



При передаче вербальной информации имеют значение не только слова, но и их эмоциональная окраска. В этом главную роль играет интонация. Отсутствие интонации в речи делает ее монотонной. Слушая однообразную речь, приходится затрачивать гораздо больше усилий на ее осмысление, и результат не всегда бывает правильным. Например, если прочитать следующую фразу без пауз и логического ударения, то будет непонятно, что имел в виду автор:
Казнить нельзя помиловать.
Голос современных синтезаторов речи – систем, генерирующих устную речь по тексту, звучит понятно, но неестественно: в нем практически отсутствует интонация. Отсутствие полного набора средств интонации, выделяемых лингвистами, в искусственной речи объясняется сложностью автоматического выделения интонации в тексте, которое часто требует понимания его смысла. Автоматическое понимание смысла естественно-языковых текстов – это нерешенная на сегодняшний день задача. Поэтому для извлечения интонации используются методы, основанные на морфологической и синтаксической информации. Так, Б.М. Лобанов в работе [5] проводит синтагматический анализ предложения и маркировку интонационного типа синтагм, в работе [3] исследует возможности использования синтаксического анализа письменного текста на начальном этапе алгоритма синтеза речи по тексту. В работе [7] рассматриваются вопросы построения моделей разметки высказываний и синтеза просодических характеристик с учетом анатомических ограничений. В работе [9] рассматривается возможность использования контекста для выделения интонации при синтезе речи в пределах одного предложения для английского языка. В работе [8] рассматриваются вопросы паузирования (вставки пауз) при синтезе речи.
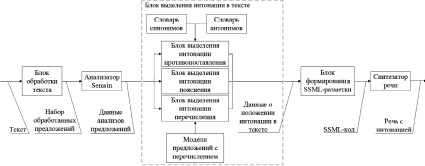
Рис. 1. Структурная схема системы выделения интонации при синтезе речи
В данной работе рассмотрен вопрос автоматического выделения интонации пояснения, перечисления и противопоставления на основе данных морфологического и синтаксического анализа предложения. В качестве анализатора текста используется семантико-синтаксический анализатор Semsin [4]. Рассматриваемые алгоритмы применялись для разметки исходного текста с помощью специальных маркеров – тэгов. Примеры приведены в международном формате языка SSML, позволяющего изменять тон, скорость и громкость произношения и ставить паузы.
Система автоматического выделения интонации при синтезе речи
На рис. 1 представлена структурная схема системы автоматического выделения интонации пояснения, противопоставления, перечисления при синтезе речи. На вход подается текст. Блок обработки текста исправляет орфографические и пунктуационные ошибки в тексте и разбивает его на предложения. Каждое предложение передается анализатору Semsin, который проводит семантический и морфологический анализы каждого слова в предложениях и строит синтаксическое дерево каждого предложения в тексте. Результаты работы анализатора передаются в блок выделения интонации в тексте, где на их основе выделяются места расстановки специальных маркеров смены голосовых характеристик. Блок формирования SSML-кода вставляет SSML-теги в места предложения, определенные в предыдущем блоке. В результате работы системы специальный SSML-код передается синтезатору, который, учитывая места смены тона, скорости, громкости и расстановки пауз, конвертирует его в речь с интонацией.
Интонация пояснения в причастных и деепричастных оборотах
Какая-либо часть предложения, имеющая значение добавочного сообщения или поясняющая основную мысль, произносится с интонацией пояснения. Она характеризуется увеличением скорости произношения и снижением тона [2]. Например, данной интонацией выделяется придаточная часть сложноподчиненного предложения, стоящая перед двоеточием (не перечисление) или начинающаяся со слова «который»:
Я не ошибся: старик не отказался от предлагаемого стакана. (Пушкин)
Интонацией пояснения выделяются деепричастные и обособляемые причастные обороты. Определив границы причастного или деепричастного оборота, можно определить границы интонации пояснения. Блок-схема алгоритма выделения границ обособляемого причастного оборота представлена на рис. 2.
На вход подается слово из исследуемого предложения. С помощью морфологического анализа Semsin определяется его часть речи.
Пример маркировки предложения для выделения интонации в обособляемом причастном обороте:
«Гелиотроп» напоминал начищенный кирпичом до яркого блеска бокастый дымящийся самовар, <prosody rate=»x1» pitch=»y1»> болтающийся на невысоких волнах мелкого моря </prosody>. (Паустовский)
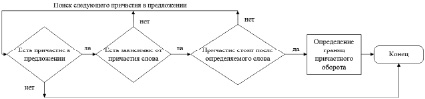
Рис. 2. Блок-схема алгоритма автоматического выделения интонации пояснения в причастных оборотах
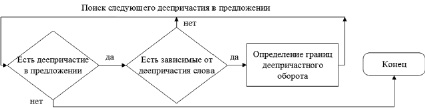
Рис. 3. Блок-схема алгоритма автоматического выделения интонации пояснения в деепричастных оборотах
Для выделения деепричастных оборотов используется аналогичный алгоритм, отличающийся нечувствительностью к местоположению деепричастия к определяемому слову. Блок-схема алгоритма выделения деепричастного оборота представлена на рис. 3.
Пример маркировки предложения c деепричастным оборотом:
Тут, около телег, стояли мокрые лошади, <prosody rate=»x1» pitch=»y1»> понурив головы </prosody>, и ходили люди, <prosody rate=»x2» pitch=»y2»> накрывшись мешками от дождя </prosody>. (Чехов).
Алгоритмы выделения интонации перечисления в причастных и деепричастных оборотах были реализованы в программном виде. Интонация перечисления выделилась практически во всех случаях (исключения составили случаи, когда анализатор Semsin неправильно провел синтаксический и/или морфологический анализы).
Интонация противопоставления
Предложения, в которых противопоставляются какие-либо действия, предметы, признаки предметов и т.д., характеризуются специфической интонацией, которую можно назвать интонацией противопоставления [2]. Данная интонация выражается отрицанием и в некоторых случаях противительными союзами, такими как а, но и др. [2]. Пример:
Это не картина, а фотография.
Частным случаем интонации противопоставления является антитеза – наличие в одном предложении пары антонимов, связанных между собой:
Бедный и в будни пирует, а богатый и в праздник горюет.
Для выделения пары антонимов в предложении с целью задания им интонации противопоставления целесообразно использовать два словаря – антонимов и синонимов. С помощью данных словарей был составлен алгоритм автоматического выделения интонации противопоставления, блок-схема которого представлена на рис. 4.
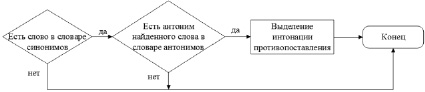
Рис. 4. Блок-схема алгоритма автоматического выделения интонации противопоставления в тексте
Пример разметки:
Он не <prosody pitch=»x1» volume=»y1»> враг </prosody>, а <prosody pitch=»x1» volume=»y1»> друг </prosody>.
В результате проведения вычислительного эксперимента интонация выделилась не во всех примерах, так как пара нужных антонимов отсутствовала в словаре (при разработке использовался словарь антонимов М.Р. Львова [6] и словарь синонимов Н. Абрамова [1]). На основе анализа работы предложенных алгоритмов можно сделать вывод, что точность правильного выделения маркеров интонации противопоставления зависит от размеров словарей антонимов и синонимов. Однако в некоторых случаях данный алгоритм не способен выделить противопоставления в тексте, например, когда в предложении присутствует пара контекстных антонимов:
Не мать купила яблоки, а дочь.
В данном предложении слова мать и дочь являются контекстными антонимами, то есть антонимами только в данном предложении. И в словаре антонимов эта пара отсутствует.
Интонация перечисления
Интонация повествовательного предложения может быть осложнена перечислением [2]. Членами перечисления могут быть как однородные члены предложения, состоящие из одного или нескольких слов, так и целые предложения. Члены перечисления выделяются специфической интонацией, характеризующейся паузой между ними и логическим ударением [2]. Длительность паузы зависит от длины члена перечисления. Пример:
Жидкое, газообразное, твердое – три состояния вещества.
Если длина членов перечисления составляет одно слово, то пауза между ними зависит от количества слогов в слове, если их 1–4, то она не ставится – они читаются непрерывно. Если слогов в слове больше или члены перечисления – словосочетания или целые предложения, то пауза между ними будет больше.
Современные синтезаторы речи не учитывают зависимость длительности паузы от длины члена перечисления. Они распознают запятые в тексте, но пауза, которую они ставят на месте запятой, имеет фиксированную длительность. Члены перечисления читаются быстро и прерывисто, что неестественно для человеческой речи.
Характерным признаком интонации перечисления является наличие в нем нескольких однородных членов, разделенных знаком запятой или сочинительным союзом и. В данной работе рассмотрен случай, когда интонация перечисления выделяется знаками препинания: двоеточие в начале и тире в конце (интонация тире и двоеточия [3]). Блок-схема алгоритма автоматического выделения интонации перечисления представлена на рис. 5.
После выделения границ интонации перечисления целесообразно заменить запятые в этой области на элемент разметки синтеза речи, позволяющий вставлять паузу в искусственную речь и задавать ее длительность, пример:
И жнивья <break time=»t1»/> и дорога <break time=»t2»/> и воздух – все вокруг сияло. (Бунин).
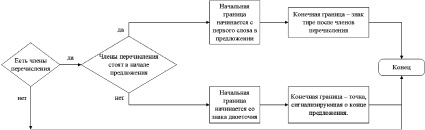
Рис. 5. Блок-схема алгоритма автоматического выделения интонации перечисления в тексте
При программной реализации алгоритма интонация не выделилась в предложениях, содержащих два члена перечисления, и в предложениях, в которых отсутствуют знаки препинания, указывающие на границы перечисления (двоеточия и тире), пример:
Туристы побывали в Новгороде, в Пскове, в Санкт-Петербурге, в Барнауле.
Также работа алгоритмов допускала неправильное выделение интонации в случае омонимии знаков препинания:
Погода была ужасная: ветер выл, было очень холодно, мокрый снег падал хлопьями.
В данном примере после двоеточия следует пояснение, а не перечисление, несмотря на наличие нескольких запятых после двоеточия.
Выделение интонационной разметки на основе общего алгоритма
На основе критериев выделения интонации пояснения, противопоставления и перечисления был разработан и реализован алгоритм в программном виде на языке C#. Для проверки работоспособности программы на основе корпуса текстов по изучению русского языка как иностранного экспертом была сделана выборка из нескольких десятков предложений на каждый предложенный алгоритм.
На первом этапе работы выборка предложений была размечена экспертом. На втором этапе она была размечена программой. Проценты совпадения разметки, полученной в результате работы эксперта и разметки программы, представлены в таблице.
В 93 % случаях программная реализация алгоритмов верно маркирует деепричастные и причастные обороты. Правильно маркируются предложения, содержащие одиночные причастия или деепричастия, несколько причастий (деепричастий) или несколько причастных (деепричастных) оборотов. Интонации противопоставления и перечисления выделяются соответственно в 60 и 70 % случаях.
Заключение
В результате работы была рассмотрена автоматизация трех наиболее значимых видов интонации в повествовательном предложении [2]. Разработаны программные алгоритмы, позволяющие автоматически выделить разметку интонации пояснения, противопоставления и перечисления в тексте для последующего конвертирования данного предложения в речь. На основе корпуса текстов для изучения русского языка как иностранного экспертом была сделана выборка, с помощью которой было проведено тестирование системы. Опыт показывает, что количество исключений (в силу специфики русского языка) настолько велико, что применение алгоритмов в чистом виде не дает точности результатов выше 60–70 %. Для повышения точности необходимо использовать контекстную информацию, получаемую в процессе семантического анализа текста и передающую не только формальную структуру предложения, но и смысл.
Результаты совпадения разметки, полученной экспертным и расчетным методами
|
Название конструкции |
Вид интонации |
Количество предложений в выборке |
Количество правильно маркированных предложений |
Процент совпадения (%) |
|
Обособленный причастный оборот |
пояснения |
10 |
9 |
90 % |
|
Необособленный причастный оборот |
нет |
5 |
5 |
100 % |
|
Однородные деепричастные и причастные обороты |
пояснения |
10 |
9 |
90 % |
|
Одиночные причастия и деепричастия |
нет |
5 |
5 |
100 % |
|
Противопоставление с парой антонимов |
противопоставления |
10 |
6 |
60 % |
|
Однородные члены, стоящие в начале предложения. |
перечисления |
10 |
7 |
70 % |
|
Однородные члены, стоящие в середине/конце предложения. |
перечисления |
10 |
7 |
70 % |
Библиографическая ссылка
Чемерилов В.В., Фадеев А.С., Мишунин О.Б. АЛГОРИТМ ВЫДЕЛЕНИЯ ИНТОНАЦИИ ПОЯСНЕНИЯ, ПРОТИВОПОСТАВЛЕНИЯ И ПЕРЕЧИСЛЕНИЯ В ТЕКСТЕ ПРИ АВТОМАТИЧЕСКОМ СИНТЕЗЕ РЕЧИ // Фундаментальные исследования. 2016. № 10-2. С. 354-359;URL: https://fundamental-research.ru/ru/article/view?id=40859 (дата обращения: 30.06.2026).