


Scientific journal
Fundamental research
ISSN 1812-7339
"Перечень" ВАК
ИФ РИНЦ = 1,798
APPLICATION OF RESOURCE-INTENSIVE ALGORITHMS IN REAL-TIME MACHINE VISION SYSTEMS

В настоящее время существует довольно много разных технологий параллельного программирования. Причем эти технологии отличаются не только и не столько языками программирования, сколько архитектурными подходами к построению параллельных систем.
В общем случае можно выделить 3 основных направления в подходе к выполнению параллельных вычислений:
- системы с раздельной памятью;
- многопоточные приложения на многопроцессорных системах с общей памятью;
- использование графического процессора видеокарты.
Системы на базе нескольких компьютеров относят к классу систем для распределенных вычислений. Подобные решения используются довольно давно. Наиболее яркий пример технологии распределенных вычислений – MPI (Message Passing Interface – интерфейс передачи сообщений). MPI является наиболее распространённым стандартом интерфейса обмена данными в параллельном программировании, существуют его реализации для большого числа компьютерных платформ [4].
Технологии параллельного программирования в среде с общей памятью получили свое развитие относительно недавно – толчком к этому послужило широкое распространение многоядерных процессоров. Одним из первых стандартов распараллеливания программ является OpenMP, первая версия которого появилась в 1997 году [17]. Разработкой спецификации OpenMP занимаются несколько крупных производителей вычислительной техники и программного обеспечения, в частности, AMD, Fujitsu, HP, IBM, Intel, Microsoft, nVidia и др. Однако OpenMP не остался единственным средством написания программ, связанных с параллельными вычислениями. В 2008 году компанией Apple был выпущен фреймворк для написания компьютерных программ, связанных с параллельными вычислениями – OpenCL [14]. С его помощью возможна организация вычислений как на центральном, так и на графическом процессорах.
Производители графических карт также разработали свои программно-аппаратные архитектуры, позволяющие производить вычисления с использованием графических процессоров. Компания nVidia представила в 2007 году архитектуру CUDA, примерно в то же время компания AMD выпустила свою технологию использования графических процессоров совместно с центральным процессором. Особенностями этих решений является их привязка к аппаратуре – графическим процессорам конкретного производителя [5].
К последним разработкам в области технологий параллельных вычислений относится разработанная Microsoft технология C++ Accelerated Massive Parallelism, построенная на платформе Microsoft DirectX. C++ AMP позволяет проектировать программы таким образом, чтобы они распределяли вычисления между центральным и графическим процессорами. Из преимуществ этой технологии стоит отметить открытую спецификацию, кроссплатформенность (в дальнейшем), поддержку мультивендорности как для центральных, так и для графических процессоров.
В данной статье перед авторами не ставилась задача определить лучшее решение для выполнения параллельных вычислений. Каждая из представленных технологий имеет свои достоинства и недостатки. В статье рассматривается эффективность и удобство применения наиболее распространенных технологий параллельного программирования в задаче разработки системы машинного зрения на основе IBM-совместимого компьютера.
Основная часть
Для рассмотрения были выбраны наиболее популярные в настоящий момент решения. В качестве теста выбран ленточный алгоритм перемножения матриц. Реализация алгоритмов проведена в среде Visual Studio 2010, язык программирования – C++. Далее приводится реализация для каждого решения.
OpenMP
OpenMP (Open Multi-Processing) – это стандарт параллельного программирования в среде с общей памятью. OpenMP предоставляет программистам набор прагм, процедур и переменных среды, позволяющих легко распараллеливать код, написанный на Фортране, С или C++ [17].
В OpenMP используется модель параллельного выполнения «ветвление-слияние». Программа OpenMP начинается как единственный поток выполнения, называемый начальным потоком. Когда поток встречает параллельную конструкцию, он создает новую группу потоков, состоящую из себя и неотрицательного числа дополнительных потоков, и становится главным в новой группе. Все члены новой группы (включая главный) выполняют код внутри параллельной конструкции, в конце которой имеется неявный барьер. После параллельной конструкции выполнение пользовательского кода продолжает только главный поток.
В OpenMP поддерживаются две основные конструкции для указания того, что работу в области параллельности следует разделить между потоками группы. Эти конструкции разделения работы – циклы и разделы. Кроме этого, существует программа, которая дает всем потокам указание ожидать друг друга перед тем, как они продолжат выполнение за барьером.
Для того чтобы использовать в проекте возможности OpenMP, необходимо явно указать это в свойствах проекта (Проект → Свойства → C/C++ → Язык → Поддержка OpenMP).
Ниже приведен участок кода программы, реализующей ленточное перемножение матриц.

Как видно из приведенного листинга, использование OpenMP не влечет за собой включение сложных синтаксических конструкций, технология хорошо интегрирована со средой разработки и ее использование удобно и интуитивно понятно для разработчика.
OpenCL
OpenCL (Open Computing Language) – открытый стандарт для универсального параллельного программирования различных типов процессоров [16]. Стандарт предоставляет программистам переносимый и эффективный доступ ко всем возможностям гетерогенных вычислительных платформ.
Для координации работы всех устройств гетерогенной системы всегда есть одно главное устройство, которое взаимодействует со всеми остальными посредством OpenCL API. Такое устройство называется «хост» и определяется вне OpenCL. Хост посылает пакеты с информацией и исполнительные команды на ускорители и получает готовые данные. Хост обрабатывает и выполняет программный код, представляющий собой тело программы, на центральном процессоре под управлением операционной системы, используя C++ или другой язык программирования. Ускорители выполняют OpenCL код, написанный на языке OpenCL C99. Существует определенный OpenCL компилятор для центрального процессора, для графического процессора и для специальных карт-ускорителей [9, 11, 15, 16].
Созданные на OpenCL программы потенциально могут использовать имеющиеся ресурсы вычислительной системы следующим образом:
- определить доступные ресурсы в гетерогенной системе и выбрать подходящие;
- создать последовательность инструкций, которые будут выполняться на ресурсах;
- подготовить начальные данные для вычислений;
- передать управление на эти ресурсы в виде OpenCL-инструкций для обработки подготовленных данных;
- собрать результаты вычислений.
Плюсы технологии несомненны: ускорение вычислений, кроссплатформенность, способность исполнять код как под GPU, так и под CPU, поддержка стандарта целым рядом компаний: Apple, AMD, Intel, nVidia и некоторыми другими. Минусов не так много, но и они есть: необходимость установки и настройки драйверов для работы OpenCL на различных устройствах.
Для использования OpenCL в проекте требуется установить соответствующий SDK в зависимости от выбора аппаратного ускорителя – CPU, GPU. Получить SDK можно на сайте производителя – Intel, nVidia, AMD и пр.
Программирование на OpenCL включает подготовку кода для запуска в ядре (распараллеливаемые операции) и на хосте (программа, управляющая ядрами). Подробное описание использования данной технологии можно найти в официальной документации [14]. В качестве примера приведен фрагмент кода, выполняющий инициализацию OpenCL.
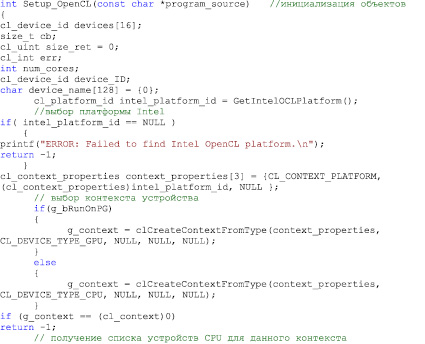
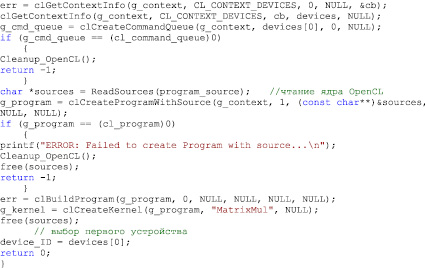
В целом код на OpenCL получается довольно громоздким за счет необходимости инициализации вычислительного устройства и компиляции ядер. Однако данный недостаток компенсируется кроссплатформенностью и отсутствием привязки к производителю.
MPI
Message Passing Interface (MPI) – программный интерфейс для передачи информации, который позволяет процессам, выполняющим одну задачу, обмениваться сообщениями. Разработан Уильямом Гроуппом и Эвином Ласком [4].
MPI является наиболее распространенным стандартом интерфейса обмена данными при организации параллельных вычислений, существуют его реализации для большого числа компьютерных платформ. Этот стандарт также используется при разработке программ для кластеров и суперкомпьютеров. В стандарте MPI описан интерфейс передачи сообщений, который может поддерживаться как платформой, так и приложением пользователя. В настоящее время существует большое количество бесплатных и коммерческих реализаций MPI. Существуют реализации для языков Фортран 77/90, С и С++ [8].
MPI предоставляет программисту единый механизм взаимодействия ветвей внутри параллельного приложения независимо от машинной архитектуры (однопроцессорные/многопроцессорные с общей/раздельной памятью), взаимного расположения ветвей (на одном процессоре или на разных). MPI предназначен для систем с раздельной памятью, его использование для организации параллельного процесса в системе с общей памятью оказывается слишком избыточно и сложно.
Существует бесплатная реализация данной библиотеки MPICH2, которая будет использоваться в данной статье. Для тестирования производительности использовался тестовый пример перемножения матриц, входящий в состав библиотеки.
Cuda
Технология CUDA – это программно-аппаратная вычислительная архитектура nVidia, основанная на расширении языка С, которая даёт возможность организации доступа к набору инструкций графического ускорителя и управления его памятью при организации параллельных вычислений [1,3,7,13]. CUDA помогает реализовывать алгоритмы, выполнимые на графических процессорах видеоускорителей GeForce восьмого поколения и старше (серии GeForce 8, GeForce 9, GeForce 200), а также Quadro, Tesla и ION.
Вычислительная архитектура CUDA основана на понятии мультипроцессора и концепции SIMD – одна команда на множество данных (Single Instruction Multiple Data). Концепция SIMD подразумевает, что одна инструкция позволяет одновременно обработать множество данных в отдельных потоках. Совокупность всех этих потоков, запущенных в рамках одной задачи, носит название grid. Параллельность исполнения grid`а обеспечивается, в первую очередь, наличием на видеокарте большего количества идентичных скалярных процессоров, которыми, собственно, и выполняются потоки. Физически скалярные процессоры являются частями потоковых мультипроцессоров.
Преимущества CUDA перед традиционным подходом к GPGPU вычислениям:
- интерфейс программирования основан на стандартном языке программирования C;
- доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор;
- линейная адресация памяти, возможность записи по произвольным адресам;
- аппаратная поддержка целочисленных и битовых операций.
Основные ограничения CUDA:
- минимальная ширина блока в 32 потока;
- закрытая архитектура CUDA, принадлежащая nVidia.
Для работы с CUDA требуется видеокарта nVidia с поддержкой данной технологии, драйвер с поддержкой CUDA, непосредственно пакет CUDA SDK и дополнительные библиотеки (CUDA toolkit). Листинг программы перемножения матриц на CUDA приведен ниже.

Реализация программы аналогична реализации на OpenCL: выбор и инициализация устройства, копирование данных из CPU в GPU, запуск ядра, копирование результатов в оперативную память.
C++ Accelerated Massive Parallelism
Microsoft представила свое видение разработки приложений для работы в гетерогенной среде с использованием всех возможностей многоядерных процессоров и GPU. Это новая платформа, разработанная при активной поддержке компаний AMD и nVidia, которая является частью одиннадцатой версии Visual Studio [10,18].
Платформа получила название C++ Accelerated Massive Parallelism или C++ AMP. Цели данной платформы следующие: дать возможность использовать преимущества параллельных вычислений и GPU одновременно на языке C++, так же как сегодня эти преимущества используются на языке С (или его подобии) в разных платформах разработки: OpenCL, CUDA, DirectCompute.
Представители Microsoft особенно подчеркивают перспективы данной платформы для разработки облачных вычислений в будущем. Платформа создавалась с расчетом того, что в скором времени сотни миллионов вычислительных модулей GPU будут использоваться в приложениях через облачные сервисы. C++ AMP позволит написать такой код уже сегодня, чтобы завтра он работал на подобных мощностях [6].
С концептуальной точки зрения AMP несколько напоминает OpenCL, так как последний тоже создавался для гетерогенного параллельного программирования и также не привязан к оборудованию какого-то одного производителя. Однако OpenCL – это существенно более низкоуровневая система и она не работает на основе вызова регулярных функций, а вручную компилируется в среде выполнения. Кроме того, буферы данных OpenCL должны в явном виде поддерживаться видеокартой [12].
Реализация программы на C++ AMP выполнена в Visual Studio 2012 (описываемая технология не поддерживается в более ранних версиях). Выдержки из кода программы, реализующей ленточное перемножение матриц, приведены далее.

Функция mxm_amp_simple()реализует параллельные вычисления, в main() выполняется выбор ускорителя – устройства выполнения параллельных вычислений.
Сравнение производительности
Результаты сравнения описанных технологий приведены в таблице. Тестирование проводилось на IBM-PC со следующей комплектацией:
- CPU – Intel Core i7 2.8 GHz;
- GPU – NVIDIA GeForce GTS 450.
В тесте проводилось перемножение матриц ленточным способом размером 1024 элемента. Вычисления производились для чисел с двойной точностью. Количество операций с плавающей точкой для данной задачи составляет Nflop = 2*(1024^3) = 2.14 DPGFLOP.
Сравнение производительности
|
Технология |
Без применения параллельных вычислений |
OpenMP |
OpenCL (CPU) |
OpenCL (GPU) |
MPI |
CUDA |
C++ AMP |
|
Производительность, GFLOPS |
0.25 |
0.92 |
3.84 |
18.45 |
7.53 |
16,7 |
10,92 |
Как можно видеть по результатам тестов, наилучшие результаты получены при использовании технологий OpenCL и CUDA. Для данной задачи OpenCL показал даже лучшее время выполнения, хотя авторы работы предполагают, что для задач, связанных с моделированием и обработкой изображений, технология CUDA покажет более высокую эффективность.
Также нельзя не отметить результаты, полученные с помощью технологии C++ AMP. С учетом того, что данная спецификация только недавно появилась, а также учитывая гораздо более простую по сравнению с OpenCL синтаксическую структуру, при аналогичных возможностях в плане мультивендорности данная технология имеет все шансы для того, чтобы де-факто стать стандартом в области параллельного программирования.
На данный момент в зависимости от целей разработки того или иного решения, а также области его применения, рекомендуется использование определенной технологии выполнения параллельных вычислений:
- при жесткой связи программной и аппаратной части решения использование технологии CUDA;
- OpenCL или C++ AMP в случае, когда заранее неизвестна аппаратная конфигурация машины, на которой будет запускаться приложение.
Технологии OpenMP и MPI, конечно, уступают по производительности, так как используют параллельные вычисления на CPU. Тем не менее вариант использования данных решений совместно с вычислениями на GPU могут дать впечатляющие результаты при условии правильной реализации структуры программы, особенно в части передачи данных между устройствами.
Работа выполнена в рамках договора № 02.G25.31.0055 (проект 2012-218-03-167).
Рецензенты:
Доросинский Л.Г., д.т.н., профессор, заведующий кафедрой «Информационные технологии», УрФУ, г. Екатеринбург;
Поршнев С.В., д.т.н., профессор, заведующий кафедрой «Радиоэлектроника информационных систем», УрФУ, г. Екатеринбург.
Работа поступила в редакцию 22.11.2013.
Библиографическая ссылка
Круглов А.В., Круглов В.Н., Чирышев А.В., Чирышев Ю.В. ПРИМЕНЕНИЕ РЕСУРСОЕМКИХ АЛГОРИТМОВ В СИСТЕМАХ МАШИННОГО ЗРЕНИЯ РЕАЛЬНОГО ВРЕМЕНИ // Фундаментальные исследования. 2013. № 10-12. С. 2612-2619;URL: https://fundamental-research.ru/en/article/view?id=32839 (дата обращения: 20.06.2026).