


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
APPROACHES TO AUTOMATE VALIDATION OF VULNERABILITIES FOUND BY AUTOMATIC SECURITY SCANNERS USING FUZZY SETS AND NEURAL NETWORKS

В настоящее время существует огромное количество различных сканеров информационной безопасности (далее – сканеры), применяемых для анализа защищенности веб-приложений: Acunetix WVS, IBM AppScan, BurpSuite, NMap, HP Fortify, Positive Technologies – MaxPatrol, XSpider, Application Inspector и других, различающихся ценой, качеством сканирования, поддерживаемыми технологиями, типами обнаруживаемых уязвимостей, методиками поиска – белый или черный ящик, и десятками других параметров. Некоторое представление о возможностях сканеров и сравнение их характеристик можно получить, например, из периодического отчета «The Web Application Vulnerability Scanners Benchmark (by Shay Chen, Information Security Researcher)» [6].
При разработке сканеров информационной безопасности важную роль играют методики тестирования их работы, о которых мы упоминали в статье «Тестирование сканеров безопасности веб-приложений: подходы и критерии» [5]. В этих методиках особое место занимает конкурентный анализ сканеров и их сравнение с другими.
Основным ожидаемым результатом работы любого сканера безопасности является список кандидатов в уязвимости, полученный в процессе анализа веб-приложения. Использование в сканерах сложных эвристических алгоритмов часто приводит к большому числу ложных срабатываний и заполнению такого списка несуществующими в реальном веб-приложении уязвимостями (false positives). В связи с чем требуется длительная работа экспертов-аналитиков в области информационной безопасности, чтобы перепроверить, подтвердить или опровергнуть найденные автоматическим сканером кандидаты в уязвимости. При этом они используют как различные инструментальные средства для попыток эксплуатации уязвимостей, так и делают выводы, опираясь на собственный опыт.
На практике, как один из способов подтверждения уязвимости, может использоваться сравнение с некоторыми аналогичными уязвимостями, о которых заранее известно, что они имеются в похожем веб-приложении или в том же веб-приложении, но более ранней версии. Для этого может быть сформирована база данных «эталонных» уязвимостей, содержащая характеристики и описание реальных, ранее найденных уязвимостей. Тогда эксперт-аналитик сможет сделать дополнительные выводы и подтвердить или опровергнуть новые кандидаты в уязвимости, опираясь на их сравнение с эталонами по некоторым правилам. Однако подобная рутинная работа также нуждается в дополнительных инструментах и процедурах, позволяющих выполнить такой анализ: сравнивать кандидаты с эталонными уязвимостями и отсеивать очевидные false positives.
Постановка задачи нечёткой классификации уязвимостей
Как отмечено выше, проблема подтверждения уязвимостей из списка кандидатов на практике может решаться как задача сравнения их с некоторыми эталонами. В случае если все объекты – и эталоны, и кандидаты в уязвимости – могут быть однозначно параметризованы, представлены в виде вектора признаков объекта, то проблема может быть сведена к классической задаче классификации элементов множества [4, п. 3].
Входные данные:
1. Задано n-мерное векторное пространство Vulners – всех уязвимостей (vulnerabilities) веб-приложений, которые могут быть заданы векторами признаками vi:
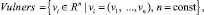
где v1, ..., vn – чёткие, либо дефазифицированные из нечётких, числовые характеристики отдельных признаков уязвимости.
Из Vulners выделено непустое конечное подмножество Candidates – кандидатов в уязвимости для некоторого веб-приложения:
Candidates ≠ Ø, Candidates ⊂ Vulners,
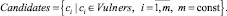
Элементы из Candidates являются объектами классификации.
2. Каждую уязвимость из Candidates допускается отнести к двум классам:
– I класс подтвержденных (verified) уязвимостей:
Ver ⊆ Candidates,
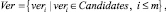
– II класс неподтвержденных (non-verified) уязвимостей:
NVer ⊂ Candidates,
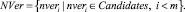
3. Существует Eth – непустое подмножество «эталонных» (ethalon) уязвимостей, входящих в I класс:
∃Eth ≠ 0, Eth ⊆ NVer,
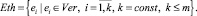
Используя элементы Eth, допускается делать предположения о принадлежности других элементов из Candidates классам Ver и NVer в виде некоторого «правила» – функции f от двух переменных, определенной на множестве Ver × Eth со значениями в Ver, то есть выполняется условие:
Ver ∪ NVer = Candidates,
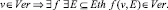
4. Задано множество измерительных шкал Scales для оценки чётких и нечётких характеристик уязвимостей:
Scales = {Sp, Sf},
где Sp – чёткая (precise) числовая шкала; Sf – нечёткая (fuzzy) шкала лингвистических переменных.
Схематично условия задачи представлены на рис. 1.
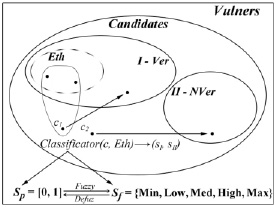
Рис. 1. Диаграмма Эйлера – Венна для задачи классификации уязвимостей
Требуется:
1. Построить отображения Fuzzy и Defuz для задачи интерпретации результатов классификации и оценок:
Fuzzy : Sp → Sf;
Defuz Sf → Sp; Sp, Sf ∈Scales,
определяющие способы представления чётких оценок в виде нечёткого значения некоторой лингвистической переменной и наоборот.
2. Построить отображение Classificator для задачи классификации:
Classificator : Candidates×Eth → Scales×Scales,
ставящее в соответствие каждой уязвимости из Candidates оценки принадлежности уязвимости каждому классу, учитывая при этом имеющиеся эталоны. Иначе говоря, нужно построить функцию
Classificator(c, Eth) → (sI, sII), c ∈ Candidates, sI, sII ∈ Sp ∨ sI, sII ∈ Sf.
Измерительные шкалы и связь между ними
Среди исследований, выполненных в работе [3], приведены примеры, показывающие, что в качестве универсальных измерительных шкал для оценки свойств информационных систем могут быть использованы:
– множество действительных чисел из отрезка [0, 1] [3, с. 62–64], которое легко может быть преобразовано в любые другие виды чётких числовых множеств: дискретных, непрерывных, неограниченных, при помощи различных функций конвертирования [3, с. 66–67];
– F-множества упорядоченных нечётких переменных [3, с. 59–60] вида FP = {fpi}, где fpi – лингвистические переменные, описывающие значения свойств объекта.
Дадим некоторые определения из теории нечётких систем, связанные с данным исследованием.
Нечёткое множество A в полном пространстве X определяется через функцию принадлежности (membership function):
μA : X → [0, 1].
Величина µA(x), x ∈ X интерпретируется как субъективная оценка степени принадлежности элемента x к нечёткому множеству A.
Носителем нечёткого множества или несущим множеством А называется чёткое подмножество полного пространства X, на котором значение µA(x) положительно:
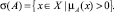
Нечёткими F-множествами называют совокупность всех нечётких подмножеств F(X) произвольного базового множества X, а их функции принадлежности – F-функциями. Как правило, под µA понимают сужение функции принадлежности со всего X на σ(A), поэтому F-множества обычно задают функцией принадлежности и несущим множеством:
A = <µA(x), σ(A)>.
Нечёткая переменная – это объект предметной области, характеризуемый тройкой {N, X, R(N, x)}, где N – название переменной, X – универсальное множество (полное пространство наблюдений) с базовой переменной x, R(N, x) ∈ F(X) – нечёткое F-множество, задающее ограничения на значения переменной x, обусловленные её названием N [2].
Лингвистическая переменная – это нечёткая переменная, значениями которой являются другие нечёткие переменные: слова или предложения естественного или формального языка [2].
Нечёткая шкала (fuzzy scale) – это упорядоченная совокупность S нечётких переменных Ai, определенных своими F-функциями, значения из которой может принимать некоторая лингвистическая переменная s:
s ∈ S,
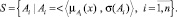
Фиксация значения s = Ai для некоторого свойства означает, что оно оценивается лингвистической переменной s и имеет значение Ai. Для задания шкалы S необходимо определить все нечёткие переменные Ai, указать их функции принадлежности и несущие множества [3, с. 128].
Фактически нечёткая шкала является обобщением известного типа порядковых шкал, в которых элементы ранжированы и отражают качественную оценку некоторого свойства объекта. Количество уровней нечёткой шкалы и несущие множества для неё рекомендуется выбирать, опираясь на исследования функции и шкалы желательности Харрингтона [3, с. 125–126].
Функция желательности Харрингтона (desirable function) – это функция, которая отображает результаты оценок экспертов на отрезок [0, 1] и характеризует уровень «желательности» той или иной оценки [1]:
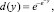
или, в другой записи,
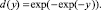
Эта функция возникла в результате наблюдений за решениями экспертов о предпочтениях соотнесения результатов эксперимента со значениями на отрезке [0, 1]. Функция позволяет оценивать предпочтение оценок для объектов различной размерности и природы. Кроме того, в областях, близких к 0 и 1, её «чувствительность» существенно ниже, чем в средней зоне (см. рис. 2). Выбор значений 0,37 и 0,63 обусловлен удобством вычислений, так как 0,37 ≈ e–1, a 0,63 ≈ 1 – e–1. За начало отсчета обычно принимают значение в точке перегиба: d(0) ≈ 0,37. Допускаются отклонения границ уровней шкалы желательности на ±0,03 [3, с. 100–101].
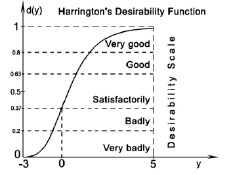
Рис. 2. Шкала желательности и функция желательности Харрингтона
Шкала желательности (desirability scale) – это психофизическая шкала, которая устанавливает соответствие между физическими параметрами свойств исследуемого объекта и психологическими, субъективными оценками экспертов «желательности» того или иного значения этих свойств [1].
Специальные функции принадлежности, используемые для построения нечётких шкал, задаются формулами [3, с. 198–202] и изображены на рис. 3.
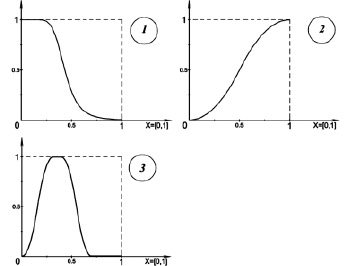
Рис. 3. Примеры специальных функций принадлежности, заданных своими параметрами: 1 – гиперболическая: µhyperbolic(x; 3; 5; 0,1); 2 – параболическая: µparabolic(x; 0; 1); 3 – колоколообразная: µbell(x; 0; 0,3; 0,4)
1. Гиперболическая:
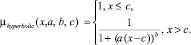
2. Параболическая:
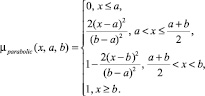
3. Колоколообразная:
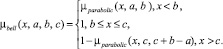
Кроме аналитического способа функции принадлежности также могут быть заданы таблично, либо используя метод согласования мнений экспертов [3, с. 131–132].
Обобщая всё сказанное выше и опираясь на примеры шкал, приведенных в работе [3, с. 94–101], для задачи классификации уязвимостей предлагается использовать следующие шкалы из множества Scale (см. рис. 4):
1. Для четкой шкалы Sp выберем множество действительных чисел из отрезка [0, 1]:
Sp = {s|s ∈ [0, 1]}.
2. Для нечёткой шкалы Sf выберем универсальную шкалу лингвистических переменных
Sf = {Min, Low, Med, High, Max},
где лингвистические переменные задаются нечёткими множествами:
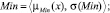
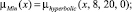
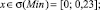
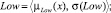
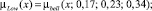
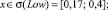
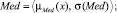
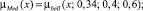
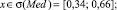
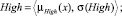
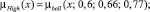
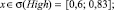
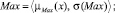
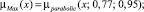
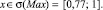
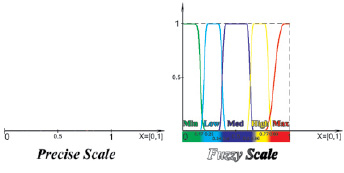
Рис. 4. Чёткие и нечёткие «универсальные» измерительные шкалы
В работе [3, с. 133–135] были определены и исследованы различные функции дефазификации и фазификации для решения практических задач.
Функцией дефазификации (defuzzification function) для нечёткого множества A ∈ F(X), X = [0, 1], заданного своей функцией принадлежности µA(x), называется любая функция Defuz(µA(x)), возвращающая чёткое значение x ? X, «характерное» для A.
Функцией фазификации (fuzzification function) для чёткого значения переменной x ∈ X и нечёткой шкалы S = {Ai} называется любая функция Fuzzy(x, S), возвращающая «наиболее подходящую» для x нечёткую переменную Ai.
Так как в нашем случае шкала Sp является множеством действительных чисел, а все функции принадлежности лингвистической переменной для шкалы Sf заданы аналитически, то в качестве функций связи между шкалами множества Scales выберем следующие:
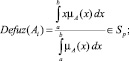
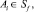
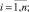
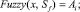
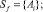
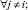
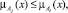
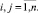
Это означает, что для отображения Defuz чёткое значение нечёткого уровня Ai вычисляется по методу центра тяжести. A для отображения Fuzzy из двух смежных уровней Ai шкалы Sf выбирается та лингвистическая переменная, у которой значение функции принадлежности 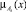 наибольшее.
наибольшее.
Кодирование входных данных
Для любого способа классификации уязвимостей они должны быть предварительно закодированы, то есть представлены вектором v = {vi} ∈ Vulners. Для этого нужно задать формальное правило кодирования, согласно которому отдельные свойства реальных уязвимостей возможно оценить на шкале Sp.
Зададим матрицу кодирования признаков уязвимостей
MVulners = (pij); pij ∈ Z; pij ≥ 0,
где строки матрицы MVulners представляют собой отдельные свойства уязвимостей (vulner property), столбцы указывают на числовой код (code) некоторого свойства, а в ячейках pij матрицы указываются значения свойств.
Для построения такой матрицы должны быть выделены только значимые свойства, однозначно отличающие одну автоматически найденную уязвимость от другой. Понятно, что для каждого сканера информационной безопасности классификация уязвимостей может быть своей. Тем не менее большинство из них содержат такие свойства как, например, тип уязвимости, протокол, по которому она может быть эксплуатирована, канал реализации внутри этого протокола, тип уязвимого объекта, путь до объекта на сервере, сетевой запрос с вектором атаки и т.д. Все возможные значения каждого свойства кодируются неотрицательными целыми числами, где ноль выделен в качестве неопределённого значения свойства, что позволит учитывать в том числе отсутствующие, новые или пока не предусмотренные значения.
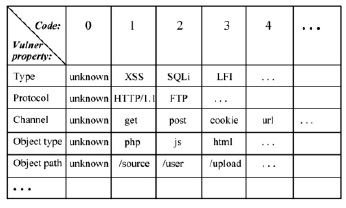
Рис. 5. Пример задания таблицы MVulners для кодирования признаков уязвимостей
Матрица MVulners может быть представлена в табличном виде (см. рис. 5). Значениями свойств могут быть также нечёткие величины, и для использования в дальнейших расчётах их нужно дефазифицировать при помощи функции Defuz. После кодирования уязвимостей для отображения значений из множества неотрицательных целых чисел на шкалу Sp можно использовать функцию конвертирования Convertor [3, с. 67]:
∀MVulners, ∀j, 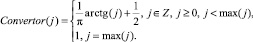
Таким образом, формальное правило кодирования свойств vi уязвимости v ∈ Vulners можно записать следующим образом:
Coding : Vulners×MVulners×Convertor → Sp.
Предложенный способ кодирования вполне подходит для решения поставленных задач. Поиск наилучшего способа числового кодирования свойств уязвимостей не является целью данного исследования.
Анализ способов решения задачи классификации уязвимостей
Пусть c = {ci} ∈ Candidates – вектор признаков некоторой уязвимости, которую требуется отнести к I или II классам. Будем считать, что все значения параметров ci – чёткие, закодированные функцией Coding и представленные на шкале Sp = [0, 1]. Если вектор признаков c задан нечёткими параметрами, то значения ci должны быть дефазифицированы при помощи функции Defuz(ci). Пусть также заданы ek ∈ Eth – векторы признаков эталонных уязвимостей из I класса, с которыми будут сравниваться остальные векторы.
Первый способ классификации уязвимости c может заключаться в построении решающего правила Classificator на основе сравнения расстояния ρ между вектором c и всеми векторами ek с пороговым значением delta:
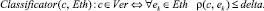
В качестве расстояния ? может использоваться любая подходящая метрика для векторного n-мерного пространства Vulners, например, евклидова:
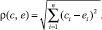
Очевидные положительные стороны такого подхода – это понятный алгоритм и простота его реализации. Подобные алгоритмы успешно используются при решении множества практических задач. Однако недостатком такого подхода для решения задачи классификации уязвимостей является то, что на практике множество векторов признаков даже одного типа не будут образовывать непрерывного и ограниченного подпространства пространства Vulners (в смысле подпространства для Rn). Это связано с тем, что автоматические сканеры не всегда могут однозначно определить некоторые свойства уязвимостей при сканировании веб-приложений. То есть при использовании матрицы кодирования MVulners даже для однотипных уязвимостей нам придется иногда ставить нули для значений некоторых свойств, либо они могут сильно отличаться от аналогичных эталонных значений. А так как метрика расстояния ρ довольно чувствительна к изменениям параметров, то при сравнении векторов признаков уязвимостей с эталонами расстояние между ними может сильно отличаться от delta.
Вторым способом классификации уязвимостей может стать построение цепочки решающих правил вида ЕСЛИ ..., ТО ..., в которых возможно учесть любые изменения значений параметров. Рассуждения эксперта при этом выглядят следующим образом. Если среди эталонных уязвимостей существует вектор ek со значениями параметров αi, и при этом вектор признаков уязвимости c имеет значения параметров ci, то этот вектор принадлежит к I классу подтверждённых уязвимостей:
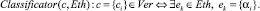
Положительные стороны такого подхода заключаются в том, что правила позволяют более гибко описать процесс принятия решения для классификатора. Однако на практике количество правил может оказаться слишком велико. Даже если совместить оба описанных способа в один: использовать в классификаторе цепочку правил, в которых выполняется сравнение значений свойств уязвимости и эталонов с некоторыми пороговыми значениями, – то всё равно реализация такого алгоритма будет затруднительна как при разработке, так и при поддержке правил в актуальном состоянии.
Недостатки указанных выше решающих правил можно попытаться устранить при помощи современного математического аппарата нейронных сетей, которые хорошо себя зарекомендовали при решении множества сложных практических задач: распознавания образов, прогнозирования, классификации и других [4].
Для решения нашей задачи необходимо определить нейронную сеть NeuronetEth (Config, c), с конфигурацией Config, обученную на векторах признаках эталонных уязвимостей из Eth, а в качестве решающего правила использовать значения выходов нейронной сети для уязвимости-кандидата:
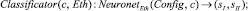
Config = const; c ∈ Candidates; sI, sII ∈ Sp.
Такой классификатор позволит более точно определить значения уровней принадлежности уязвимостей I или II классу, так как решающие правила фактически будут построены при обучении нейронной сети – она «запомнит» эталонные образцы, даже если значения отдельных признаков в них будут сильно отличаться. На вход нейронной сети должны подаваться значения векторов признаков уязвимостей, закодированных при помощи функции Coding. Построим далее нейронную сеть Neuronet с подходящей для наших целей конфигурацией Config.
Построение нейронной сети, её обучение и представление результатов
Пусть нам задано конечное число M векторов признаков уязвимостей-кандидатов, каждый из которых обладает N свойствами:
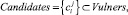
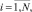
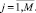
Также нам задано конечное число K векторов признаков эталонных уязвимостей, каждый из которых также обладает N свойствами:
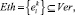
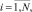
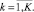
Будем задавать конфигурацию нейронной сети тройкой значений:
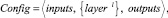
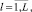
где inputs – количество входных параметров; {layerl} – множество неотрицательных целых чисел, указывающих на количество нейронов в скрытом слое номер l; L – число слоёв; outputs – количество выходных параметров.
Будем считать, что используется полносвязная многослойная сеть персептронов: выход каждого нейрона в каждом слое связан со входами всех нейронов следующего слоя.
Для решения нашей задачи использовалась конфигурация (см. рис. 6):
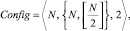
где inputs = N – по количеству свойств уязвимостей; L = 2 – установленное эмпирическим путем достаточное значение слоёв нейронной сети для классификации уязвимостей; { layer1,2} = {N, [N/2] } – установленное эмпирическим путем число нейронов в первом скрытом слое должно совпадать с количеством входных параметров, а во втором – быть целой частью от половины этого количества; outputs = 2 – по количеству классов уязвимостей, так как на выходе мы получаем вектор (sI, sII) с оценками принадлежности классам Ver и NVer.
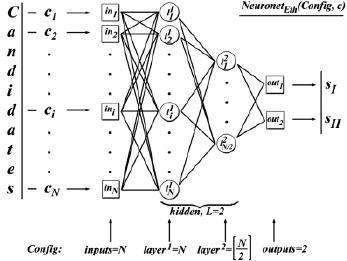
Рис. 6. Структура нейронной сети NeuronetEth(Config, c) для задачи классификации
Известный алгоритм обучения нейронной сети с учителем заключается в итеративном подборе весовых коэффициентов wi для каждого нейрона сети таким образом, чтобы значение вектора (sI, sII) на её выходе совпадало с требуемым значением для каждого входного вектора признаков из Eth [4, п.п. 2.1]. Подбор весов повторяется до тех пор, пока не устраняются противоречия для всех эталонов, либо ошибка такого обучения становится минимальной.
Вектор (sI, sII) со значениями параметров на шкале Sp может интерпретироваться следующим образом:
1. Значения параметров указывают на степень уверенности от 0 до 1 в принадлежности вектора признаков уязвимости каждому классу.
2. Значения параметров, будучи умноженными на 100 %, указывают на вероятность принадлежности вектора признаков уязвимости каждому классу от 0 до 100 %.
3. Значения параметров, фазифицированные при помощи функции Fuzzy(x, Sf), указывают на лингвистическую оценку уровня принадлежности вектора признаков уязвимости каждому из классов на шкале Sf = {Min, Low, Med, High, Max}.
На практике может использоваться любая из этих интерпретаций, удобная эксперту-аналитику.
Программная реализация классификатора
Для практического использования нейронных сетей при решении задач нечёткой классификации в случае различного числа классов и структуры сетей были разработаны программные модули FuzzyClassificator, распространяемые под лицензией GNU GPL v3.
Скачать актуальную версию FuzzyClassificator можно по ссылке на GitHub: https://github.com/Tim55667757/FuzzyClassificator/tree/master.
Для удобства использования модулей в системах автоматизации работа с программой осуществляется через интерфейс командной строки. В разделе описания программы на GitHub приведена вся информация по командам интерфейса, работе модулей и заданию входных данных. FuzzyClassificator для своей работы требует Pyzo – бесплатный и открытый инструмент разработки, основанный на Python 3.3.2 и включающий в себя множество подпрограмм для реализации научных вычислений, в частности PyBrain library – подпрограммы для работы с нейронными сетями.
Основные программные модули, реализующие предложенные в статье подходы и математический аппарат, следующие:
1. FuzzyClassificator – реализует пользовательский интерфейс командной строки, получает и обрабатывает входные данные, устанавливает режимы обучения и классификации, предоставляет результаты.
2. PyBrainLearning – определяет методы для работы с нечёткими нейронными сетями, объединяя возможности библиотеки PyBrain и авторской библиотеки FuzzyRoutines.
3. FuzzyRoutines – содержит подпрограммы для работы с нечёткими множествами и нечёткими шкалами.
Процесс работы программы представлен функциональной IDEF0-моделью на рис. 7–9.
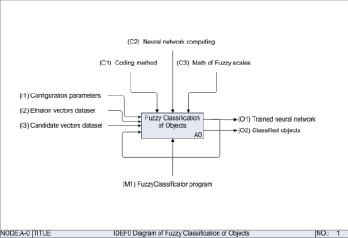
Рис. 7. Верхний A–0 уровень функциональной IDEF0-модели процесса работы программы FuzzyClassificator
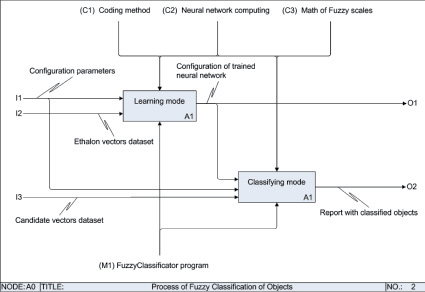
Рис. 8. Уровень A0 IDEF0-модели. Основные этапы работы программы FuzzyClassificator
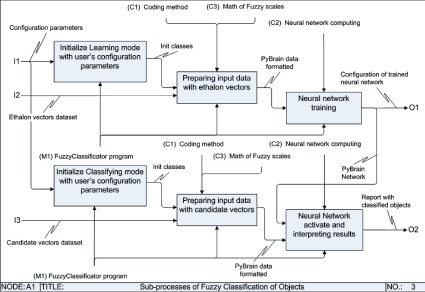
Рис. 9. Уровень A1 IDEF0-модели. Разбиение этапов работы программы FuzzyClassificator на подпроцессы
1. Этап обучения (Learning mode) состоит из следующих шагов:
1.1. Инициализация объектов программы значениями от пользователя.
1.2. Обработка входных данных и подготовка нейросети к обучению:
– обработка файла с данными о векторах признаков эталонов;
– подготовка данных для обучения в формате PyBrain;
– инициализация параметров новой нейронной сети PyBrain или её загрузка из указанного файла.
1.3. Обучение нейронной сети на заданных эталонах:
– инициализация модуля PyBrain-тренера;
– обучение сети при помощи тренера и сохранение её конфигурации в файл формата PyBrain.
2. Этап классификации (Classifying mode) состоит из следующих шагов:
2.1. Инициализация объектов программы значениями от пользователя.
2.2. Обработка входных данных и подготовка нейросети к их анализу:
– обработка файла с данными о векторах признаков кандидатов;
– загрузка конфигурации обученной нейронной сети PyBrain из указанного файла.
2.3. Анализ нейронной сетью векторов признаков кандидатов:
– активация нейронной сети и вычисление уровней принадлежности векторов к различным классам;
– интерпретация полученных результатов на нечётких шкалах и формирование файла отчёта.
Входные данные с векторами признаков эталонов и кандидатов задаются в виде обычных текстовых файлов с табуляцией в качестве разделителя значений. Например, чтобы задать данные для обучения, можно подготовить файл ethalons.dat, содержащий строку заголовка и далее строки со значениями эталонных векторов признаков и их принадлежности тому или иному классу. Значения могут быть заданы как на чёткой, так и на нечёткой шкалах:
|
input1 |
input2 |
input3 |
1st_class_output |
2nd_class_output |
|
0.1 |
0.2 |
Min |
Min |
Max |
|
0.2 |
0.3 |
Low |
Min |
Max |
|
0.3 |
0.4 |
Med |
Min |
Max |
|
0.4 |
0.5 |
Med |
Max |
Min |
|
0.5 |
0.6 |
High |
Max |
Min |
|
0.6 |
0.7 |
Max |
Max |
Min |
А в качестве данных для анализа может быть подготовлен файл candidates.dat, также содержащий строку заголовка и строки со значениями векторов признаков кандидатов:
|
input1 |
input2 |
input3 |
|
0.12 |
0.32 |
Min |
|
0.32 |
0.35 |
Low |
|
0.54 |
0.57 |
Med |
|
0.65 |
0.68 |
High |
|
0.76 |
0.79 |
Max |
По итогам работы программы создаётся файл с отчётом, содержащим информацию о конфигурации нейронной сети и результаты классификации для каждого вектора признаков из множества кандидатов.
После обучения нейронной сети на указанных выше примерах с параметрами, заданными командной строкой

и затем, в режиме классификации с параметрами командной строки

на выходе был получен следующий репорт-файл:
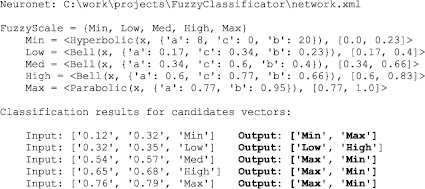
Если проанализировать данные из файла candidates.dat, то можно с высокой степенью уверенности утверждать, что человек-эксперт, опираясь только на данные из файла ethalons.dat, выдал бы аналогичные результаты классификации.
Заключение
Итак, благодаря проведённому исследованию удалось совместить математические аппараты теорий нечётких систем и нейронных сетей для решения практической задачи классификации уязвимостей. В данной статье предлагается универсальный способ представления входных данных в виде вектора признаков уязвимостей v = {vi}. Для его кодирования вводится матрица MVulners. Значения свойств уязвимостей оцениваются как на чёткой Sp = [0, 1], так и на универсальной нечёткой шкале Sf = {Min, Low, Med, High, Max}. Вводятся функции связи между шкалами: Fuzzy(x, Sf) и Defuz(Ai). Классификатор уязвимостей определяется через построение нейронной сети NeuronetEth(Config, c) с конфигурацией Config = ‹inputs, {layerl}, outputs> и непустым множеством эталонов Eth. Для практического использования классификатора разработаны универсальные программные модули FuzzyClassificator, позволяющие выполнять нечёткую классификацию произвольных объектов с неограниченным числом свойств, классов и произвольной конфигурацией многослойной нейронной сети на базе персептронов.
Основные выводы
1. Математические методы разделения на классы на базе нейронных сетей применимы и в случае классификации уязвимостей.
2. Для получения адекватных результатов необходимо корректно построить матрицу кодирования и подобрать наилучшие свойства для моделирования уязвимостей.
3. Для задачи классификации уязвимостей рекомендуется использовать нейронную сеть персептронов с двумя скрытыми слоями и в конфигурации, зависящей от числа входных параметров: в первом число нейронов равно числу входных параметров, а во втором – в два раза меньше.
4. Преимуществом предложенных подходов является использование универсальных нечётких шкал лингвистических переменных, которые применимы как для оценки значений векторов признаков, так и для интерпретации итоговых уровней принадлежности классам.
5. Предложенный метод нечёткой классификации и реализующие его программные модули FuzzyClassificator являются универсальными, легко адаптируются и настраиваются под конкретные объекты классификации.
Рецензенты:
Райхлин В.А., д.ф.-м.н., профессор кафедры компьютерных систем Казанского национального исследовательского технического университета им. А.Н. Туполева – КАИ, г. Казань;
Шарнин Л.М., д.т.н., профессор, зав. кафедрой АСОИУ Казанского национального исследовательского технического университета им. А.Н. Туполева – КАИ, г. Казань.
Работа поступила в редакцию 06.10.2014.
Библиографическая ссылка
Гильмуллин Т.М., Гильмуллин М.Ф. ПОДХОДЫ К АВТОМАТИЗАЦИИ ПРОЦЕССА ВАЛИДАЦИИ УЯЗВИМОСТЕЙ, НАЙДЕННЫХ АВТОМАТИЧЕСКИМИ СКАНЕРАМИ БЕЗОПАСНОСТИ, ПРИ ПОМОЩИ НЕЧЁТКИХ МНОЖЕСТВ И НЕЙРОННЫХ СЕТЕЙ // Фундаментальные исследования. 2014. № 11-2. С. 266-279;URL: https://fundamental-research.ru/en/article/view?id=35511 (дата обращения: 20.06.2026).