



Задачей морфологического анализатора (МА) чувашского языка является установление морфемного состава слов, а также морфологических признаков, используемых в задачах синтаксического и семантического анализаторов.
База знаний морфологического анализа чувашского языка состоит из списка перечислимых типов (описывающих морфологические признаки), словарей (описывающих значение морфем), справочников (описывающих взаимосвязь морфем и признаков), структуры рабочей модели данных (для хранения текстов, слов и вариантов разбора слов) и метаправил (описывающих последовательность разбора слов разных частей речи).
Распределение морфологических характеристик по частям речи приведено в таблице.
Цель работы: проектирование, разработка динамически подключаемой библиотеки (dll), предоставляющей набор методов и функций для морфологического анализа слов чувашского языка для внедрения в системы машинного перевода, лингвистических процессоров.
Проект библиотеки морфологического анализатора состоит из семи классов (рис. 1).
Распределение морфологических характеристик
|
Существительное |
Лицо, число, падеж, форма (1–17), одушевленность, время |
|
Прилагательное |
Лицо, число, падеж, форма (5, 12, 10, 3, 8, 17, 18), время |
|
Числительное |
Репрезентация, форма (4, 5, 10, 12, 10, 14, 2, 17), падеж |
|
Местоимение |
Репрезентация, форма (8, 14, 1, 2), падеж |
|
Глагол |
Репрезентация, вид, аспект, залог, время, падеж (В), форма (9) |
|
Причастие |
Вид, аспект, залог, время, форма (7, 1, 9, 11), падеж |
|
Деепричастие |
Вид, аспект, залог, время |
|
Союз |
Репрезентация, форма |
|
Частица |
Значение, форма |
|
Послелог |
Значение, форма |
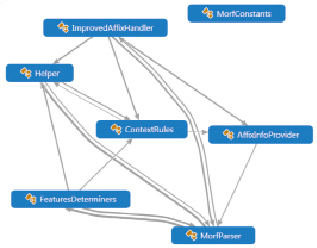
Рис. 1. Библиотеки морфологического анализатора чувашского языка
MorfParser.cs – Главный класс МА. Имеет два открытых метода для работы.
AffixInfoProvider.cs – Класс предоставляет набор полей и функций для работы с аффиксами.
ContextRules.cs – Класс отвечает за корректное определение правила восстановления согласно контексту.
FeaturesDeterminers.cs – Класс предоставляет набор функций для определения атрибутов (характеристик) слов.
Helper.cs – Класс содержит набор вспомогательных статических функций.
ImprovedAffixHandler – Класс принимает слово для разбиения его на составляющие и производит поиск в словаре.
MorfConstants – Класс представляет собой набор констант, введенных и использованных в проекте.
Требования к библиотеке [1]:
- Определение части речи слова и других морфологических характеристик
- Выделение корня и аффиксов.
- Распознавание контекстов.
- Анализ слов-исключений.
- Возможность вывода результатов в файл.
- Режим логгирования для удобной отладки.
Общий алгоритм:
Шаг 1. Начало.
Шаг 2. Разработка технического задания и составления критерия определения готовности работы.
Шаг 3. Выбор программы и языков создания библиотеки.
Шаг 4. Разработка алгоритмов решения задачи.
Шаг 5. Реализация функционала из технического задания.
Шаг 6. Тестирование всех функций библиотеки.
Шаг 7. Завершение работы.
Структура разработки представляет собой минимальный набор средств для работы приложения. Для использования библиотеки МА требуется платформа .NET Microsoft.
Структуру чувашских слов можно представить в виде суммы корней и аффиксов. Приставки и окончания, в отличие от русского языка, в чувашском языке отсутствуют, что упрощает разработку МА. Таким образом, для разработки требовался словарь основ (корней) и база аффиксов [2]. Исходный словарь представляет собой текстовый файл, в котором слова представлены следующим образом: слово, часть речи, информация об источнике. В нем собрано более тридцати одной тысячи слов чувашского языка.
В чувашском языке около ста семидесяти аффиксов. Исходная база аффиксов (БА) имела схожую структуру со словарем [3].
Рассмотрим пример. Слово «витресемпех», означающее «с ведрами же», раскладывается на следующие составляющие: «витре+сем+пе+х». Извлеченные аффиксы сохранят свой порядок и с другими словами («ачасемпех», «ecсемпех»). Из этого можно сделать вывод о возможности представления базы аффиксов в виде совокупности уровней. Где на каждом уровне будут храниться аффиксы, которые могут склеиваться с аффиксами, у которых уровни ниже. На основе ранее извлеченных аффиксов БА бы выглядела следующим образом: на первом уровне «сем», на втором «пе», на третьем «х». Вдобавок, каждый аффикс, помимо признака последовательности, хранит в себе характеристику типа. Согласно этому принципу, каждому аффиксу свойственна своя палитра частей речи, к которым он может присоединиться. Аффиксы из рассмотренного примера могут соединяться со следующими частями речи:
«Сем» – аффикс множественного числа. Существительные, прилагательные, числительные, местоимения.
«Пе» – аффикс дательного падежа. Существительные, прилагательные, числительные, местоимения.
«Х» – аффикс категории усиления. Существительные, прилагательные, числительные, местоимения, глаголы.
Список подходящих частей речи довольно обширный. Для компактности части речи разделены на условные группы. После анализа выявлены определены типы и которые применены в конечной версии базы аффиксов.
OnlyGlagol – тип, под которым объединены аффиксы глагольного типа, т.е. склеивающиеся только с глаголами. К таким относятся: «ма, ме, маc, меc».
NotGlagol – тип, объединяющий неглагольный класс аффиксов. По большей части это падежные аффиксы: «па, пе, ра, ре, та, те».
Any – общий тип аффиксов, способные соединяться и с глагольными и именными частями речи. Например, аффикс «а» относится и к дательному падежу (cурт -> cурта), так и к деепричастиям (чуп -> чупа).
Формирование базы аффиксов завершается определением одного из трех типов для каждого уровня аффиксов. Некоторые уровни, содержащие пересекающиеся типы, разбиваются до наличия лишь однородных аффиксов на один уровень. БА на данный момент разделен на тридцать семь (37) уровней.
В целях более удобного внесения изменений словарь и база аффиксов и другие вспомогательные документы хранятся в виде текстовых файлов. Для редактирования как специалисту, так и пользователю в качестве программного обеспечения достаточно стандартного блокнота. Тем не менее при необходимости БА легко может быть конвертирована в таблицы базы данных в силу своей структуры.
Разработку морфологического анализатора можно разделить на два этапа. Во-первых, слово в исходной форме ищется в словаре основ. Грамматические характеристики в данном случае определяются по умолчанию в зависимости от части речи. На втором этапе производится непосредственный анализ слова, разбиение его на пары «корень-аффиксы» и выявление характеристик. Оба этапа возвращают произвольное количество частей речи в зависимости от найденных совпадений. При отсутствии совпадений слово возвращается с «неопределенными» характеристиками. Рассмотрим поподробнее каждый из этих этапов.
Первая и наиболее простая часть – это прямой поиск входного слова в словаре основ. Эту задачу решает функция SearchInDictionaries. Алгоритм метода приводится ниже.
Алгоритм поиска совпадений в словаре.
Шаг 1. Отделить от входного слова аффиксы-частицы, такие как «-и», «-cке» и другие: «aшa-cке» (тепло же), «пысaк-и?» (большой ли). Записать аффиксы в строковой переменной. Если слово «двойное», образованное с помощью повторения (кил-кил), убрать повторяющуюся часть слова.
Шаг 2. По началу слова определить диапазон поиска. Так как словарь отсортированный, непосредственно проход по всему словарю не требуется.
Шаг 3. В выявленном диапазоне производить поиск слова. Вне зависимости от найденных совпадений продолжать поиск до конца.
Шаг 4. Извлечь часть речи найденного слова. На основе него определить остальные грамматические характеристики.
Определение границ поиска непосредственно основано на рассмотрении всех возможных вариаций пар символов, с которых может начинаться слово (рис. 2).

Рис. 2. Структура вариаций пар символов
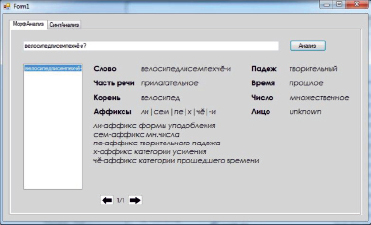
Рис. 3. Рабочее окно морфологического анализатора
Составив список пар, отсортировав их в алфавитном порядке и сопоставив их со словарем, получаем некую карту, где каждой паре слева справа соответствует номер строки, с которой начинаются подобные слова. Однако эти данные не определяются заранее. Так как в МА предусмотрена возможность динамического подключения разных словарей, выявление границ поиска определено в функцию. Таким образом, функция автоматически запускается при подключении нового словаря, обеспечивая анализатор актуальными данными [4, 5].
Как видно из рис. 3, программа корректно проводит анализ слов и правильно определяет корень и атрибуты. Как показали результаты тестирования, установление морфемного состава слов, а также морфологических признаков производится за 1–3 миллисекунды.
В предлагаемой работе разработана библиотека морфологического анализа чувашского языка. Библиотека создана на платформе NET.Framework в среде Visual Studio 2013 на языке C#. Приведен оригинальный алгоритм рекурсивного метода разбиения исходного слова на составляющие. Разработанная библиотека выполняет следующие задачи: определение части речи слова; извлечение корня и аффиксов; анализ контекстов, восстановление символов; определение морфологических характеристик; логгирование работы для удобной отладки.
Результаты работы библиотеки успешно могут быть применены на входе синтаксического анализатора и являются составной частью лингвистического процессора.
Исследование выполнено при финансовой поддержке РФФИ в рамках научного проекта № 15-04-00532.
Библиографическая ссылка
Желтов В.П., Сергеев Е.С., Пушкин А.С., Скворцов А.В. НЕКОТОРЫЕ ВОПРОСЫ ПРОЕКТИРОВАНИЯ МОРФОЛОГИЧЕСКОГО АНАЛИЗАТОРА ЧУВАШСКОГО ЯЗЫКА // Фундаментальные исследования. 2017. № 10-3. С. 438-442;URL: https://fundamental-research.ru/ru/article/view?id=41854 (дата обращения: 20.07.2026).