



Предложенные теоретические положения и методологические аспекты анализа и моделирования текстов [3] позволяют обобщить основные принципы для решения задач анализа текстов и формализовать выбор моделей и методов обработки текстов при решении конкретных прикладных задач. К активно развивающимся направлениям анализа и обработки текстов относятся задачи, связанные с обеспечением работы информационно-поисковых и информационно-аналитических систем, а также систем обеспечения информационной безопасности (рис. 1).
Во многих прикладных системах, связанных с обработкой информации, находят отражение задачи анализа и обработки текста: задачи кластеризации, классификации и идентификации. Специфика решения конкретной задачи зависит от выбранных методов и рассматриваемых данных, а также направленности системы. Приведем некоторые направления и примеры задач, возникающие в практических информационных системах.
А.I. Кластеризация. Разделение данных на отдельные непересекающиеся группы по заданному параметру. Предварительная обработка большого объема данных без какой-либо дополнительной информации (возможен случай, когда рассматриваются не только текстовые данные).
А.II. Классификация. Отнесение документов к известным группам, при котором каждый текст может принадлежать нескольким классам (нечеткая классификация). Рассмотрение большого текста, в котором требуется выделить отдельные части, близкие по некоторым признакам (тематике, стилистическим особенностям).
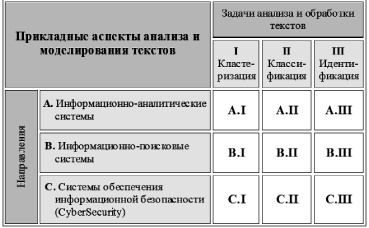
Рис. 1. Прикладные аспекты анализа текстов
А.III. Идентификация. Выявление и проверка различных характеристик текста, проверка возможности использования их в качестве идентификационных признаков. Идентификация авторства и стиля художественных текстов.
В.I. Кластеризация. Разделение документов по группам в специализированных информационно-поисковых системах. Кластеризация патентной документации и заявочных материалов, извлекаемых из разных патентных баз.
В.II. Классификация по предметным тематическим категориям (категоризация) – отнесение неизвестного текста к одной или нескольким тематическим категориям. Классификация по тематике сообщений в новостной ленте. Определение эмоциональной окрашенности текстов в рекомендательных системах.
В.III. Идентификация. Определение признаков автоматического перевода на основе выявления особенностей написания текстов на родном языке. Проблемы переводного плагиата и заимствования. Определение ключевых слов, терминов и фраз с целью автоматического аннотирования и реферирования
С.I. Кластеризация. Анализ текстов в социальных сетях, рассмотрение потока текстов глобальной сети для выявления авторских характеристик и обнаружения предпосылок к нежелательным действиям. Определение эмоционального состояния автора. Определение исходного языка текста (переводной или оригинальный текст)
С.II. Классификация по различным признакам, когда имеет место отнесение текста к некоторым классам по конкретному заранее заданному признаку, такому, как стиль или жанр текста, временные характеристики и т.п. Задача классификации Интернет-сообщений (комментариев, писем, сообщений). Определение эмоционального состояния автора текстовых сообщений.
С.III. Идентификация. Определение особенностей написания программ как по исходному, так и по бинарному коду. Идентификация авторов исходных кодов программ. Проверка истинности авторства программ в учебных целях.
Примеры практической реализации
Решение задачи нечеткого разделения пользователей, входящих в некоторое социальное сообщество, основано на выявлении характерных признаков, извлеченных из их сообщений [4]. Практическая реализация выполнялась с помощью исследовательского пакета KNIME [1], разработанного в одном из университетов Германии и доступного для свободного использования в учебных и исследовательских целях, данные были получены со страницы Slashdot. Исходное подмножество содержало около 140,000 комментариев к 500 заметкам от приблизительно 24,000 пользователей. Кластеризация осуществлялась по методу, основанному на алгоритме нечеткой кластеризации Fuzzy c-means (FCM).
Результат полученной кластеризации для десяти кластеров приведен на рис. 2. Кластеризация проводилась по параметрам: «авторитетность» пользователя-автора сообщений, отражающая степень соответствия тематике и «ссылочность» (оценка последователей). Также учитывалась положительная/отрицательная оценка каждого пользователя на основе употребляемых им слов. Размер получившегося кластера показывает размер радиуса окружности на диаграмме, насыщенность цвета отражает положительность/отрицательность объектов в кластере.
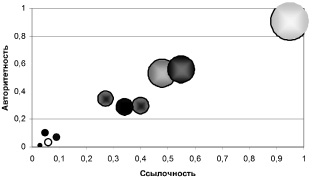
Рис. 2. Результат кластеризации пользователей в социальном сообществе
В результате кластеризации выделяется один кластер с высокой степенью авторитетности и ссылочности, при этом его объекты обладают наибольшей положительностью. Выделяются несколько кластеров активных пользователей в центре схемы с высокой оценкой авторитетности и ссылочности. Среди них встречаются кластеры и с положительными и с отрицательными оценками.
Для задачи категоризации (классификации текстов на естественном языке по тематическим (предметным) категориям из заранее определенного набора) были рассмотрены стандартные методы классификации, применяемые к предложенным моделям текста на основе спектров различной детализации.
Система состоит из модуля обработки текста документа и создания на его основе N-граммной древовидной модели документа и построения спектров различной детализации [5]. Модуль оценки эффективности разработанной модели текста и тестирования результатов ее применения с различными классификаторами построена на основе статистического программного пакета KNIME.
Была проведена оценка классификации при рассмотрении спектров N-грамм разного уровня, при этом эффективность классификаторов оценивалась для четырех уровней детализации спектров, равных соответственно 2, 3, 4 и 5, результаты приведены в таблице. Эффективность классификатора определялась как процент верно классифицированных документов от их общего числа.
Практическая реализация методов идентификации авторов текстов исходных кодов рассматривалась в рамках систем для обеспечения кибербезопасности и информационной безопасности. В понятие «кибербезопасность» (CyberSecurity) входит широкий спектр практических приемов, инструментов и концепций, тесно связанных с технологиями информационной и операционной безопасности.
При распространении текстов в электронном виде с использованием глобальных сетей большое значение приобретают задачи обеспечения безопасности и предотвращения так называемых киберпреступлений. Одним из направлений развития кибербезопасности является подраздел, который занимается задачами обработки объектов, представленных в текстовом виде (документы, письма, сообщения, тексты программ и т.д.). С текстовыми объектами связаны такие кибернарушения, как распространение спама и вирусов, террористические угрозы и многие другие [9, 10].
Результаты категоризации
|
Классификатор |
Уровень детализации |
|||
|
2 |
3 |
4 |
5 |
|
|
Support Vector Machines (SVM) |
1,00 |
1,00 |
0,94 |
0,83 |
|
Probabilistic Neural Network (PNN) |
0,97 |
0,78 |
0,53 |
0,50 |
|
Multilayer Perceptron (MLP) |
0,94 |
0,97 |
0,97 |
1,00 |
|
Fuzzy Rules (FR) |
0,89 |
0,75 |
0,61 |
0,56 |
|
Decision Trees (DT) |
0,86 |
0,94 |
0,78 |
0,31 |
|
Naive Bayes (NB) |
0,25 |
0,30 |
0,33 |
0,33 |
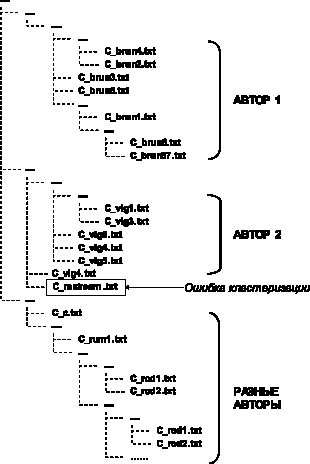
Рис. 3. Фрагмент кластеризации текстов программ
Можно выделить основные задачи анализа текстовых данных в рамках обеспечения кибербезопасности:
● определение авторства литературных и научных текстов;
● выявление характерных признаков интернет-сообщений (письма по электронной почте, записи в блогах, комментарии и т.п.);
● определение авторства программных кодов [7];
● и др.
Была проверена возможность использования методов сжатия и Колмогоровской сложности [8] для кластеризации текстов исходных кодов и идентификации их авторов. Фрагмент построенного иерархического разбиения по классам, соответствующим разным авторам, приведен на рис. 3. Необходимо также отметить, что при кластеризации текстов исходных кодов кластеры, относящиеся к разным языкам программирования, выделяются на самом верхнем уровне и уже в каждом из них происходит кластеризация по авторам программ.
Рассмотрены некоторые прикладные аспекты построения систем анализа и обработки текстовых данных, опирающиеся на предложенную методологию, которая учитывает основные принципы анализа текстов: принцип системного представления текстов, принцип нечеткой логики и принцип обучающихся систем. Однако рассмотренные задачи не ограничивают сферы применения предложенной методики. К другим проблемам информационно-поисковых систем можно отнести такие задачи, как фильтрация и рубрикация документов, автоматическое аннотирование и сегментирование текстов и др. Для успешного решения подобных задач необходимо предусмотреть использование лингвистических и онтологических знаний [2, 6]. Еще одним направлением развития может служить рассмотрение таких текстовых данных, как тексты патентной документации и заявочных материалов, текстовые данные, создаваемые при использовании различными базами знаний и системами документооборота в организациях и на предприятиях.
Рецензенты:
Баландин Д.В., д.ф.-м.н., профессор, заведующий кафедрой численного и функционального анализа, Нижегородский государственный университет им. Н.И. Лобачевского, г. Нижний Новгород;
Федосенко Ю.С., д.т.н., профессор, заведующий кафедрой «Информатика, системы управления и телекоммуникаций», Волжский государственный университет водного транспорта, г. Нижний Новгород.
Библиографическая ссылка
Ломакина Л.С., Суркова А.С. ПРИКЛАДНЫЕ АСПЕКТЫ КОНЦЕПТУАЛЬНОГО АНАЛИЗА И МОДЕЛИРОВАНИЯ ТЕКСТОВЫХ СТРУКТУР // Фундаментальные исследования. 2015. № 7-3. С. 540-544;URL: https://fundamental-research.ru/ru/article/view?id=38775 (дата обращения: 11.07.2026).