



Одним из источников информации, необходимой для принятия решений, являются информационно-вычислительные сети. По мнению ряда специалистов, в настоящее время объем информации в интернете удваивается каждые полтора года. Соответственно, возрастает сложность извлечения данных и поиска необходимой (релевантной) информации. Это усугубляется распределённостью самих сетей и неоднородностью описаний данных. Одним из примеров может служить организация поиска и обработки данных о необходимых для того или иного вида деятельности потенциальных сотрудниках [3, 8–9]. В качестве другого примера с характерной проблематикой можно привести поиск и сравнение информации о товарах, анализ отзывов об этих товарах и услугах в области электронной коммерции [1, 7, 13].
Проблеме обработки данных посвящено много исследований [1–13]. Вопросы использования семантического поиска и семантической паутины, веб-онтологий, дескриптивной логики рассмотрены в трудах Т. Бернса Ли, Ф. Баадера, С. Колуччи, Т.А. Гавриловой, Б.Е. Федунова, В.А. Виттиха, С.В. Смирнова, Л.Р. Черняховской и др.
Вопросам разработки и применения информационных моделей данных, моделей представления знаний, проектирования глобальных распределённых информационных систем с использованием слабоструктурированных данных посвящены труды Р. Филдинга [11], В.В. Миронова, Н.И. Юсуповой, О.Н. Сметаниной [1–2, 4–7, 10, 13] и др. Вопросами выявления особенностей представления слабоструктурированных данных занимаются многие исследователи, в частности О.В. Журавлева, В.И. Миронов, К.Ю. Лисовский, В.И. Никитин, Н.И. Юсупова и др. Следует отметить, что в публикациях отражены исследования в области создания интеллектуальных информационных систем, баз данных и знаний, извлечения слабоструктурированных данных, интеграции разнородных баз данных с возможностью формирования запросов к ним, информационной поддержки принятия решений с использованием интеллектуальных технологий. Однако до настоящего времени недостаточно проработанным остается вопрос глобально распределённой обработки слабоструктурированных данных с помощью микроразметки с использованием гибридного подхода, когда данные могут быть представлены в различных форматах.
Статья отражает результаты исследования, целью которого является повышение эффективности (информативности и полноты) глобально распределённой обработки слабоструктурированных данных и знаний на основе разработки подхода с использованием микроразметки, включающего архитектуру, алгоритм и его программную реализацию.
Методы представления слабоструктурированных данных и вопросы использования онтологий для поиска
Слабоструктурированные данные обладают рядом особенностей [7, 9], в частности не существует фиксированной схемы данных; нет чёткого различия между данными и их схемой; отсутствует строгая типизация; изменение схемы данных представляет собой рутинную операцию, сравнимую с внесением изменений в данные; объем данных сравним со сложностью их схемы; схема данных является описывающей, а не предписывающей и может быть получена из самих данных; полное знание схемы данных не является необходимым для построения запросов, возможны запросы, полностью игнорирующие схему данных.
Среди способов представления и обработки подобной информации отмечают [7]: метод представления многопризнаковых данных мультимножествами, например, для распознавания печатных букв; табличный способ представления данных, применяемый при решении задач классификации с помощью нейронных сетей и т.д.; представление с использованием логической парадигмы, например, на логическом языке программирования Datalog и дедуктивные СУБД; метод фазовых траекторий для обработки мультимодальной информации; процедурное представление данных в виде набора правил; декларативное представление в виде базы данных либо базы знаний (хранилище информации).
Существуют различные направления использования онтологий и технологий Semantic Web [7, с. 38], например: улучшение релевантности запросов поисковыми системами за счёт семантической разметки; полнотекстовый поиск с учётом морфологии и опечаток; организация семантического доступа к базам данных; реализация семантических фильтров; поиск подходящего прецедента и т.д.
Постановка задачи поиска и обработки информации для поддержки принятия решений
Будем использовать декларативное представление слабоструктурированных данных, в частности онтологии (представление с использованием языков LOOM, Cycl, KL-One и ряда других) и веб-онтологии (с использованием OIL, RDF, OWL) [3–9].
Предлагаемый подход основан на технологиях SemanticWeb с применением микроразметки. Ряд технологий стека Semantic Web не смогли найти широкого практического применения, однако представляют академический интерес. Ряд технологий и их модификаций, таких как микроразметки, нашли своё применение в ряде областей, например при построении социального графа в Facebook с использованием протокола OpenGraph, либо микроразметки информации о бизнесе для автосервисов.
В формулировке постановки рассматриваемой задачи предполагается, что:
– Дано: Мiri=<miri1, miri2, …, mirin> – множество глобально распределённых источников данных/информации, содержащих сведения, относящиеся к одной общей предметной области. Как правило, это веб-ресурсы, содержащие слабоструктурированные данные.
– Необходимо разработать: P=<Mod, Tex, Arx, Alg, Mex> – подход глобально распределённой обработки слабоструктурированных данных, включающий модели (Mod), технологии (Tex), архитектуры (Arx) и алгоритмы (Alg), программная реализация (Pr) которого c использованием механизма (Mex) позволит по поисковому запросу получить наиболее релевантный результат поиска (Rez), на основании извлечённых данных из источников. Полученные результаты поиска применяются для поддержки принятия решений. Один из возможных вариантов расчёта релевантности Rez – отношение количества релевантной (т.е. соответствующей запросу) результатов к общему числу результатов запроса.
Предполагается, что работоспособность предложенного подхода должна быть проверена с использованием программной реализации в конкретной предметной области Rez=<Miri, Pr(P)>.
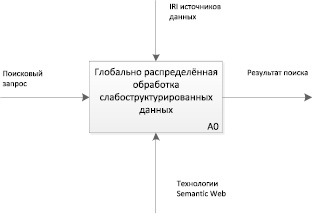
Рис. 1. Функциональная модель глобально распределённой обработки слабоструктурированных данных
Функциональная модель процесса глобально распределённой обработки слабоструктурированных данных представлена на рис. 1. В качестве механизма используются технологии Semantic Web.
Гибридный подход к организации глобально распределённой обработки слабоструктурированных данных
Для решения рассматриваемой задачи предлагается гибридный подход на основе компиляции и адаптации существующих [12, с. 30; 11, с. 94], в которых используются технологии Semantic Web, в т.ч. форматы микроразметки.
Среди основных положений предлагаемого подхода можно отметить следующие: процесс обработки базируется на трёхуровневой архитектуре (клиент, веб-сервер и сервер базы знаний/базы данных) как модификации архитектуры клиент-сервер; сервер не хранит состояние представления; применяется единообразный интерфейс доступа к ресурсам, основанный на использовании IRI (как расширения URI); рассмотрение процесса обработки данных осуществляется на трёх уровнях абстракции (прикладной уровень, где осуществляется поиск (управляется пользователями); промежуточный уровень (использование медиаторов), где реализуется сбор и консолидация данных; на этом уровне разрабатывается веб-онтология, которая объединяет различные описания (управляется экспертами по знаниям, онтологистами); уровень источников данных (управляется администраторами сайтов); предполагается использование микроразметки, т.е. внедрение в HTML дополнительных тегов/атрибутов, чтобы указывать веб-приложениям, в первую очередь поисковым роботам, что именно находится в том либо ином элементе (особая роль отведена вопросам применения RDFa Lite, микроданных и микроформатов в микроразметке); использование языка Semantic Web Rules Language (SWRL) для представления правил поддержки принятия решений.
Эти положения позволяют обеспечить: адаптивность, гибкость, лёгкость в изменении в связи с появлениями новых требований; унификацию доступа к разнородным источникам данных за счёт реализации семантической интеграции с помощью веб-онтологий; подготовку данных для формирования правил поддержки принятия решений; надёжность (за счёт отсутствия необходимости сохранять информацию о состоянии клиента, которая может быть утеряна); масштабируемость; простоту доступа.
Архитектура глобально распределённой обработки слабоструктурированных данных с использованием микроформатов
Архитектура глобально распределённой обработки слабоструктурированных данных с использованием микроразметки представлена на рис. 2.
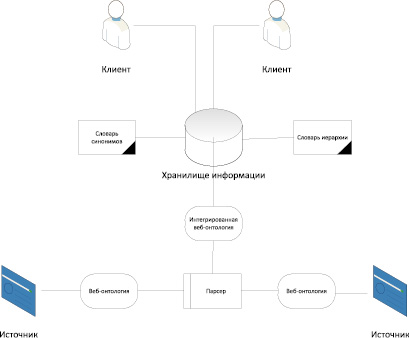
Рис. 2. Архитектура глобально распределённой обработки слабоструктурированных данных с использованием микроформатов
Компонентами архитектуры являются: распределённые источники информации, парсер, веб-онтологии, база знаний предметной области и механизм поиска в базе знаний (БЗ) (табл. 1).
Алгоритм распределённой обработки данных
Для обработки слабоструктурированных данных разработан специальный алгоритм, показанный на рис. 3.
При создании алгоритма учтена предложенная архитектура и некоторые из её аспектов. Алгоритм реализован с помощью языка программирования Ruby и фреймворка RubyOnRails, gem RDFa, Machinize, Nokogiri.
Детальное описание алгоритма глобально распределённой обработки слабоструктурированных данных позволяет выявить некоторые особенности, которые представлены в табл. 2.
Данный алгоритм может быть применён для поддержки принятия решений, например при управлении ресурсами сложных систем. Для этого используются язык SWRL, позволяющий формировать правила принятия решений на основе информации из интегрированной веб-онтологии, которая получена путём извлечения информации из глобально распределённых источников информации.
Пример использования подхода для извлечения и поиска информации о компетенциях потенциальных сотрудников
Применение предлагаемого подхода к распределённой обработке слабоструктурированных данных о компетенциях потенциальных сотрудников (в первую очередь молодых профессионалов и студентов старших курсов) осуществлялось в рамках проекта ПрофПорт.рф [14]. Информация извлекалась из блогов и из портфолио. В них она представлена с использованием микроразметки, в частности с применением микроформата hCard и разработанной онтологии [3, 8–9].
Таблица 1
Компоненты архитектуры глобально распределённой обработки слабоструктурированных данных с использованием микроформатов
|
№ п/п |
Компонент |
Назначение компонента |
|
1 |
Глобально распределенные источники информации |
Содержат информацию, относящуюся к одной общей предметной области. Описаны с использованием микроразметки (возможно различные словари (веб-онтологии), но схожие и заранее известные) |
|
2 |
Веб-онтология |
Используется для семантического описания источника |
|
3 |
Парсер |
Извлекает информацию на основе описаний в веб-онтологиях |
|
4 |
Интегрированная веб-онтология |
Представлена с использованием RDF(S)/OWL DL, позволяет свести разнородность описаний в однородность, включает: сопоставление используемых форматов описания; словарь синонимов; словарь иерархии |
|
5 |
База знаний предметной области |
Пополняется из источников с использованием общей веб-онтологии; в том содержит правила принятия решений, представленные с помощью языка SWRL |
|
6 |
Механизм поиска в БЗ |
Реализуется с использованием языка SPARQL. Также возможно применение OWL-запросов, например, с помощью RICE |
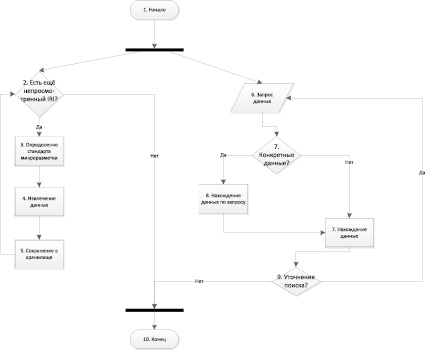
Рис. 3. Блок-схема алгоритма глобально распределённой обработки слабоструктурированных данных
Таблица 2
Особенности алгоритма
|
№ п/п |
Содержание |
Особенности |
|
1 |
Начало алгоритма |
Следующие шаги (2 и 6) выполняются параллельно |
|
2 |
Берётся очередной источник информации. Если есть ещё не загруженный, то следующий шаг. Иначе завершение (шаг 10) |
IRI источников информации известны заранее. В дальнейшем можно дополнить алгоритм подпрограммой, которая находит необходимые IRI |
|
3 |
Определяется, какой стандарт микроразметки применяется. Подгружается необходимый парсер |
Могут использоваться различные стандарты микроразметки – микроданные, RDFa Lite и т.д. |
|
4 |
Производится извлечение парсером необходимых данных |
Данные извлекаются в соответствии со стандартом микроразметки |
|
5 |
Происходит сохранение извлечённых данных в хранилище информации. Идём на шаг 2 |
Сохранение происходит с учётом отношений синонимии между различными классами и отношения иерархии (наследования) |
|
6 |
Происходит запрос для получения необходимых данных. Смотрится – запрос производится по конкретным данным либо по поисковой фразе? |
Конкретные данные выбираются пользователем из списка. Поисковая фраза не привязана к списку и может быть условно-произвольной |
|
7 |
Если по конкретным данным, то ищется соответствие по этим данным. С учётом отношения синонимии и иерархии |
Эти данные используются для дальнейшей поддержки принятия решений |
|
8 |
Если по поисковой фразе, то производится сначала нахождение всех данных, которые соответствуют этой поисковой фразе. Для этих происходит уже поиск других данных, связанных с этими данными (например, данные о компетенциях и данные о сотрудниках) |
Эти данные используются для дальнейшей поддержки принятия решений |
|
9 |
Если происходит поиск в уже найденных данных, то идём на шаг 6. Иначе – шаг 10 |
|
|
10 |
Завершение алгоритма |
Таблица 3
Фрагмент базы знаний, представленной правилами на языке SWRL
|
Правила принятия решений на SWRL |
Описание на естественном языке |
|
бытьПодтверждённой (?competency, ?student) < принадлежатьПрофилю (?competency, ?profile) Профиль (?profile) ПрофессиональнаяКомпетенция (?competency) иметь Профиль (?student,?profile)Обучающийся (?student) |
Если компетенция ?competency принадлежит профилю компетенций ?profile обучающегося ?student, то она является освоенной этим обучающимся |
|
состоятьИз (?kmv, ?competency) < ПрофессиональнаяКомпетенцияИзПС (?competency) ПКМаксимальныйПриоритет (?competency) |
Если профессиональная компетенция ?competency из профессионального стандарта имеет максимальный приоритет в XПРОФПРИОР, то включить её в компетентностную модель выпускника ?kmv |
Извлечённая информация в дальнейшем использовалась для поддержки принятия решений, в том числе при управлении учебным процессом. Приведённый фрагмент базы знаний, показанной в табл. 3, представлен правилами и демонстрирует возможность на основе входных данных и механизма поиска найти решение. Правила созданы на основе языка SWRL.
Программная реализация предложенного подхода для данного примера демонстрирует возможность глобально распределённой обработки слабоструктурированных данных, в частности, осуществлять поиск информации о потенциальных сотрудниках по компетенциям. На рис. 4 приведён пример интерфейса разработанной программной реализации. В частности, в приведённом на рисунке примере поиск осуществлялся по компетенции «Веб-разработка». При этом учтены синонимы «Веб-программирование», а также ряд компетенций, которые являются частными случаями веб-разработки («Разработка веб-приложений на CMF Drupal» и т.д.). Применяемые решения позволяют повысить, в том числе релевантность получаемой в результате поиска информации. Реализация предлагаемых решений выполнена в виде модулей CMF Drupal 7. В качестве хранилища из Sesame и Virtuoso было выбрано последнее. Для работы с RDF и OWL выбрана библиотека ARC2. Сравнение предлагаемого подхода на примере данной предметной области показало, что данный подход повышает полноту и релевантность получаемых результатов за счёт извлечения данных из различных источников, а также учёта отношения синонимии, иерархии и возможности уточнения в результатах поиска, по сравнению с подходами, которые не используют эти возможности.
Направления развития исследований
При проведении дальнейших исследований планируется расширить используемые стандарты микроразметки и реализовать извлечение данных с использованием стандарта JSON-LD. Это позволит применять предложенный подход при создании мобильных приложений.
Дальнейшее проведение исследований также позволит применять полученные результаты в прикладной области электронной коммерции, например поиск и сравнение товаров, отзывов об этих товарах и услугах и т.д., в том числе с использованием микроформата hReview.
Заключение
В рамках данной статьи реализован подход к организации глобально распределённой обработки данных для поддержки принятия решений, который отличается от существующих тем, что использует микроразметку, IRI вместо URI, добавляет возможность делать не только SPARQL-запросы, но и применять OWL-запросы с использованием, например, RICE. Это позволяет извлекать слабоструктурированные данные, а также повысить релевантность поиска за счёт использования семантической разметки (микроразметки) и подготовить возможность использовать эти данные для поддержки принятия решений.
Разработаны постановочная и функциональная модели для формализации постановки задачи.
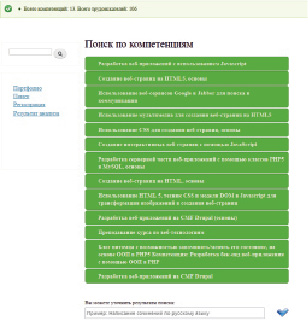
Рис. 4. Пример поиска подходящих специалистов по компетенциям
Предложенный подход включает архитектуру для построения информационной системы глобально распределённой обработки данных для поддержки принятия решений с использованием микроразметки. Сами правила поддержки принятия решений описываются с использованием SWRL. Это позволяет привязать правила поддержки принятия решений к извлечённой информации.
Алгоритм распределённой обработки данных для поддержки принятия решений с использованием микроразметки подразделяется на два алгоритма, один из которых позволяет извлекать слабоструктурированные данные по указанным IRI, определять формат микроразметки, пополнять хранилище информации, а другой – производить поиск по полному совпадению, поисковой фразе, а также уточнять результаты поиска. Алгоритмы реализованы с помощью языка программирования Ruby и фреймворка RubyOnRails, gem RDFa, Machinize, Nokogiri.
Данные решения применены в рамках проекта ПрофПорт.рф для извлечения информации о компетенциях молодых профессионалов и студентов старших курсов, а также дальнейшего поиска. Реализация предлагаемых решений выполнена в виде модулей CMF Drupal 7, с использованием RDF-хранилища Virtuoso, и библиотеки ARC2. Проведённый анализ эффективности предлагаемых решений показал, что их применение повышает полноту и релевантность результатов поиска.
Исследования частично поддержаны грантами РФФИ 16-07-00773, 15-07-01565 и 14-07-00811.
Библиографическая ссылка
Галямов А.Ф., Ризванов Д.А., Сметанина О.Н., Юсупова Н.И. МОДЕЛИ И АЛГОРИТМЫ ГЛОБАЛЬНО РАСПРЕДЕЛЁННОЙ ОБРАБОТКИ СЛАБОСТРУКТУРИРОВАННЫХ ДАННЫХ НА ОСНОВЕ МИКРОРАЗМЕТКИ ДЛЯ ПОДДЕРЖКИ ПРИНЯТИЯ РЕШЕНИЙ // Фундаментальные исследования. 2017. № 1. С. 27-35;URL: https://fundamental-research.ru/ru/article/view?id=41311 (дата обращения: 20.06.2026).