



Кластерный анализ обеспечивает необходимость классификации существующих факторов с определением степени их влияния на оценку эффективности функционирования воспроизводственного механизма технического потенциала зернового подкомплекса. При этом были установлены задачи принятия набора стратегических действий для достижения целевой позиции. Также были учтены факторы внутренней и внешней среды сельскохозяйственных организаций зерновой специализации, для анализа определены признаки, способные принимать любые значения в алгоритме.
На первом этапе алгоритма производится анализ значений факторов, воздействующих на стратегические позиции сельскохозяйственной организации зернового направления, характеризующих эффективность.
На втором этапе алгоритма осуществляется количественная оценка кластеров на основе построения матрицы с помощью статистической программы [1]. Зависимость объекта от значения признака в матричной форме будет выглядеть следующим образом:
На третьем этапе алгоритма осуществляется кластеризация факторов с учетом внутренней среды технического обеспечения зернового подкомплекса по их значениям [2]. С целью достижения объективности анализа данные матрицы стандартизируются, то есть приводятся в единую метрику [6]. Затем рассчитываются расстояния между факторами. С помощью различных методов данные матрицы кластеризуются по ряду признаков.
На четвертом этапе алгоритма получают кластеры, включающие в себя факторы [3], имеющие наибольшее сходство, или наименьшие евклидовые расстояния. Построение древовидной диаграммы, позволяет отследить, как связывается вместе все большее и большее число факторов и агрегируется все больше и больше кластеров, состоящих из все больше различающих факторов. В результате успешного анализа методом объединения определяется количество и содержание кластеров, состоящих из наиболее схожих по значениям факторов.
На пятом этапе алгоритма на основе существующей гипотезы о количестве кластеров производится кластеризация факторов технического обеспечения зернового подкомплекса с учетом внешней среды метриками расстояний. Этап позволяет осуществить проверку гипотезы о сосуществовании кластеров и их составе.
На шестом этапе алгоритма полученные результаты кластеризации метриками расстояний позволяют рассчитать средние значения для каждого кластера по каждому фактору [5].
На седьмом этапе алгоритма осуществляется произведение показателей влияния факторов на их значение. Полученные коэффициенты позволяют сопоставлять и сравнивать между собой разные по характеру действия и формы проявления факторов: конкурентоспособность отечественной с.-х. техники и т.д. Полученная сопоставимость оценок условий бизнеса позволяет определить стратегические позиции воспроизводства технического потенциала зернового подкомплекса.
При этом факторы характеризуют развитие среды по отношению к выбранной стратегии. Следовательно, в зависимости от целей зерновой отрасли в стратегической перспективе выбирается та или иная альтернатива, реализация которой будет задавать воспроизводство технического потенциала зернового подкомплекса.
С помощью кластерного анализа проводится кластеризация постоянно действующих представителей зерновой отрасли с целью построения научно обоснованной классификации, выявления внутренних связей между единицами наблюдаемой совокупности.
Для проведения классификаций было введено понятие сходства объектов по наблюдаемым признакам. В каждый кластер должны попасть объекты, имеющие сходные характеристики или, другими словами, в некотором смысле однородные объекты.
В качестве показателей, используемых для классификации, предложены следующие:
Х1 - фактически посеянная площадь, га;
Х2 - валовой сбор зерна в первоначально оприходованной массе, ц;
Х3 - затраты на 1 га посевов зерновых, руб.;
Х4 - произведено в физической массе после доработки на 1 тракториста, ц/чел.;
Х5 - трудоемкость, ц/чел.;
Х6 - объем реализованных зерновых культур, ц;
Х7 - средняя цена реализации зерна за 1 ц, руб.;
Х8 - себестоимость зерна за 1 ц, руб.;
Х9 - среднегодовое количество тракторов всех марок, ед.;
Х10 -нагрузка на 1 трактор с.-х. угодий, га;
Х11 - среднегодовое количество зерноуборочных комбайнов, ед.;
Х12 - нагрузка на зерноуборочный комбайн, га;
Х13 - нагрузка на сеялку, га;
Х14 - энерговооруженность, ед. изм.;
Х15 - численность работников, чел.;
Х16 - прибыль (убыток) от реализации зерновых культур, тыс. руб.
В методах кластерного анализа на результаты классификации оказывают влияние единицы измерения исходных показателей. Если проводить классификацию по показателям, измеряемым в различных несопоставимых единицах, то конечные результаты будут искажены из-за различных абсолютных значений. Для исключения этого исходные данные были пронормированы на максимальное значение i-го показателя.
Расстояния между единицами общностей исследовались различными способами [8]. В сущности, кластерный анализ представлен набором алгоритмов, вычисляющих расстояние либо близость между объектами в различных метриках.
В результате проведения кластерного анализа была получена классификация сельскохозяйственных организаций Челябинской и Свердловской областей по ряду отобранных показателей эффективности деятельности сельскохозяйственных организаций. Дендрограмма проведенной многомерной классификации представлена, на рис. 1, 2, где отчетливо выделяются три типологические группы сельскохозяйственных организаций Челябинской области (рис. 1, 2).
Установлено, что сельскохозяйственные организации распределены по кластерам и зонам неравномерно. Выявлена четкая зависимость между составом кластеров и зональностью ведения сельскохозяйственного производства. Во второй и первый кластеры вошли с.-х. организации степной и лесостепной зон. Большая часть сельскохозяйственных организаций всех районов степной зоны вошла в первый кластер. Соответственно, выявлены существенные отличия кластеров не только по зональному расположению, но и по специализации.
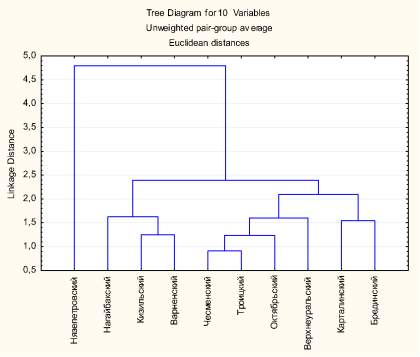
Рис. 1. Дендрограмма многомерной классификации районов зернового подкомплекса Челябинской области: 1 – Linkage Distance – Связь – расстояние; 2 – Tree Diagrom for 10 Variables – Дерево диаграмм для 10 переменных; 3 – Unweighted pair-group av erage – Средневзвешенные пара-групп; 4 – Euclidean distances – Евклидово расстояние
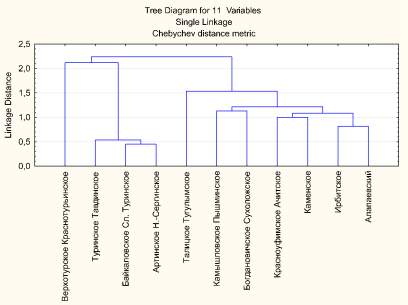
Рис. 2. Дендрограмма многомерной классификации районов зернового подкомплекса Свердловской области: 1 – Linkage Distance – Связь – расстояние; 2 – Tree Diagrom for 10 Variables – Дерево диаграмм для 10 переменных; 3 – Unweighted pair-group av erage – Средневзвешенные пара-групп; 4 –Euclidean distances – Евклидово расстояние
Таким образом, в ходе проведенного кластерного анализа были получены типические группы сельскохозяйственных организаций по эффективности производства и реализации, выявлены свойственные им качественные особенности.
Учет территориальных различий эффективности деятельности необходим не только с целью сравнения отдельных сельскохозяйственных организаций по показателям производства и реализации зерновой продукции, но и для выработки управленческих решений на уровне сельскохозяйственных организаций с целью сглаживания экономических различий, для выявления отдельных факторов в формировании оценки технического потенциала с возможностью влияния на них.
Большое достоинство кластерного анализа в том, что он позволяет разбивать объекты не по одному параметру, а по целому набору признаков. Кроме того, кластерный анализ, в отличие от большинства математико-статистических методов, не накладывает никаких ограничений на вид рассматриваемых объектов и позволяет рассматривать множество исходных данных. Это имеет большое значение, например, для прогнозирования конъюнктуры, когда показатели имеют разнообразный вид, затрудняющий применение традиционных эконометрических подходов.
Для более точной оценки технического потенциала с.-х. организаций зернового направления следуют определенные комбинации относительных показателей. Такая возможность появляется при использовании статистического метода, который называют «анализом множества дискриминант» [9]. Сущность его заключается в том, что с помощью математико-статистических методов рассчитываются параметры корреляционной функции, а затем устанавливается показатель, на основании которого можно делать определенные прогнозы.
Дискриминантный анализ является статистическим методом, который позволяет ранжировать различия между двумя и более группами [10]. Дискриминантный метод обеспечивает получение необходимых результатов, если объекты принадлежат одному или нескольким классам. Экономические объекты (характеризующие показатели) являются единицами анализа. Они классифицируются по принципу максимального сходства и могут быть представлены набором первичных признаков. На практике возникают ситуации, когда объект нельзя отнести ни к одному из имеющихся классов.
Дискриминантный анализ объединяет тесно связанные статистические процедуры, которые можно разделить на методы интерпретации межгрупповых различий и методы классификации наблюдений по группам. При проведении процедуры интерпретации требуется ответить на вопрос может ли данный набор признаков отличать один класс от другого, насколько правильно эти характеристики позволяют произвести разграничение на группы и какие из признаков наиболее информативны. Методы классификации направлены на получение функций, обеспечивающих разделение регионов по группам. Дискриминантный анализ проводится как для интерпретации, так и для классификации.
Учитывая данные ограничения, необходимо провести анализ параметров обучающих выборок с тем, чтобы они соответствовали требованиям использования дискриминантного анализа. Для проверки наличия тесной связи между полученными переменными произведен расчет мультиколлинеарности на основе исходных данных по полученным данным дискриминантного анализа для каждого кластера.
Сложность и взаимное переплетение отдельных факторов, обусловливающих исследуемое экономическое явление (процесс), могут проявляться в так называемой мультиколлинеарности [6]. Одним из индикаторов определения наличия мультиколлинеарности между признаками является превышение парным коэффициентом корреляции величины 0,8 (rxixj) и др.
Для построения многофакторных корреляционных моделей одной из предпосылок обоснованности конечных результатов является требование возможно меньшей коррелированности включенных в модель признаков-факторов. В случае линейной зависимости между факторами система уравнений не имеет однозначного решения, в результате чего коэффициент регрессии и другие оценки являются неустойчивыми, взаимосвязь факторов затрудняет экономическую интерпретацию уравнения связи.
Устранение мультиколлинеарности может реализовываться через исключение из корреляционной модели одного или нескольких линейно-связанных факторных признаков или преобразование исходных факторных признаков в новые, укрупненные факторы. Вопрос о том, какой из факторов следует отбросить, решается на основании качественного и логического анализов изучаемого явления.
Для количественной оценки технического потенциала с.-х. организаций зернового направления на результаты финансово-хозяйственной деятельности каждого кластера была построена многофакторная корреляционно-регрессионная модель результативного показателя продукции зерна.
В уравнение множественной регрессии были включены следующие существенные факторы, выявленные в ходе дискриминантного анализа и расчета мультиколлинеарности:
Х1 – произведено в физической массе после доработки на 1 тракториста, ц/чел.;
Х2 – среднегодовое количество тракторов всех марок, ед.;
Х3 – среднегодовое количество зерноуборочных комбайнов, ед.;
Х4 – численность работников, чел.
Результативный признак Y – прибыль (убыток) от реализации зерновых культур, тыс. руб.
Расчет параметров многофакторной корреляционно-регрессионной модели результативного показателя был проведен с использованием прикладных статистических программ [1, 6].
В результате обработки данных получены следующие уравнения регрессии для каждого кластера (таблица).
Критериальная оптимизация по максимальному увеличению валового сбора зерна
|
Номер кластера |
Уравнение регрессии |
Коэффициент детерминации (R2) |
|
Челябинская область |
||
|
I |
Y = –0,869Х1 + 1,872Х2 – 0,317Х3 – 1,174X4; 1814 ≤ Х1 ≤ 2259; 154 ≤ Х2 ≤ 537; 80 ≤ Х3 ≤ 245; 578 ≤ Х4 ≤ 2243 |
0,8666 |
|
II |
Y = 0,149Х1 + 1,895Х2 – 1,777Х4; 295 ≤ Х1 ≤ 1679; 87 ≤ Х2 ≤ 374; 367 ≤ Х4 ≤ 1985 |
1,0 |
|
Свердловская область |
||
|
I |
Y = –1,754Х1 – 1,904Х2 + 3,242Х3 – 0,147Х4; 910 ≤ Х1 ≤ 1974; 268 ≤ Х2 ≤ 550; 281 ≤ Х3 ≤ 706; 1122 ≤ Х4 ≤ 4037 |
0,996 |
|
II |
Y = 1,064Х1 – 0,034Х2 + 0,51Х4; 862 ≤ Х1 ≤ 1462; 173 ≤ Х2 ≤ 425; 757 ≤ Х4 ≤ 1452 |
0,850 |
Значения коэффициентов множественной детерминации позволяют сделать вывод о том, что изменение уровня прибыли (убытка) от реализации зерновых культур для Челябинской области на 86,7 % для первого кластера и на 100 % для второго кластера обусловлено влиянием факторов, входящих в модель, для Свердловской области на 99,6 % для первого кластера и на 85,0 % для второго кластера обусловлено влиянием факторов, входящих в модель.
Из вышеизложенного следует отметить, что только инновационность производства способствует достижению успехов в усилении конкурентоспособности сельскохозяйственных организаций зернового направления и становится передовыми в зерновой отрасли. В Челябинской и Свердловской областях развитие кластеров является одним из эффективных инструментов повышения конкурентоспособности сельскохозяйственных организаций, а также ускоряет развитие экономики агропромышленного комплекса.
Предложенная методика эффективности функционирования механизма воспроизводства технического потенциала зернового подкомплекса может быть использована:
а) руководством сельскохозяйственных организаций в целях повышения технической обеспеченности и результативности производства зерна;
б) административными органами управления на районном и областном уровнях в целях доведения до установленных размеров индикативных показателей реализации государственных программ, например, развития сельского хозяйства и регулирования рынков сельскохозяйственной техники.
Таким образом, разработанная методика позволяет провести оценку эффективности функционирования механизма воспроизводства технического потенциала зернового подкомплекса.
Рецензенты:
Коледин С.В., д.э.н., профессор, заведующий кафедрой «Экономика АПК», Челябинский институт (филиал), ФГБОУ ВПО «Уральский государственный экономический университет», г. Челябинск;
Пряхин Г.Б., д.э.н., профессор кафедры «Экономика и управление», ФГБОУ ВПО Уральский государственный университет физической культуры, г. Челябинск.
Работа поступила в редакцию 07.04.2014.
Библиографическая ссылка
Сёмин А.Н., Лысенко М.В. ДИАГНОСТИКА ЭФФЕКТИВНОСТИ ФУНКЦИОНИРОВАНИЯ ВОСПРОИЗВОДСТВЕННОГО МЕХАНИЗМА ТЕХНИЧЕСКОГО ПОТЕНЦИАЛА ЗЕРНОВОГО ПОДКОМПЛЕКСА // Фундаментальные исследования. 2014. № 6-6. С. 1267-1272;URL: https://fundamental-research.ru/ru/article/view?id=34327 (дата обращения: 30.07.2026).