



Архивы медицинских данных, находящиеся в распоряжении различных медицинских учреждений, содержат огромный запас сведений о различных случаях каждого конкретного заболевания. Извлечение «скрытых» закономерностей из массива данных – одна из задач многих исследований медицинской тематики. Для решения таких задач применяются методы автоматического анализа, при помощи которых приходится практически добывать знания из «завалов» информации.
Термин Data Mining часто переводится как добыча данных, раскопка данных или «извлечение зерен знаний из гор данных». Технологию Data Mining достаточно точно определяет один из основателей этого направления Григорий Пиатецкий-Шапиро: «Data Mining – это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности» [1].
Data Mining – совокупность различных методов обнаружения знаний. Выбор метода часто зависит от типа имеющихся данных и от того, какую информацию необходимо получить. Вот некоторые из них: классификация, кластеризация, ассоциация (объединение), анализ временных рядов, нейронные сети, прогнозирование и анализ временных рядов и т.д.
Технология Data Mining применяется практически везде, где возникает задача автоматического анализа данных. Основные сферы применения технологии Data Mining: наука, бизнес, исследования для правительства и Web-направление. Широкое распространение эти методы получили также в медицинских исследованиях.
Известно много экспертных систем для постановки медицинских диагнозов. Они построены главным образом на основе правил, описывающих сочетания симптомов различных заболеваний. С помощью таких правил узнают не только, чем болен пациент, но и как его нужно лечить [1]. Правила помогают выбирать средства медикаментозного воздействия, определять показания (противопоказания), ориентироваться в лечебных процедурах, создавать условия наиболее эффективного лечения, предсказывать исходы назначенного курса лечения, изучать причины и механизмы возникновения различных патологий, исследовать эффективность хирургического вмешательства и т.п. Технология Data Mining позволяет обнаруживать в медицинских данных шаблоны, которые составляют основу указанных правил.
Метод Data Mining в медицинских исследованиях применяли разные авторы: Гудинова Ж.В. Применение Data Mining (Обнаружение полезных знаний в базах данных) как основа исследований и управления в сфере охраны здоровья населения и среды обитания [5]; А.В. Кузнецова, О.В. Сенько, Возможности использования методов Data Mining при медико-лабораторных исследованиях для выявления закономерностей в массивах данных [6]; Дзюра А.Е., Берестнева Е.В. Применение Data Mining в медико-психологических исследованиях [7].
Поиск скрытых закономерностей в медицинских данных. Исходный массив данных нашей задачи – матрица значений медицинских показателей, сформированная в НИИ курортологии г. Томска (рис. 1). Объекты исследования – дети, страдающие разной формой ожирения. Цель нашего исследования – выявление закономерностей (определение групп детей, имеющих схожий результат лечения) после проведения лечения.
В настоящее время на рынке программного обеспечения существует огромное разнообразие программных продуктов, реализующих самый разнообразный спектр методов Data Mining. Разработчики универсальных статистических пакетов, в дополнение к традиционным методам статистического анализа, включают в пакет определенный набор методов Data Mining. Это такие пакеты, как SPSS(SPSS, Clementine), Statistica (StatSoft), SAS Institute (SAS Enterprise Miner). Некоторые разработчики OLAP-решений также предлагают набор методов Data Mining, например семейство продуктов Cognos. Есть поставщики, включающие Data Mining решения в функциональность СУБД: это Microsoft (Microsoft SQL Server), Oracle, IBM (IBM Intelligent Miner for Data).
Для реализации поставленной задачи был использован достаточно популярный пакет Statistica, разработчиком которого является компания StatSoft. Компанией StatSoft была разработана целая система Statistica Data Miner, реализующая технологию Data Mining [3, 5]. Данная система спроектирована и реализована как универсальное всестороннее средство анализа данных (от взаимодействия с различными базами данных до создания готовых отчетов), реализующее так называемый графически-ориентированный подход. Система Statistica Data Miner подходит для выявления скрытых правил и закономерностей, проведения углубленных исследований, где «не работают» классические методы математической статистики. Авторами разработан алгоритм выявления скрытых закономерностей, схема которого представлена на рис. 2. Алгоритм был апробирован при решении подобных прикладных исследовательских задач [2]. Исходный массив данных задачи, представленной в данной статье, – матрица значений Xnm медицинских показателей, сформированная в НИИ курортологии г. Томска (n – количество пациентов (n = 269); m – число медицинских показателей (m = 111).
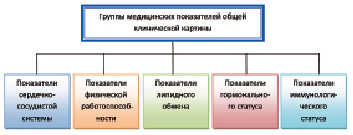
Рис. 1. Группы медицинских показателей
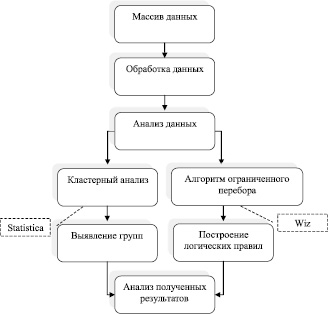
Рис. 2. Схема алгоритма выявления скрытых закономерностей
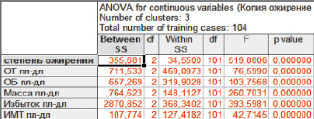
Рис. 3. Результат дисперсионного анализа
Метод кластерного анализа [1, 4] позволяет разбивать множества исследуемых объектов и признаков на однородные группы (кластеры). Для реализации процедуры кластерного анализа существует несколько методов, авторами был использован наиболее распространенный метод k-средних, целью которого является разбиение объектов на k кластеров.
Принципиальное отличие метода k-средних от иерархического кластер-анализа заключается в том, что исследователю необходимо изначально определить число кластеров, на которое требуется разбить изучаемую совокупность. Соответственно, желательно еще до начала анализа иметь гипотезу о структуре исследуемой совокупности. Авторы статьи проводили кластер-анализ для k = 3, 4, 5. Анализ результатов специалистами НИИ курортологии показал, что наилучший результат показывает кластер-анализ при k = 3.
В дисперсионном анализе межгрупповая дисперсия сравнивается с внутригрупповой дисперсией для принятия решения, являются ли средние для отдельных переменных в разных совокупностях значимо различными. Исходя из уровней значимости (p-value), все выбранные авторами переменные являются значимыми при решении задачи о распределении объектов по кластерам (рис. 3).
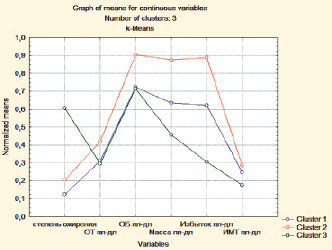
Рис. 4. График средних значений кластеров
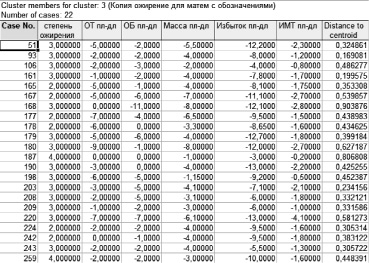
Рис. 5. Объекты кластера 3
Одним из способов определения кластеров является проверка средних значений для каждого кластера и для каждого измерения (рис. 4).
Анализируя график, можно сделать вывод, что пациенты, входящие в Cluster 3, получили лучшие результаты при лечении. Это показывают переменные: масса тела, избыток массы тела (%) и индекс массы тела.
В таблице на рис. 5 представлены объекты, входящие в кластер 3. В основном это пациенты с 3 и более степенью ожирения. Столбцы со значениями указывают на то, каких они достигли результатов при лечении.
Алгоритм ограниченного перебора. С целью обработки клинико-лабораторных показателей авторами был использован алгоритм ограниченного перебора (с применением пакета Wiz Why). Поиск логических правил осуществлялся для клинико-лабораторных показателей до лечения, так и для значения разности показателей до лечения и после лечения. В частности, были получены правила, характеризующие показатели пациентов до лечения к индексу массы тела после лечения. Эти правила позволяют понять, на каких пациентов и с какими признаками лечение подействовало эффективнее.
Для пояснения полученных правил, наиболее подробно рассмотрено правило № 5:
If IgM do is 0,80 ... 2,10 (average = 1,43)
and Lizocim do is 36,00
Then
IMT p-do is not more than -1,08
Rule’s probability: 0,909
The rule exists in 10 records.
Significance Level: Error probability < 0,01
Это правило представляет собой конъюнкцию двух высказываний:
If IgM do is 0,80 ... 2,10 (average = 1,43) – если концентрация иммуноглубина M до лечения от 0,80 до 2,10, и Lizocim do is 36,00 активность лизоцима в сыворотке крови до лечения равняется 36, то IMT p-do индекс массы тела в результате проведенного лечения уменьшается более чем на 1,08.
Запись Rule’s probability: 0,909 означает точность правила в данном случае равной 0,909. Следующая запись The rule exists in 10 records характеризует множество объектов, для котрых справедливо рассматриваемое правило, а запись Significance Level: Error probability < 0,01 касается статистической оценки уровня значимости.
В системе предусмотрена визуализация любого правила. Для этого надо позиционировать курсор на одном из его условий и щелчком правой кнопки мыши вызвать контексное меню, где выбрать «Rule Chart…». В окне отобразится диаграмма, иллюстрирующая отдельные компоненты правила (рис. 6).
Левая часть окна содержит правило в текстовом режиме. Правая часть – визуализация правила. Зеленая полоса показывает долю объектов, обладающих целевым значением, красная полоса иллюстрирует пропущенные объекты, белые разделы – другие объекты в этом поле. Длина полосы соответствует доле таких объектов.
Оценить информативность признака можно при помощи таблицы «Field Index», где перечисляются признаки, участвующие в полученных правилах, и приводится список их номеров. Анализируя табл. 1, можно сказать, что показатели: DV.PR. do, OXC do, TTG(0,23-3,4) do имеют наибольшее значение при выявлении закономерностей, а в табл. 2 показатели: DV.PR.р-do, CIK p-do, Kortizol p-do, OL p-do.
На основе анализа логических правил, представленных в приложении В, можно сделать вывод о том, что уменьшение или увеличение определенных значений показателей способствует лучшему результату при проведении лечения и наоборот, улучшение в лечении не наблюдается или наблюдается, но незначительное.
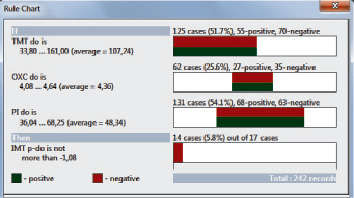
Рис. 6. Диаграмма правила
Таблица 1
Field Index (до лечения)
|
Field |
Rule |
|
DV.PR. do |
2, 10, 12, 15, 21 |
|
FNO (ne > 2,5 pg/ml) do |
13, 14 |
|
IA do |
1, 6, 17, 20 |
|
IgM do |
2, 5, 21 |
|
Kortizol do |
1, 12, 14, 18 |
|
LPNP do |
3 |
|
Lizocim do |
5, 9, 13, 15 |
|
OXC do |
3, 4, 11, 16, 19 |
|
PI do |
4, 6 |
|
TAG do |
7, 19, 20, 21 |
|
TMT do |
1, 4, 6 |
|
TTG(0,23-3,4) do |
2, 3, 7, 8, 10, 12 |
Таблица 2
Field Index (после лечения)
|
Field |
Rule |
|
APF p-do |
2, 5, 28, 29, 33, 50, 65, 69, 70 |
|
CIK p-do |
15, 20, 21, 31, 32, 34, 37, 41, 42, 47, 54, 57, 63, 64, 68, 69, 73 |
|
DAD p-do |
1, 2, 6, 8, 13, 17, 19, 23, 26, 46,53, 59 |
|
DV.PR.р-do |
9, 10, 12, 17, 22, 23, 24, 30, 31, 36, 39, 40, 48, 49, 54, 61, 62, 63, 69, 71, 72, |
|
FNO p-do |
43, 61, 62 |
|
IgG p-do |
2, 5, 19, 20, 21, 30, 31, 32, 46, 52 |
|
IgM p-do |
27 |
|
Insylin p-do |
11, 13, 15, 16, 19, 28, 29, 33, 68 |
|
Kortizol p-do |
4, 7, 8, 9, 18, 28, 29, 33, 39, 40, 47, 48, 49, 52, 54, 57, 60, 73, 74 |
|
LPONP p-do |
21, 29, 40, 42, 45, 49, 56, 62, 67, 72 |
|
Lizocim p-do |
37, 41, 42, 54, 63, 64, 73, 74 |
|
MG p-do |
3, 10, 17, 24 |
|
NOMA p-do |
14, 34, 37, 46, 53, 58, 59, 60, 70, 71, 72 |
|
OL p-do |
4, 14, 18, 20, 21, 27, 30, 32, 35, 38, 41, 42, 48, 49, 50, 51, 59, 61, 62, 63, 71, 72, 74 |
|
OXC p-do |
25, 26, 35 |
|
PI p-do |
16, 36, 39, 40, 53, 58, 60, 64, 66, 67 |
|
SAD p-do |
1, 10, 12, 25, 44, 45, 58, 70 |
|
T syp p-do |
18, 19, 46, 51, 57, 64 |
|
TAG p-do |
20, 28, 39, 41, 44, 48, 55, 61, 66, 71 |
|
TFN p-do |
34, 37, 47, 52, 53, 58, 59, 60, 68, 70,73 |
Правило № 2:

Из анализа правила № 2 следует, что снижение диастолического артериального давления, иммуноглобубина G и ангиотензинпревращающего фермента в сыворотке крови, способствует лучшему похудению пациентов, индекс массы тела уменьшается более чем на 1,08, достоверность 100 %.
Заключение
Результатом выявления скрытых закономерностей для данных поставленной задачи является в дальнейшем корректировка траектории лечения детей с различными степенями ожирения в НИИ курортологии г. Томска. В частности, полученные знания о результатах лечения в каждой такой группе дадут возможность правильно выбрать процедуру лечения для поступивших пациентов. Разработанный авторами алгоритм выявления скрытых закономерностей будет входить в состав информационной системы, разрабатываемой в рамках выполнения проекта РФФИ № 14-07-00675.
Работа выполнена при поддержке гранта РФФИ, проект № 14-07-00675.
Рецензенты:
Уразаев А.М., д.б.н., профессор, Институт теории образования, ФГБОУ ВПО «Томский государственный педагогический университет», г. Томск;
Мещеряков Р.В., д.т.н., профессор, заведующий кафедрой безопасности информационных систем, Томский государственный университет систем управления и радиоэлектроники, г. Томск.
Работа поступила в редакцию 12.02.2015.
Библиографическая ссылка
Марухина О.В., Мокина Е.Е., Берестнева Е.В. ПРИМЕНЕНИЕ МЕТОДОВ Data Mining ДЛЯ ВЫЯВЛЕНИЯ СКРЫТЫХ ЗАКОНОМЕРНОСТЕЙ В ЗАДАЧАХ АНАЛИЗА МЕДИЦИНСКИХ ДАННЫХ // Фундаментальные исследования. 2015. № 4. С. 107-113;URL: https://fundamental-research.ru/ru/article/view?id=37131 (дата обращения: 11.07.2026).