



С ростом числа вычислительных компонентов, включаемых в состав современных высокопроизводительных вычислительных систем (ВВС), существующие подходы, методы и средства для организации системного ПО ВВС перестают удовлетворять требованиям. Анализ существующих технологий создания и применения высокопроизводительных ВВС петафлопного уровня (см., например, работы [1, 5]), а также современных тенденций к построению ВВС эксафлопного уровня (см., например, работы [3, 21, 32]) позволяет сделать вывод о том, что надежность таких систем в рамках используемых на сегодняшний день парадигм и технологий будет являться весьма низкой. В связи с этим актуальным и перспективным направлением исследований в области системного ПО ВВС является создание новых подходов, методов и средств управления и мониторинга ВВС, способных обеспечивать необходимый уровень отказоустойчивости и надежности для вычислительных сред такого масштаба.
В задачи средств управления ВВС входит распределение нагрузки на вычислительные узлы, выполнение непараллельных и параллельных команд с последующей передачей результата пользователю или оператору, выполнение загрузки и остановки работы вычислительных узлов и ряд других. В задачи средств мониторинга входит сбор данных о работе всех компонентов ВВС, многокритериальный анализ собираемых данных и в случае обнаружения каких-либо отклонений принятия необходимых воздействий на компоненты.
Мониторинг компонентов ВВС условно можно разделить на следующие категории:
1) мониторинг и анализ эффективности выполнения программ в ВВС (контроль текущего состояния вычислительных процессов и их отдельных экземпляров, оценка эффективности использования выделенных ресурсов);
2) мониторинг, тестирование и диагностика аппаратных компонентов вычислительных узлов (жесткие диски, процессоры, оперативная память, сетевые интерфейсы и др.);
3) мониторинг инженерной инфраструктуры ВВС (системы бесперебойного питания, климатическое оборудование, системы пожаротушения и др.);
4) мониторинг вычислительной инфраструктуры ВВС (мониторинг текущей загрузки вычислительных узлов, контроль коммуникационных, управляющих и сервисных сетей, систем хранения данных);
5) мониторинг промежуточного программного обеспечения ВВС (мониторинг функционирования системных служб, очередей задач, агентов, различных подсистем и др.).
Разработка комплексной системы мониторинга, которая обеспечивала бы сбор данных с огромного количества разнородных компонентов, входящих в состав современных ВВС, является труднореализуемой задачей ввиду отсутствия стандартизованных форматов и протоколов сбора данных со всего множества разнородных программно-аппаратных компонентов ВВС. С другой стороны, на сегодняшний день существует огромное количество программных решений, которые в отдельности позволяют обеспечивать мониторинг необходимых компонентов ВВС. Более того, многие компоненты ВВС уже снабжены системами локального мониторинга. В связи с чем наиболее целесообразным и перспективным направлением развития исследований по созданию комплексных систем мониторинга ВВС является агрегация существующих локальных систем мониторинга в рамках комплексной системы мета-мониторинга ВВС [9]. При этом локальная система мониторинга выступает лишь поставщиком данных, а их экспертный анализ и принятие на основе результатов анализа необходимых регулирующих воздействий отводится системе мета-мониторинга. В общем случае схема интеграции локальной системы мониторинга в состав разрабатываемой системы мета-мониторинга приведена на рисунке.
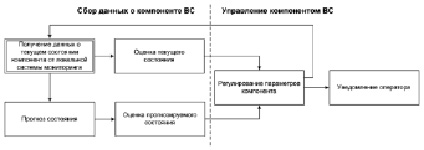
Общая схема интеграции локальной системы мониторинга в состав системы мета-мониторинга
В качестве локальных систем мониторинга могут быть использованы как небольшие утилиты для сбора данных об отдельном компоненте ВВС, так и комплексные системы мониторинга, агрегирующие информацию по набору компонентов и вычислительных узлов.
Далее в статье рассматриваются существующие средства мониторинга компонентов ВВС в рамках выделенных выше пяти категорий.
Средства мониторинга и анализа эффективности выполнения программ в ВВС
В данной категории накоплено несколько десятков профилировщиков программ, средств мониторинга загрузки вычислительных ресурсов экземплярами программ, выполняемых в узлах ВВС, средств мониторинга загрузки сетевых компонентов и т.д. Сравнительные обзоры таких средств приведены в работах [7, 24]. Среди наиболее популярных и широкоиспользуемых средств можно выделить следующие:
– NWPerf [26] – система анализа эффективности выполнения параллельных программ в крупномасштабных ВВС с возможностью предоставления данных как по всей параллельной программе в целом, так и по ее отдельным экземплярам.
– Allinea MAP [5] – профилировщик параллельных, многопоточных и последовательных программ, предоставляющий исчерпывающий анализ по множеству метрик.
– Lapta [4] – инструментарий для многоаспектного анализа динамических характеристик параллельных программ, выполняемых на суперкомпьютерах.
– mpiP [25] – легковесный профилировщик MPI-программ.
– IPM [19] – расширенный профилировщик параллельных программ с возможностью анализа MPI-пересылок, доступа к памяти, работе с сетевыми интерфейсами, диском.
– Intel VTune [18] – инструментарий для анализа производительности, масштабируемости, пропускной способности, кэширования при выполнении программ в ВС.
– TAU [33] – инструментарий для повышения производительности выполнения программ в ВС, анализа собираемых данных и визуализации выполнения параллельных программ в ВС.
– HPCToolkit [16] – инструментарий для мониторинга выполнения параллельных программ с возможностью анализа используемых ресурсов, автоматического выявления неэффективных блоков с привязкой к исходному тексту программы.
– Paraver [28] – анализатор производительности программ, основанный на трассировке событий и позволяющий производить детальный анализ изменения и распределения метрик с целью понимания поведения приложений.
– Scalasca [30] – инструментарий для выполнения оптимизации параллельных программ путем измерения и анализа их поведения во время выполнения.
Из представленного списка наиболее функциональными и перспективными решениями для анализа эффективности выполнения параллельных программ в ВВС, с точки зрения авторов, являются пакеты с открытым исходным кодом NWPerf и Paraver.
Мониторинг, тестирование и диагностика аппаратных компонентов вычислительных узлов
Для выявления неисправностей в аппаратных компонентах вычислительных узлов ВВС, к сожалению, авторам известно лишь небольшое число средств. Из них заслуживающими внимания являются:
– Disparity [11] – подход, основанный на запуске MPI-программы на анализируемых узлах с целью обнаружения возможных неисправностей.
– CIFTS [13] – использует механизмы обмена информацией о неисправностях с целью выработки целостной картины о состоянии узлов.
Наиболее интересным из них является программное средство Disparty, которое позволяет выявлять неисправности компонентов вычислительного узла во время простоя между запусками экземпляров вычислительных процессов. В данной категории авторами разрабатывается собственный подход [31] для многоступенчатой диагностики вычислительных узлов с использованием набора стандартных утилит (Sensors, SMART, IMPIutils и др.).
Мониторинг инженерной инфраструктуры ВВС
Для мониторинга инженерной инфраструктуры суперкомпьютерных центров и центров обработки данных наиболее распространенными средствами являются: ClustrX [10], EMC ViRP SRM [12], HP Cluster Management Utility [15], Bright Cluster Manager [8], Moab Adaptive HPC Suite [23], IBM cluster system management [17]. Однако все перечисленные средства являются проприетарными, зачастую жестко привязаны к оборудованию и не всегда обладают достаточной гибкостью для мониторинга инфраструктуры разнородных вычислительных сред.
Среди некоммерческих продуктов авторам не удалось найти приемлемых средств, которые позволяли бы универсально описывать состав разнородного инженерного оборудования суперкомпьютерного центра, создавать новые объекты и задавать правила их мониторинга. Системы мониторинга Nagios [20], Zabbix [35] предоставляют набор средств для мониторинга инфраструктуры ВВС, которые в каждом отдельном случае необходимо существенно дорабатывать. В данной категории авторами также осуществляется разработка собственных универсальных средств, базирующихся на агрегации локальных систем мониторинга инженерного оборудования. Некоторые аспекты реализации разрабатываемого авторами средств мониторинга инженерной инфраструктуры приведены в работе [2].
Мониторинг вычислительной инфраструктуры ВВС
В данной категории на сегодняшний день существует значительное число комплексных решений. Наиболее популярными из них являются:
– Ganglia [22] – масштабируемая распределенная система мониторинга кластеров параллельных и распределенных вычислений и облачных систем с иерархической структурой;
– Nagios – система мониторинга вычислительных систем и сетей с широкими возможностями уведомления оператора о возможных неисправностях;
– Zabbix – система мониторинга и отслеживания состояния разнообразных сервисов компьютерной сети, серверов и сетевого оборудования;
– ZenOSS [36] – система мониторинга с возможностями автоматического обнаружения и конфигурирования параметров контроля различных систем;
– Ovis2 [27] – комплексная система мониторинга, обеспечивающая высокую масштабируемость и интеграцию с другими системами мониторинга.
Наиболее популярной системой в данной категории по-прежнему является система мониторинга Ganglia. Однако стандартный набор функций данной системы не обеспечивает возрастающих потребностей по мониторингу вычислительного оборудования ВВС, что зачастую приводит к необходимости использования дополнительных систем мониторинга, таких как Zabbix или Nagios. Наиболее перспективной системой в данной категории, с точки зрения авторов, является система Ovis2, обеспечивающая высокую масштабируемость и широкие возможности по подключению различных источников данных.
Мониторинг промежуточного программного обеспечения ВВС
В данной категории могут использоваться как описанные выше системы мониторинга Nagios и Zabbix, так и более специализированные средства, такие как:
– Xymon [34] – мониторинг работы системных сервисов;
– FATE [14] – инструментарий тестирования облачных приложений;
– CloudRift [29] – среда тестирования микросервисных приложений.
Кроме перечисленных средств, администраторами ВВС зачастую разрабатываются специализированные утилиты для отслеживания корректного функционирования отдельных подсистем, входящих в состав промежуточного ПО ВВС, зачастую реализуемые в виде скриптов, запускаемых по расписанию с использованием сервиса CRON.
Заключение
В данной статье представлен подход к комплексному мониторингу ВВС на основе сбора и анализа данных, получаемых от набора локальных систем мониторинга, осуществляющих контроль отдельных подсистем. Для выбора локальных систем мониторинга, которые могут быть использованы в составе разрабатываемой авторами системы мета-мониторинга, в данной статье приведен обзор наиболее популярных и широкоиспользуемых средств в пяти выбранных категориях. Интеграция средств, представленных в каждой категории, в состав разрабатываемой авторами системы мета-мониторинга, будет проводиться в рамках дальнейших исследований.
Исследование выполнено при частичной финансовой поддержке РФФИ, проекты № 15-29-07955-офи_м и № 16-07-00931, а также при частичной финансовой поддержке Совета по грантам Президента Российской Федерации для государственной поддержки ведущих научных школ Российской Федерации (НШ-8081.2016.9).
Библиографическая ссылка
Сидоров И.А., Кузьмин В.Р. ОБЗОР СОВРЕМЕННЫХ СРЕДСТВ ДЛЯ КОМПЛЕКСНОГО МОНИТОРИНГА ВЫСОКОПРОИЗВОДИТЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ // Фундаментальные исследования. 2016. № 9-1. С. 62-67;URL: https://fundamental-research.ru/ru/article/view?id=40696 (дата обращения: 14.05.2026).