



Машинное обучение является одной из самых популярных тем для обсуждения в области науки о данных последнего десятилетия. И такая актуальность вполне обоснована – специально разработанные алгоритмы научились решать даже самые нетривиальные задачи с выгодой для бизнеса. Минимизация простоев на производствах, распознавание фотографий, текста или музыкальных произведений, выявление угроз безопасности, принятие правильных управленческих решений в сфере маркетинга – все это перестало быть чем-то удивительным сегодня. Спектр областей применения машинного обучения огромен, и каждая индустрия имеет свою специфику. В данной статье внимание авторов будет сосредоточено на решении задачи кредитного скоринга.
В современном мире банки играют ключевую роль в развитии мировой экономики. Если производить сопоставление классических коммерческих банков с человеческим организмом, то мировой финансовый рынок – это физическая структура тела, а банки – его сердечно-сосудистая система. Выдавая кредиты и выступая посредником в инвестиционных сделках, банки осуществляют аккумуляцию и перераспределение денежных средств среди достойных кандидатов, тем самым обеспечивают оптимальное давление в импровизированной кровеносной системе [1]. Однако что будет происходить при нарушении такого баланса? Скажем, как повлияет на человеческий организм изредка повышающийся уровень холестерина? Проявления какой-то неожиданно экстремальной реакции организма в этом случае скорее всего ждать не стоит. Но если это будет носить закономерный и регулярный характер, то последствия могут быть катастрофическими. Похожим образом на «здоровье» банковского сектора будет влиять выдача кредитов несостоятельным юридическим и физическим лицам. Если заемщик является недостаточно надежным, то риск невозврата выданных под процент денежных средств начинает резко возрастать [2]. Учащающиеся случаи дефолтов будут наносить серьезный удар по финансовому состоянию банков и, как следствие, по экономике страны. Чтобы описанная выше ситуация не случилась, ученые по данным начали исследовать потенциальные варианты для максимизации вероятности отличия надежного заемщика от недостаточно надежного. Если еще в конце XX в. решение об одобрении кредита принимали люди [3], опираясь на их экспертизу в решении этого вопроса, то сейчас даже в самых маленьких банках России используются технологии машинного обучения [4]. Так, специалисты в области анализа данных смогли придумать, реализовать и опытным путем опробовать решение задачи, которая позже получила название «Кредитный скоринг».
По своей сущности оценка кредитоспособности заемщиков сводится к принятию банком решения о выдаче кредита клиенту, т.е. всесторонне рассматривается способность исполнения заемщиком взятых на себя обязательств. Надежность при этом обеспечивается благодаря использованию скоринговых систем – специалисты банка при оформлении заявки на получение кредита фиксируют набор специальным образом подобранных параметров, на основании которых модель кредитного скоринга, обученная по данным (клиентский опыт), будет осуществлять прогноз, результатом которого будет ответ на вопрос: «Учитывая риск данного заемщика, целесообразно ли выдавать кредит?» [5] Рассматриваемая задача прогнозирования является задачей классификации. Например, модель может разделить людей, которые подали заявки на получение займа, на два крупных класса: надежные и сомнительные. Кажется, что такая сепарация выглядит слишком просто, однако такой подход позволяет наиболее точно ответить на вопрос, который был поставлен ранее.
Итак, на основании заранее собранных данных модель кредитного скоринга будет осуществлять прогнозирование класса, в который заемщиков можно будет отнести: «надежные» или «сомнительные».
Для того чтобы углубиться в специфику реализации алгоритма кредитного скоринга на конкретном примере, первоначально необходимо рассмотреть наиболее распространенные вариации задачи. Специалисты, которые работают в банковской сфере в области кредитования, выделяют следующие крупные виды скорингов: заявочный, поведенческий и мошеннический [6]. Первый тип может быть применен к двум категориям клиентов – тем, которые уже имеют кредитную историю (происходит сопоставление данных потенциального заемщика с данными по людям, в отношении которых в прошлом уже было принято решение о выдаче займа), и тем, кто такой истории не имеет. В общем случае это самая распространенная категория рассматриваемых задач.
Задача поведенческого скоринга сводится к прогнозированию поведения клиента. Часто банку требуется не только определение вероятности дефолта по кредиту конкретного человека, но и исследование частоты и объема выплат. Например, если вы собираетесь получать кредит в коммерческом банке, который является также вашим зарплатным банком, то вся история ваших трат и начислений будет служить точкой опоры для предсказания, будут ли осуществляться выплаты по заранее установленному плану равномерно.
Мошеннический тип предназначен для борьбы с недобросовестными заемщиками и используется преимущественно государственными силовыми структурами или службами безопасности банков.
Очевидно, что две последние разновидности могут быть рассмотрены только в условиях доступа к соответствующим данным. В текущем исследовании будет построена модель кредитного скоринга заявочного типа, поскольку для нее могут быть использованы открытые данные о выданных кредитах.
Целью исследования является применение методов машинного обучения на реальных данных о кредитовании с задачей максимизировать вероятность правильной классификации заемщиков.
Материалы и методы исследования
Для решения задачи кредитного скоринга мы будем использовать данные, которые содержатся в открытом доступе и при этом являются достоверными и достаточно полными. Lending Club – крупнейшая платформа по одноранговому кредитованию клиентов из США, которая выкладывает данные о своих пользователях в открытый доступ (URL: www.lendingclub.com). Ежеквартально датасеты дополняются и выкладываются на портале Kaggle.com с детальным описанием каждой переменной. Когда потенциальный заемщик отправляет заявку на получение кредита, то компания должна принять решение об одобрении займа на основе профиля заявителя. Для этого предоставляется и специальным образом заверяется информация, необходимая для оценки кредитоспособности.
Мы будем использовать обновленные данные за 9 месяцев 2022 г., сгруппированные в 73 столбца (признак по каждому клиенту) и 400 тысяч строк (число одобренных заявителей). Именно эта пользовательская база станет основой для нашего исследования.
В первую очередь будет проведен исследовательский анализ данных, который позволит детально рассмотреть все ключевые переменные, представленные в датасете. Далее будет происходить предобработка данных, которая включает в себя удаление незначимых переменных, детектирование аномальных, пустых значений и их дальнейшую ликвидацию, преобразование категориальных признаков в численные, введение суррогатных переменных и нормализацию. После этого набор данных был разделен на обучающую и тестовую выборки.
Следующий этап будет заключаться в непосредственном решении задачи классификации. Для этого было решено выбрать модели, наиболее применимые на практике в кредитном скоринге, а именно: искусственную нейронную сеть (ANN), XGBoost классификатор и модель случайного леса. В качестве метрик качества были выбраны классические показатели – ROC, f1-score, Precision, Recall, Accuracy. Для всех трех моделей был произведен оптимальный подбор параметров в целях максимизации эффекта точности. Далее были произведены обучение моделей, сопоставление результатов и выбор наиболее удачной модели для решаемой нами задачи.
Подготовка данных к работе
После того как мы получили представление о том, какие переменные присутствуют в данных, и стали понимать их особенности, переходим к непосредственной работе с данными.
В первую очередь посмотрим, какие переменные содержат пустые значения. Для этого в цикле пройдем по каждому столбцу датасета и осуществим данную проверку. Обнаруживаем, что есть признаки, которые абсолютно неинформативны (например, open_il_6m), поскольку не представляют для наших задач никакой смысловой ценности. Кроме того, почти все такие характеристики содержат много значений типа NaN. С такими переменными работать далее не представляется возможным, поэтому мы можем удалить их. Осталось обработать только признаки, которые содержат небольшое число пропусков. Под небольшим числом пропусков в признаке понимается отсутствие не более 5% данных для данного признака. Для этого мы теперь будем удалять не целые столбцы (поскольку они содержат важную информацию для модели кредитного скоринга), а только выборочно строки, которые содержат пустые значения.
Теперь нам необходимо поработать с категориальными переменными. Всего среди 24 переменных 6 имеют тип Object. Признак term, как мы уже выяснили ранее, представляется числом месяцев, в которые необходимо делать выплату клиенту (36 или 60 месяцев). Заменим каждое строчное значение на соответствующее ему число. Адресные данные (переменные зип-код и непосредственный адрес) считаем необходимым удалить, поскольку эта информация не влияет на способность конкретного заемщика к выплате займа. Переменные grade (рейтинг, присвоенный клиенту на основании его кредитной истории) и sub_grade (так называемый детализированный рейтинг) также являются категориальными. Получаем, что grade – подфункция от sub_grade. Поэтому данную характеристику можно удалить. Последней категориальной переменной является целевая переменная loan_status, представляющая собой статус по кредиту для каждого заемщика. Уникальными значениями данного признака являются «полностью выплачен», «дефолт», «текущая выплата». Мы будем осуществлять предсказание для первого и второго вариантов.
Также на данном этапе обработки данных мы удалили дубликаты строк. Далее с помощью функции train_test_split осуществляем сепарацию данных на тестовую и тренировочную выборки в соотношении 1:3. Теперь обращаем внимание на то, что еще во время исследовательского анализа было обнаружено, что данные содержат выбросные значения. Устранять данную проблему будем с помощью ограничения всех данных 95% квантилем (так получится избежать негативного влияния выбросов). Теперь с помощью MinMaxScalar и fit_transform производим нормализацию получившихся выборок для дальнейшего применения моделей машинного обучения.
Построение моделей
D. Shashi, S.S. Handa и N.P. Singh в своей статье [7], посвященной изучению методологий решения задач кредитного скоринга, сравнивали эффективность 20 различных моделей на наборе данных Германии. Признанная экспертиза ученых по данным и их исследование побудили использовать три «лучших» с точки зрения получения наивысшей точности предсказания метода. Поскольку решаемая нами задача является классификацией, то в качестве метрик качества мы будем использовать Accuracy score, Precision, Recall, f1-score, ROC, AUC.
1. Artificial neural network (ANN)
ANN, или искусственная нейронная сеть, будет обучаться в 20 эпохах, со скоростью обучения 0.001, в качестве функции потерь будет использоваться бинарная кросс-энтропия. В результате обучения мы можем визуализировать AUC-кривую обучения, чтобы отследить динамику качества классификации, представленную на рисунке 1.
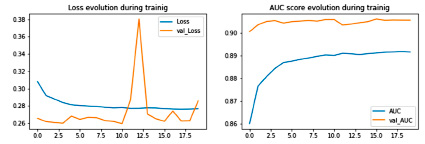
Рис. 1. AUC-кривая обучения для ANN
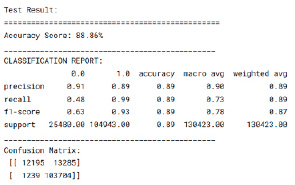
Рис. 2. Результаты точности предсказания модели 1
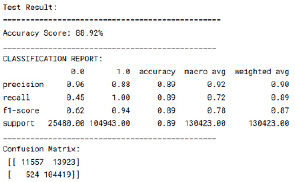
Рис. 3. Результаты точности предсказания модели 2
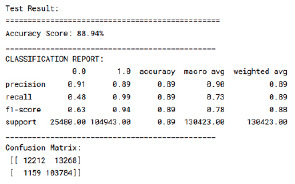
Рис. 4. Результаты точности предсказания модели 3
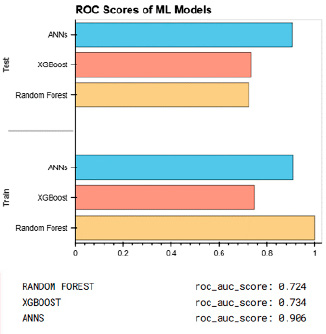
Рис. 5. Результаты сопоставления точностей моделей
В среднем показатель AUC во время обучения был чуть выше 0,9, что для обучающейся выборки является довольно высоким показателем. На тестовой же выборке аналогичная метрика на несколько процентных пунктов меньше. Теперь обратим внимание на отчет о классификации (рис. 2).
Accuracy score составил 0,89. В задаче предсказания дефолтных случаев по кредиту Precision – 0,91, Recall – 0,48, f1-score – 0,63. Показатели метрик получились достаточно высокие, что свидетельствует о правильно подобранных параметрах модели и грамотно предобработанных данных.
2. XGBoost классификатор
Следующая модель машинного обучения – XGBoost классификатор. На удивление, метрики качества в данном случае оказались почти полностью идентичны нейронной сети, построенной ранее. Обратим внимание на отчет о классификации (рис. 3).
3. Random Forest классификатор
Модель случайного леса (Random Forest) является также одной из самых мощных моделей в машинном обучении. Возможно, в решении задачи кредитного скоринга получится улучшить полученные ранее результаты. В процессе подбора оптимальных параметров модель пересчитывала результаты. В итоге получилось увеличить показатель Recall на 0,05 при эквивалентных остальных значениях метрик. Однако ROC-score здесь оказался значительно ниже, чем у нейронной сети. Чтобы удостовериться в этом, посмотрим на отчет о классификации модели (рис. 4).
Сравнение метрик качества по моделям
В настоящей статье были построены три модели машинного обучения, способные осуществлять классификацию заемщиков на надежных и сомнительных. Однако необходимо определиться с тем, насколько удовлетворительными являются полученные результаты. Сделать это можно в том числе с помощью сравнения метрик качества моделей на тестовых данных. В задаче кредитного скоринга эффективность построенной модели чаще всего анализируют на основании показателей ROC и AUC. Визуализируем получившиеся результаты для каждой модели, чтобы можно было сделать выводы.
На тестовых данных наилучшим образом показала себя искусственная нейронная сеть (обе метрики превосходят 0,9, что свидетельствует о довольно хорошем качестве модели классификации). При этом XGBoost и Random Forest также показали неплохую эффективность в решении задачи классификации.
Заключение
В данной работе была продемонстрирована реализация 3 методов машинного обучения (искусственная нейронная сеть (ANN), XGBoost классификатор и модель случайного леса) в решении задачи кредитного скоринга, которая, в свою очередь, была сведена к задаче классификации. Для всех трех моделей был произведен оптимальный подбор параметров в целях максимизации эффекта точности. Далее были реализованы обучение моделей, сопоставление результатов и выбор наиболее удачной модели для решаемой нами задачи. В результате мы получили ощутимо высокие результаты для всех выбранных моделей машинного обучения, однако наилучшим образом себя показала искусственная нейронная сеть с показателем ROC = 0,91.
Библиографическая ссылка
Татаринцев М.А., Никитин П.В., Горохова Р.И., Долгов В.И. CРАВНИТЕЛЬНЫЙ АНАЛИЗ ТЕХНОЛОГИЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ЗАДАЧ КРЕДИТНОГО СКОРИНГА // Фундаментальные исследования. 2023. № 1. С. 49-54;URL: https://fundamental-research.ru/ru/article/view?id=43419 (дата обращения: 04.07.2026).
DOI: https://doi.org/10.17513/fr.43419