



Введение
Финансовые рынки являются одними из самых динамичных и сложных сред для анализа и прогнозирования. Фондовый рынок – это часть финансового рынка, на котором происходит торговля ценными бумагами, акциями и облигациями. Акции играют ключевую роль в фондовых рынках, так как они представляют собой один из основных инструментов инвестирования и привлечения капитала для компаний. Прогнозирование стоимости акций на фондовом рынке имеет большое значение для финансовой стабильности экономики в целом. Правильный прогноз изменения цен на рынке может помочь предотвратить финансовые кризисы и способствовать развитию экономики.
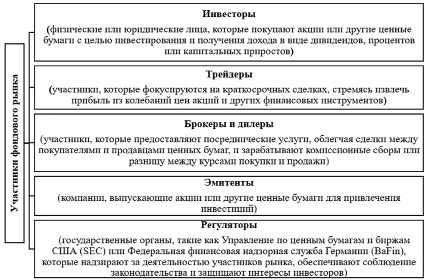
Рис. 1. Участники фондового рынка
Успешное участие в фондовом рынке и инвестирование в акции требуют понимания основных аспектов рынка, его участников и различных стратегий инвестирования. Основными участниками фондового рынка являются инвесторы, трейдеры, брокеры и дилеры, эмитенты и регуляторы (рис. 1).
Фондовый рынок обеспечивает инвесторам возможность инвестировать свой капитал, а компаниям – привлекать средства для развития своего бизнеса. Инвесторы и трейдеры всегда ищут новые методы и подходы для прогнозирования изменения цен на финансовых рынках. Одной из основных задач инвесторов является прогнозирование стоимости акций, цена которых может изменяться по различным причинам, таким как изменения в экономической ситуации, политические события, изменения на рынке и т.д. Они предоставляют компаниям возможность привлекать дополнительный капитал для развития и расширения бизнеса, особенно через первичное публичное предложение и размещение акций на фондовом рынке.
Объектом исследования являются данные фондового рынка о ценах акций крупных компаний Российской Федерации и особенности их изменения в условиях санкций и ограничений в работе Московской Биржи: для исследования выбраны компании Газпром, Лукойл, ВКонтакте, ПИК, Яндекс и Сбербанк. Выбор данных компаний обоснован тем, что каждая из выбранных компаний является одной из крупнейших в своей сфере. Цель исследования – провести сравнительный анализ результатов прогнозирования цен акций указанных компаний, сделанных на основе статистических моделей, а также полученных с помощью различных методов машинного обучения, и разработать оптимальную модель машинного обучения для прогнозирования цен акций на фондовом рынке для следующего временного промежутка.
Материалы и методы исследования
Для достижения поставленной цели были проанализированы труды зарубежных и отечественных авторов [1–3], занимающихся проблемами прогнозирования стоимости акций на фондовом рынке. В России инициаторами исследований математических методов прогнозирования цены акций являются академик РАН, профессор А.Н. Ширяев [2] и участники руководимого им семинара в Московском государственном университете им. М.В. Ломоносова и Математическом институте им. В.А. Стеклова РАН [3, 4]. При этом исследованы различные подходы к прогнозированию стоимости акций, в том числе основанные на интерполяционных свойствах мартингальных мер [5, 6].
В результате обзора научных и статистических материалов [7, 8] автором выявлены и сформированы ключевые факторы, определяющие стоимость акции:
1. Финансовые показатели компании (выручка, чистая прибыль, уровень задолженности).
2. Экономические факторы (инфляция, процентные ставки, рост ВВП).
3. Геополитические и политические события (войны, выборы и изменения в законодательстве).
4. Факторы отрасли (конкуренция, инновации, технологический прогресс).
5. Социальные факторы (поведение потребителей, демография, настроения и т.д.).
6. Другие факторы (технический анализ, информация о торговле, новости и события в отрасли).
Все эти факторы могут взаимодействовать друг с другом, и решение о том, какие факторы следует учитывать при прогнозировании курсов акций, может зависеть от целей инвестора и общей ситуации на рынке.
Традиционные методы анализа финансовых данных, такие как фундаментальный и технический анализ [9], имеют свои ограничения и не всегда могут обеспечить точный прогноз изменения цен на рынке. Эти методы анализа ценовой динамики финансовых инструментов основаны на изучении графиков и других технических данных о ценах и объемах торгов, которые позволяют наблюдать за ценовым движением активов на различных временных интервалах и определять тренды. Автором проведен анализ статических моделей прогнозирования – Auto Regressive Integrated Moving Average (ARIMA) и Generalized Autoregressive Conditional Heteroskedasticity (GARCH), при этом выявлены некоторые недостатки статистического подхода в прогнозировании стоимости акций [10, 11]:
− эти модели чувствительны к выбросам и резким скачкам в данных, что отражается на точности их прогнозов;
− модели основаны на линейных зависимостях между данными и менее эффективны для анализа временных рядов со сложными нелинейными зависимостями;
− при оценке модели GARCH используются методы максимального правдоподобия для определения оптимальных значений параметров модели, что делает ее сложной для интерпретации, особенно для непрофессионалов в области статистики и финансовых временных рядов. Это может снижать прозрачность и удобство использования модели GARCH для анализа волатильности.
В данном исследовании для прогнозирования изменения цен акций на фондовом рынке статистическая модель ARIMA используется в качестве эталонной, с ее результатами сравниваются результаты двух моделей машинного обучения [12, c. 117], Support Vector Regression (SVR) и Long Short-Term Memory (LSTM), и показывается эффективность их применения. Инструментом для достижения цели выбран своего рода динамический язык программирования Python в средах разработки Visual Studio Code и Colaboratory в режиме Jupyter Notebook.
Опишем коротко процесс получения и предобработки данных. Материалы для исследования импортированы с информационно-статистического сервера Московской Биржи (https://www.moex.com/). Для получения данных о стоимости акций использован API от Pandas (pandas-datareader), в качестве даты начала сбора данных о ценах акции взята дата 01.04.2022. Эта дата была выбрана для того, чтобы разработанные модели обучались на значениях стоимости акций после обвала российского рынка акций. В качестве последней даты, получаемой при выгрузке значений котировок акций с Московской Биржи, использована текущая дата на день получения данных, а именно 15.09.2024.
Полученные данные были визуализированы (рис. 2) и сформированы выводы по динамике стоимости акций за указанный период.
Приведем основные выводы о динамике акций за это время: из всех выбранных акций за текущий период выросли в цене только акции компании Сбер (рост на 50 % от цены 01.04.2022), цены акций других компаний остались примерно на уровне второго квартала 2022 г., кроме акций компании Газпром (цены акций опустились ниже цены апреля 2022 г. на 30 %). У выбранных акций, кроме компании Сбер и Газпром, достаточно высокая волатильность в рассматриваемом периоде. Таким образом, можно сделать вывод, что в текущем состоянии российский рынок акций имеет потенциал роста и является подходящим для краткосрочного прогнозирования.
Далее, согласно принципам машинного обучения [12, c. 31], автором создан набор обучающих данных – x_train и y_train:
− в массив x_train записаны данные по цене открытия, максимальной и минимальной цене акции, а также объем торгов за день,
− в массив y_train записаны соответствующие значения цены закрытия акции на текущий день.
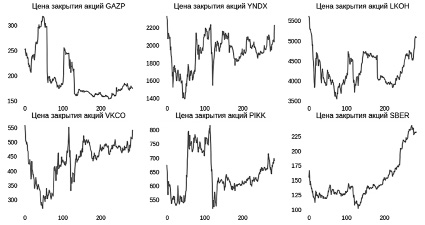
Рис. 2. Цены закрытия акций компаний за период с 01.04.2022 по 15.09.2024
Для SVR модели этап подготовки данных был завершен, а для LSTM модели массив x_train преобразован при помощи функции numpy.reshape() библиотеки numpy, так как для использования в LSTM слоев нейронной сети требуется соответствие форме слоев модели (количество сэмплов, количество шагов времени, количество признаков). Для модели ARIMA данные просто разделены на обучающую и тестовую выборку. На этом процесс получения и предобработки данных был завершен.
В исследовании разработаны такие модели прогнозирования стоимости акций:
1) статистическая модель ARIMA;
2) модель SVR, которая использует класс GridSearchCV для подбора оптимальных гиперпараметров;
3) модель нейронной сети, которая состоит из двух LSTM слоев – полносвязного слоя Dense с активационной функцией ReLu и выходным полносвязным слоем Dense.
Процесс реализации указанных моделей начинался с их обучения при помощи метода fit() на обучающей выборке [12, c. 151], которая составляла 85 % от всего исходного датасета. Модель LSTM обучалась на 15 эпохах, модель SVR в процессе обучения при помощи класса GridSearchCV подбирала лучшую комбинацию гиперпараметров для лучших результатов [12, c. 332].
Для оценки качества разработанных моделей были выбраны две метрики: Root Mean Squared Error (RMSE) и R-squared (R2) (из-за простоты расчета, интерпретируемости и универсальности). Данные метрики сравнивают реальные данные тестовой выборки с предсказанными и подходят для оценки как статистических моделей, так и для моделей машинного обучения. RMSE (Root Mean Squared Error) – это метрика оценки ошибки, используемая для измерения разницы между значениями, предсказанными моделью, и реальными значениями:
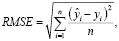
где yi – реальное значение i-го наблюдения;
ŷi – предсказанное значение i-го наблюдения; n – количество наблюдений.
Однако следует учитывать, что RMSE усиливает влияние больших ошибок из-за квадратичной зависимости, и в некоторых случаях другие метрики, такие как средняя абсолютная ошибка (MAE) или коэффициент детерминации R2, могут быть более подходящими для оценки качества модели. Метрика оценки R2 измеряет, насколько хорошо предсказанные значения модели соответствуют реальным значениям:
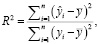
где yi – реальное значение i-го наблюдения, ŷi – предсказанное значение i-го наблюдения; y – среднее значение реальных значений; 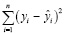 – сумма квадратов ошибок (разности между реальными и предсказанными значениями);
– сумма квадратов ошибок (разности между реальными и предсказанными значениями);
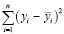 – сумма квадратов отклонений реальных значений от их среднего значения (общая вариация). Значение R2 принадлежит диапазону от 0 до 1, и большие значения указывают на лучшее соответствие между предсказанными и реальными значениями. В данном исследовании для оценки качеств моделей использованы функции r2_score и numpy.sqrt(mean_squared_error) из библиотеки sklearn. Для улучшения качества моделей машинного обучения полученные данные были нормализованы при помощи метода MinMaxScaler [12, c. 150].
– сумма квадратов отклонений реальных значений от их среднего значения (общая вариация). Значение R2 принадлежит диапазону от 0 до 1, и большие значения указывают на лучшее соответствие между предсказанными и реальными значениями. В данном исследовании для оценки качеств моделей использованы функции r2_score и numpy.sqrt(mean_squared_error) из библиотеки sklearn. Для улучшения качества моделей машинного обучения полученные данные были нормализованы при помощи метода MinMaxScaler [12, c. 150].
Результаты исследования и их обсуждение
Приведем и обсудим основные результаты исследования. После завершения процесса обучения для построения прогноза модели была использована тестовая выборка, и по результатам предсказанных значений на тестовой выборке произведено вычисление метрик RMSE и R2. На рис. 3 отражены значения цен акций на момент закрытия торгов трех компаний (в статье для демонстрации выбраны три компании – Газпром (рис. 3, а), Яндекс (рис. 3, б) и Сбера (рис. 3, в)), а также предсказанные значения цены акций с помощью трех моделей на тот же период.
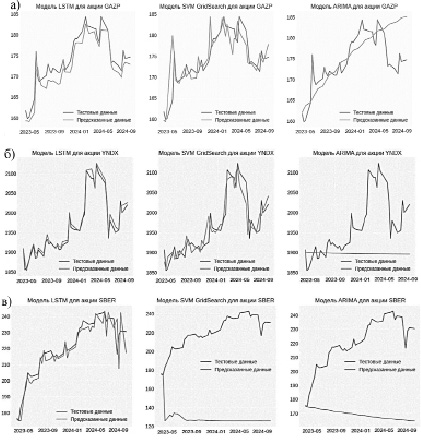
Рис. 3. Результаты прогнозирования моделей для компаний: а) Газпром; б) Яндекс; в) Сбер
Таблица 1
Значения метрики RMSE для разработанных моделей
|
Компания |
LSTM RMSE |
SVR GridSearch RMSE |
ARIMA RMSE |
|
GAZP |
2.704367 |
3.824027 |
23.068600 |
|
YNDX |
11.882246 |
20.399990 |
783.102159 |
|
LKOH |
45.347834 |
193.995273 |
1263.762013 |
|
VKCO |
1.977567 |
8.220268 |
20.478179 |
|
PIKK |
3.119526 |
10.375106 |
124.035644 |
|
SBER |
8.524124 |
192.713422 |
26.743254 |
Модели LSTM и SVR достаточно хорошо справились с задачей прогнозирования стоимости акций на краткосрочный период. Данные модели показали, что они достаточно хорошо реагируют на резкое изменение цены акции, что как раз являлось необходимым для решения поставленной цели. Модель ARIMA не справилась с задачей краткосрочного прогнозирования стоимости акций, она не показала чувствительности к резким изменениям цены. ARIMA скорее определяет направление движения цены (тренд) и, вероятнее всего, больше подходит для долгосрочного прогнозирования, так как общее направление цены моделью отображается достаточно корректно. Единственная компания, с которой у моделей возникли проблемы – Сбер (рис. 3, в). Модели ARIMA и SVR не смогли корректно спрогнозировать стоимость акций данной компании на тестовой выборке. Модель LSTM при прогнозировании стоимости акций Сбера показала также более низкий результат, по сравнению со значениями, предсказанными для других компаний. Предсказанные моделью значения цены закрытия акций Сбера оказались более волатильными по сравнению с реальными данными. Возможно, модели плохо справились с прогнозированием стоимости акций данной компании из-за того, что Сбер – единственная компания из выбранного списка, у которой в течение исследуемого периода был просто восходящий тренд, без особой волатильности.
Дадим оценку результатов работы моделей при помощи метрик R2 и RMSE. В табл. 1 представлены значения метрики RMSE для каждой акции по каждой модели.
По данным этой таблицы видно, что значения RMSE лучшие у LSTM модели, что говорит о ее хорошей предсказательной способности. Также стоит отметить, что для модели LSTM средняя доля ошибки относительно средней цены закрытия акции находится в диапазоне от 0.5 до 1.5 %. Исключение – компания Сбер, для нее средняя доля ошибки относительно средней цены закрытия акции 3.8 %. Для данной компании также самое большое значение RMSE у модели LSTM – 8.5 %. Следует отметить, что модель LSTM достаточно качественно прогнозирует стоимость акций выбранных компаний. Модель SVM также справляется с данной задачей относительно неплохо, но все же несколько хуже, по сравнению с LSTM моделью. Как и у LSTM модели, у модели SVR не получилось построить корректный прогноз для акций компании Сбер, значение метрики RMSE для данной компании – 192,71 в среднем предсказанная цена отличается от реальной на 85 %, что говорит о достаточно плохом качестве прогноза. Причины, по которым мог построиться некачественный прогноз для данной компании, были указаны выше. Для модели ARIMA значение метрики RMSE получилось достаточно большим, среднее отклонение предсказанных цен от реальных находится в диапазоне от 4 до 40 %. Модель ARIMA в большей степени определяет направление цены акции в целом, она не проявляет чувствительность к краткосрочным изменениям цены.
Исходя из данной информации, можно сделать предварительный вывод, что модель LSTM является лучшей из рассмотренных моделей для решения задачи краткосрочного прогнозирования стоимости акций. В табл. 2 приведены значения метрики R2 для каждой акции по каждой модели. По значениям из табл. 2 отмечаем, что R2 лучшие у LSTM модели, что еще раз подтверждает ее хорошую предсказательную способность. Для компаний Яндекс, Лукойл, ВК и ПИК значения R2 более 96 %, для компаний Сбер и Газпром значение R2 выше 70 %, что говорит об удовлетворительном качестве предсказания модели LSTM для данных компаний.
Таким образом, модель LSTM достаточно хорошо справляется с задачей краткосрочного прогнозирования, это можно заметить и по графикам предсказанных данных (рис. 3), и по значениям метрик (табл. 1 и 2).
Таблица 2
Значения метрики R2 для разработанных моделей
|
Компания |
LSTM R2 |
SVR GridSearch R2 |
ARIMA R2 |
|
GAZP |
0.779002 |
0.698071 |
0.071328 |
|
YNDX |
0.972374 |
0.782659 |
0.023405 |
|
LKOH |
0.959170 |
0.652607 |
0.017623 |
|
VKCO |
0.965757 |
0.693426 |
0.091122 |
|
PIKK |
0.9754497 |
0.735645 |
0.337853 |
|
SBER |
0.696976 |
0.038712 |
0.061283 |
Значение R2 у модели SVR удовлетворительное. В среднем 70 % вариации в данных объясняется моделью SVR, что также говорит об удовлетворительном качестве предсказательной способности модели. Исключение составляет только компания Сбер – стоимость акций данной компании модель не смогла нормально смоделировать. Значения R2 для модели ARIMA низкие (около 10 %), исключение составляет только компания ПИК, для нее значение R2 модели ARIMA составляет 33 %, однако это также является неудовлетворительным результатом. Исходя из этой информации можно еще раз сделать вывод, что модель ARIMA неспособна реагировать на резкое изменение цены на коротком промежутке, она больше предназначена для определения направления цены, что также является важной частью прогнозирования стоимости акций. Однако для задач краткосрочного прогнозирования данная модель не подходит, поэтому модель ARIMA была исключена из анализа для выбора лучшей модели. На выбор оставались две модели: модель LSTM и модель SVR с GridSearch. При выборе лучшей из них нельзя было назвать модель SVR плохой, она неплохо справлялась с краткосрочным прогнозированием и реагировала на резкое изменение цены. Графики предсказанных значений при помощи данной модели также удовлетворительного качества (рис. 3). Более того, по значениям выбранных метрик (табл. 1 и 2) модель также показала неплохой результат. Однако, если сравнивать модель SVR с моделью LSTM, по всем показателям вторая модель оказывается лучше. У модели LSTM более высокие значения R2 (в среднем выше на 15–20 %), а также более низкие значения ошибки RMSE (в среднем ниже в несколько раз), а также более точные предсказания цены акции, если сравнивать графики предсказанных значений данных моделей (рис. 3). Все это говорит о том, что в рамках краткосрочного прогнозирования на данном наборе акций разработанная модель LSTM показывает лучшие результаты по сравнению с остальными моделями. Именно поэтому дальнейшая работа была продолжена с моделью LSTM. Также стоит отметить, что модели SVR и ARIMA в теории могут показать результаты лучше, чем LSTM модель в других условиях. Например, при увеличении объема выборки, изменении горизонта прогнозирования или выборе другого набора акций.
Для доработки модели LSTM с целью улучшения качества прогноза было принято решение добавить в модель дополнительные признаки, которые будут помогать модели в прогнозировании стоимости акций. Данными признаками стали технические индикаторы, которые будут рассчитаны для цены акции на каждый день наблюдения. В модели были использованы следующие индикаторы: MACD, AROON, PSAR, RSI и TSI (рис. 4). Для начала необходимо было объявить каждый из пяти индикаторов, которые используют для расчета цену закрытия акции. Индикатор PSAR, помимо цены закрытия акции, в качестве входных параметров для расчета использует максимальную и минимальную цену акции за текущий период. Каждый из рассчитанных индикаторов использован в модели машинного обучения в качестве дополнительного признака, что позволило модели обучаться на большем количестве исходных данных и потенциально построить более точный прогноз на следующий период. Также для каждого из индикаторов были установлены параметры по умолчанию (возможна пользовательская настройка). Отметим, что изменение параметров индикаторов влияет на конечный прогноз цены на следующий период. После объявления и установки параметров по умолчанию индикаторы были добавлены в модель. В итоге в качестве признаков в модели использованы: цена открытия акции, цена закрытия акции, максимальная цена акции за период, минимальная цена акции за период, объем торгов за период и значения технических индикаторов MACD, AROON, PSAR, RSI и TSI (возможность изменять базовые параметры имеется).
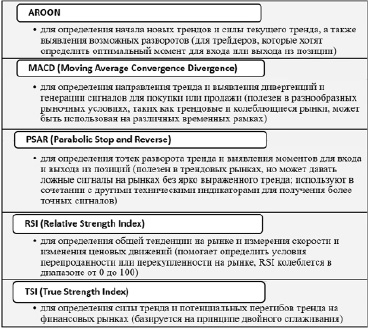
Рис. 4. Описание технических индикаторов и осцилляторов
Для лучшей работы модели данные были нормализованы при помощи MinMax Scaller, как и в изначальном варианте модели. Также была изменена входная форма первого LSTM слоя, которая задается кортежем, соответствующим количеству шагов времени и количеству признаков массива x_train. Количество признаков было увеличено на 5. Входной массив x_train приведен к форме, чтобы он соответствовал форме LSTM слоя. Из-за того, что количество признаков в модели было увеличено более чем в 2 раза, было принято решение увеличить количество эпох обучения с 15 до 30. В табл. 3 приведены результаты доработанной модели LSTM, а именно значения метрик R2 и RMSE для каждой акции по данной модели. По данным табл. 3 видно, что качество модели улучшилось ненамного. Значения R2 и RMSE для компаний Яндекс, Лукойл, ВК и ПИК остались на том же уровне, однако значения метрик для компаний Газпром и Сбер несколько улучшились. Для компании Газпром RMSE уменьшилась до 2.5, а R2 увеличился до 81 %. Для компании Сбер RMSE уменьшилась до 7.3, а R2 увеличился до 75 %.
Таблица 3
Значения метрик RMSE и R2 для доработанной модели LSTM
|
Компания |
LSTM RMSE |
LSTM R2 |
|
GAZP |
2.489137 |
0.808754 |
|
YNDX |
11.970528 |
0.968145 |
|
LKOH |
44.851202 |
0.968362 |
|
VKCO |
2.019532 |
0.941873 |
|
PIKK |
3.097267 |
0.978628 |
|
SBER |
7.320869 |
0.760109 |
В итоге данная модель стала лучше прогнозировать стоимость акций Сбера и Газпрома, возможно, в таком улучшении модели нет большой необходимости, поскольку и в первоначальном виде модель имела хорошую предсказательную способность, однако данное улучшение сделало модель более гибкой за счет того, что технические индикаторы могут изменять свои значения за счет изменения их базовых параметров, таких как число дней, используемых при вычислении или период короткой, или длинной EMA. Изменение данных базовых параметров влияет на значение индикатора, что, естественно, отражается в конечном прогнозе модели.
Таким образом, автором разработаны три модели прогнозирования стоимости акций, а именно: статистическая модель ARIMA; модель SVR, которая использует класс GridSearchCV для подбора оптимальных гиперпараметров и модель нейронной сети, которая состоит из двух LSTM слоев, полносвязного слоя Dense с активационной функцией ReLu и выходным полносвязным слоем Dense. По итогам сравнительного анализа разработанных моделей можно отметить, что модель LSTM хорошо справляется с задачей краткосрочного прогнозирования выбранного набора акций. Модель SVR также может иметь хорошую предсказательную способность, для ее лучшей реализации, возможно, следует изменить набор акций, увеличить объем выборки и горизонт прогнозирования. Также в ходе исследования было выявлено, что модель ARIMA не подходит для решения задачи краткосрочного прогнозирования. Данную модель следует использовать для определения направления цены акции (тренда), то есть данная модель больше подходит для задач долгосрочного прогнозирования. С учетом доработки модели LSTM путем добавления технических индикаторов была улучшена ее предсказательная способность.
Перечислим основные рекомендации проведенного автором исследования:
1. Разработанную модель применять только для прогнозирования стоимости акций рассмотренных компаний, так как на других компаниях модель может работать некорректно из-за того, что качество данной модели на них изначально не проверялось.
2. Не изменять горизонт прогнозирования и временной промежуток, поскольку на другом временном промежутке и на более длинном горизонте прогнозирования модель может показывать не такой качественный результат, так как она создавалась для других целей, а именно для краткосрочного прогнозирования на данных после обвала на Московской Бирже.
3. Использовать данную модель только в рамках прогнозирования стоимости акций российских компаний, для других задач данная модель не предназначена, и нет уверенности в том, что созданная модель с ними справится.
4. Спроектировать интерактивное веб-приложение, которое позволит любому человеку, в том числе тому, кто не разбирается в программировании и нейронных сетях, использовать разработанную модель машинного обучения для прогнозирования стоимости акций.
Заключение
В результате анализа российского рынка акций был сделан вывод, что в текущем состоянии российский рынок акций является подходящим для краткосрочного прогнозирования стоимости акций на фондовом рынке. Модели машинного обучения, применяемые в статье, улучшают точность такого прогнозирования за счет работы с большим объемом данных и способностью учитывать нелинейные зависимости. Исходя из предсказаний, сделанных на основе применения методов машинного обучения, инвесторы и трейдеры могут принимать более осознанные решения, а результаты исследований могут быть использованы при разработке новых подходов к анализу и прогнозированию стоимости акций на фондовом рынке.
Библиографическая ссылка
Шамраева В.В. МАТЕМАТИЧЕСКИЕ МЕТОДЫ ПРОГНОЗИРОВАНИЯ ИЗМЕНЕНИЯ ЦЕНЫ АКЦИЙ И ИХ РЕАЛИЗАЦИЯ МЕТОДАМИ МАШИННОГО ОБУЧЕНИЯ // Фундаментальные исследования. 2024. № 11. С. 88-96;URL: https://fundamental-research.ru/ru/article/view?id=43718 (дата обращения: 11.07.2026).
DOI: https://doi.org/10.17513/fr.43718