафедрой численного и функционального анализа, Нижегородский государственный университет им. Н.И. Лобачевского, г. Нижний Новгород;
Федосенко Ю.С., д.т.н., профессор, заведующий кафедрой «Информатики, систем управления и телекоммуникаций», Волжский государственный университет водного транспорта, г. Нижний Новгород.
Библиографическая ссылка
Ломакина Л.С., Суркова А.С. МЕТОДОЛОГИЧЕСКИЕ АСПЕКТЫ КОНЦЕПТУАЛЬНОГО АНАЛИЗА И МОДЕЛИРОВАНИЯ ТЕКСТОВЫХ СТРУКТУР // Фундаментальные исследования. 2015. № 6-3. С. 497-501;URL: https://fundamental-research.ru/en/article/view?id=38648 (дата обращения: 27.07.2026).