



В настоящее время многие программные системы работают с входными данными, представленными в виде текстов и предложений на естественном языке (ЕЯ) [1]. В большинстве случаев это обусловлено желанием сделать интерфейс взаимодействия с компьютером более удобным и понятным человеку. А некоторые предметные области однозначно предполагают представление обрабатываемых данных на ЕЯ: системы электронного документооборота, системы анализа тональности отзывов и сообщений в социальных сетях, машинный перевод и пр. [2].
Во многом возможности разбора и понимания естественного языка компьютером ограничиваются из-за применяемых алгоритмов разбора, основанных на использовании баз знаний для конкретной предметной области – онтологий [3]. Из-за сложности синтаксиса русского языка, порождающей огромное многообразие возможных словесных конструкций, не представляется возможным построить исчерпывающее множество онтологий. Это ведет к ошибкам, неточностям и неполноте разбора. Для выполнения автоматической обработки текстов на ЕЯ вычислительная машина должна работать с некоторым формализованным представлением его смысла и структуры – семантико-синтаксической моделью. Как правило, такой моделью является граф – либо это граф зависимостей, либо граф непосредственных составляющих, либо структура, совмещающая свойства обоих описаний [4, 5].
На текущий момент существует не такое большое количество решений построения подобных моделей для предложений на русском языке [6]. Рассмотрим наиболее известные из них.
Проект Автоматическая Обработка Текста (АОТ) – проект, начатый в 1998 г. как система автоматического перевода ДИАЛИНГ [7]. По результатам проведённых исследований было написано две диссертации и ряд научных статей. По мнению разработчиков проекта, наилучшими для разбора естественного языка являются консервативные методы, основанные на описании логики всех языковых механизмов, используемых человеком.
Проект ABBYY Compreno – технология анализа и разбора текстов на ЕЯ, способная проводить полный семантико-синтаксический анализ текста [8]. По результатам проведённых исследований было опубликовано более 20 научных статей. Основываясь на полученных в проекте результатах, широте применения выпущенных приложений и компонентов для решения реальных задач, а также научной ценности публикаций, можно считать на текущий момент ABBYY Compreno наиболее значимым достижением в области обработки ЕЯ (особенно, что касается текстов на русском языке). Наиболее серьезные недостатки, которые сложно устранить сторонним пользователям, использующим технологии на базе ABBYY Compreno, – очень высокое потребление вычислительных ресурсов, сильная зависимость качества разбора от качества базы онтологий и нестабильность выделения идиоматических выражений в текстах.
Отдельный интерес представляет работа [9] на тему «Исследование методов автоматического анализа текстов и разработка интегрированной системы семантико-синтаксического анализа», выполненная в Институте системного анализа РАН. Работа датируется 2015 годом и содержит большой объём аналитической информации о текущем состоянии и развитии теории алгоритмов для семантико-синтаксического анализа естественного языка на ЭВМ. В ней убедительно подтверждается, что основным недостатком всех известных масштабных проектов по анализу текстов является крайняя зависимость качества обработки от используемого набора онтологий (шаблонов, правил). Если набор неполон, то разбор ЕЯ завершается неверно, связи в семантико-синтаксическом дереве отсутствуют или создаются неправильно.
Для решения данной проблемы предлагается применять исключительно средства машинного обучения, не использующие для выполнения семантико-синтаксического разбора базу онтологий, которая зачастую составляется вручную и не проверяется на коллизии и другие ошибки и неточности. Можно предположить, что таких простых методик и численных характеристик, полученных на основе анализа расположения слов в предложении, будет достаточно для того, чтобы правильно распознавать принадлежность группы слов к одному узлу семантико-синтаксического дерева.
В качестве главного элемента для анализа предложения (слов в предложении) выбрано отношение «свойство», являющееся узлом будущего дерева разбора. Под отношением «свойство» понимается такая связь двух слов А и Б, при которой А является описанием одного из свойств объекта Б. Например, в предложении «Зелёные вагоны неистово мчались сквозь хвойный лес» есть два таких отношения – «Зелёные вагоны» и «Хвойный лес».
Для проведения экспериментов по анализу различных естественно-языковых текстов было разработано программное приложение, выполняющее поиск словосочетаний, между которыми установлено отношение «свойство». Несмотря на то, что семантико-синтаксическое дерево, описывающее предложение на русском языке, может содержать в себе узлы, относящиеся ко множеству различных типов отношений, помимо «свойство», эксперименты показали, что простая структура данного отношения позволяет значительно сократить временные и ресурсные затраты при разборе текстов. Кроме того, для такого отношения несложно найти противоречащие друг другу примеры, рассмотрение которых крайне важно на этапе семантической обработки. Результаты экспериментов подтвердили, что несмотря на необходимость учитывать и другие типы отношений между словами, определяющим является отношение «свойство».
В качестве алгоритмической основы разрабатываемого программного прототипа подсистемы семантико-синтаксического анализа предложений на русском языке был выбран аппарат искусственных нейронных сетей (НС) [10]. Тогда поставленная задача может быть рассмотрена как задача классификации точек в n-мерном пространстве, при которой необходимо обучение НС с учителем. На сегодняшний день существует множество различных типов нейронных сетей и моделей нейронов. С учётом специфики предметной области и анализа достоинств и недостатков известных НС, для дальнейших исследований были выбраны следующие типы – многослойный персептрон и LSTM-сеть. В качестве входных данных сети используется набор параметров, полученный для соответствующей пары исследуемых слов в предложении и представленный в виде вектора действительных чисел. Выходные данные – числовой вектор «01» или «10», являющееся ответом на вопрос: «Найдено ли искомое отношение в тексте?» («01» – не найдено, «10» – найдено).
Для любых двух слов в предложении эвристически был определён следующий набор числовых параметров, которые можно получить, не используя базы онтологий:
- расстояние между словами;
- количество знаков препинания между словами;
- длина групп слов, которые получаются путем разбиения промежутка между двумя исследуемыми словами знаками препинания.
При этом задачу, решаемую нейронной сетью, можно упростить, предварительно отбрасывая пары слов, не соответствующие эталонным значениям параметров (при поиске определённого словосочетания) и не согласованные по форме.
Для определения семантического смысла анализируемой пары слов будем каждое из них сопоставлять с каким-либо семантическим классом (СК). Считается, что два слова принадлежат к одному СК, если они имеют одинаковый смысл в заданном контексте. Соответствия слов семантическим классам и определённому контексту определяются по начальной форме слов и хранятся в базе данных. Начальная форма слова и его морфологические характеристики «вычисляются» внешней подсистемой на этапе морфологического анализа. Важно учитывать, что эта подсистема также не должна использовать базу онтологий, так как поступающие из неё данные могут быть неоднозначны из-за омонимии.
При расчете количества знаков препинания важно их ранжировать. Например, количество запятых и тире между двумя словами следует воспринимать по-разному. На основании эвристических правил знаки препинания были разделены на 3 класса. Таким образом, входной вектор имеет 5 полей (элементов). Итоговая структура входного вектора приведена в табл. 1.
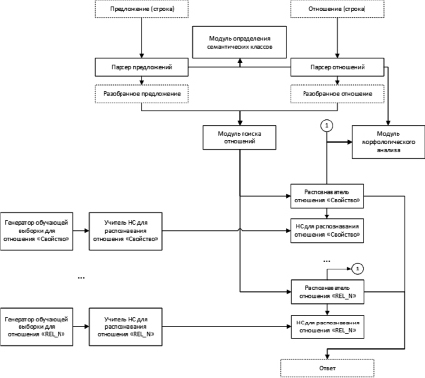
Структура программного прототипа подсистемы семантико-синтаксического анализа предложений на русском языке приведена на рисунке. Модульный принцип структуры даёт возможность учитывать различные типы вводимых пользователем отношений для дальнейшего развития и повышения интеллектуальности системы символьной обработки.
Для каждого из типов отношений используется собственный распознаватель на основе специализированного модуля с «нейронным решателем». Каждая из нейронных сетей имеет своего учителя, а каждый учитель использует собственный генератор обучающей выборки. Также каждый распознаватель имеет доступ к модулю морфологического анализа, чтобы выделять необходимые параметры, например согласование слов по форме.
Пунктирными линиями на схеме отмечены данные и их внутренние представления. Предложение и искомое отношение в виде строк поступают на обработку в соответствующие парсеры (анализаторы). Во время разбора предложения слова помечаются согласно их семантическому классу. Парсер отношений также использует модуль морфологического анализа для определения типа отношения. После определения типа отношения данные передаются в соответствующий распознаватель, который и даёт искомый ответ.
Прототип был реализован на языке программирования Java 8. Модули искусственных нейронных сетей реализованы с применением фреймворка Deeplearning4j. Данный фреймворк высокопроизводителен, поддерживает LSTM-сети и имеет большое количество параметров для настройки как самих сетей, так и процесса их обучения.
Таблица 1
Значения ячеек входного вектора
|
№ п/п |
Значение |
|
1 |
Расстояние между словами |
|
2 |
Длина групп слов, которые получаются путем разбиения промежутка между двумя исследуемыми словами знаками препинания |
|
3 |
Количество знаков препинания класса 1 (,-) |
|
4 |
Количество знаков препинания класса 2 (—:) |
|
5 |
Количество знаков препинания класса 3 (.?!;) |
Структура приложения
В качестве морфологического анализатора используется консольная программа свободного распространения Yandex MyStem [11], которая показала себя значительно лучше остальных решений по качеству анализа, особенно при работе с неизвестными словами.
Модуль определения семантических классов основан на использовании реляционной базы данных, содержащей слова в начальной форме, информацию об их принадлежности семантическим классам в определённом контексте. В качестве СУБД использована PostgreSQL 9.6. Заполнение таблиц было произведено на основе словаря синонимов Абрамова [12]. Незнакомые слова автоматически относятся к новым семантическим классам.
В качестве входных данных в экспериментах использовались первые две главы романа М.А. Булгакова «Мастер и Маргарита». Полученные данные содержали противоречия (менее 1 % от всей выборки). Для того чтобы правильно провести обучение нейронной сети, из каждой пары строк противоречащих векторов был оставлен только один. В итоге была получена выборка размером около 1500 векторов. Эксперименты проводились для различных конфигураций указанных ранее нейронных сетей. В табл. 2 показаны рассмотренные варианты, в которых была получена наилучшая точность. Под точностью понимается отношение количества правильных ответов НС к общему количеству векторов в тестовой выборке.
По результатам экспериментов многослойный персептрон показал себя гораздо лучше LSTM-сети. Оптимальное количество эпох – 100. Оптимальная топология – один скрытый слой с 20 нейронами, передаточная функция – LEAKYRELU. Для выходного слоя используется SOFTMAX. Во всех случаях наилучшая точность приближается к 90 %.
Таблица 2
Архитектуры НС, обеспечивших наилучшую точность
|
Тип НС |
Размер |
Количество эпох |
Передаточная функция |
Точность |
|
MP |
1х20 |
100 |
HARDSIGMOID |
0,8767 |
|
MP |
1х20 |
100 |
SOFTSIGN |
0,8733 |
|
MP |
1х20 |
100 |
LEAKYRELU |
0,8817 |
|
MP |
1x40 |
100 |
LEAKYRELU |
0,8700 |
|
MP |
1х20 |
200 |
LEAKYRELU |
0,8700 |
|
LSTM |
1x20 |
100 |
TANH |
0,8650 |
Также были проведены эксперименты для определения временных затрат при обработке вышеуказанных текстовых файлов на русском языке. Получение ответа от модуля нейронной сети выполнялось в среднем за 0,1 мс. Полный поиск отношения «свойство» в предложении, включая морфологический разбор и обращения к БД, требовал в среднем 1,868 мс. При этом большую часть времени (1–1,5 мс) занимала работа программного модуля Yandex MyStem и обмен данными с ним. Необходимо заметить, что это время можно значительно уменьшить, посылая предложения на обработку большими группами.
Таким образом, по итогам первого этапа исследований можно сделать следующие выводы. Относительно небольшого количества данных, получаемых на основе анализа взаимного расположения слов в предложении (длина вектора для описания обнаруженной пары «взаимосвязанных» слов – пять вещественных чисел), и никоим образом не опирающегося на большие (иногда огромные) и трудоёмкие онтологии, достаточно, чтобы получить точность разбора текста на русском языке, близкую к 90 %. Скорость принятия решения по одной паре слов очень высокая – до 10 тысяч проверок в секунду на подготовленных данных. При этом можно ожидать ещё лучшей точности при разборе предложений с учётом более сложных по структуре отношений, чем «свойство». Это обусловлено тем, что они будут порождать меньшее количество противоречивых данных, предоставляя при этом больше различных критериев для принятия решения.
Если точности в 90 % недостаточно для качественной обработки текстов на естественном языке, например, в системах повышенной надёжности, то данную подсистему можно использовать на предварительном этапе анализа символьной информации подобной высокопроизводительной специализированной системы [13]. Такой подход значительно сократит как время предобработки текста на первом этапе, так и время «прецизионного» анализа текста в основном компоненте системы, основанном на базе проверенной и достоверной онтологии конкретной предметной области, отлаженной специалистами-экспертами в области инженерии знаний.
Библиографическая ссылка
Мельцов В.Ю., Нечаев А.А. СЕМАНТИКО-СИНТАКСИЧЕСКИЙ АНАЛИЗ ПРЕДЛОЖЕНИЙ НА РУССКОМ ЯЗЫКЕ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ // Фундаментальные исследования. 2017. № 11-2. С. 306-310;URL: https://fundamental-research.ru/ru/article/view?id=41940 (дата обращения: 02.07.2026).