



Введение
Финансовые рынки – это сложная система торговли финансовыми активами и финансовыми услугами, позволяющая эффективно перераспределять активы между участниками рынка с целью их аккумуляции, инвестирования и обмена. Под финансовыми активами понимаются не только имущественные ценности, но и традиционные договоры и ценные бумаги (например, договор займа или уступки, облигации, акции, фьючерсы и др.) [1] – «цифровые финансовые активы». Отметим в этой связи, что технология блокчейн позволяет быстро создавать такие «цифровые финансовые активы», причем по более низкой цене и с гораздо большими возможностями персонализации актива [2]. Анализ реальных стоимостей финансовых активов позволяет выявить их основные паттерны, которые затем используют для предсказания будущих значений стоимостей активов. Фондовый рынок является своего рода площадкой для обмена финансовыми активами: акциями, облигациями, векселями, сертификатами и т. п. [3, c. 8–9]. Колебания цен финансовых активов на фондовом рынке создают возможности для увеличения прибыли или сокращения убытков при неблагоприятных условиях. Прогнозирование трендов помогает компаниям корректировать стратегии, запускать новые продукты и сохранять конкурентоспособность.
Московская биржа является крупнейшим в России организатором торгов ценными бумагами и производными финансовыми инструментами. Участникам фондового рынка (инвесторам, трейдерам, брокерам, дилерам, эмитентам и регуляторам) [4] требуется понимание основных аспектов функционирования Московской биржи и своевременный выбор стратегии для успешного ведения дел. Биржа способствует привлечению финансирования для организаций и обеспечивает инвесторам возможность получения дохода.
Обладание знаниями о будущих стоимостях акций существенно влияет на финансовую устойчивость российской экономики в целом [5; 6]. Правильный прогноз тренда изменения стоимостей акций на бирже способствует предотвращению финансовых кризисов и развитию экономики. Зарубежные исследователи внесли огромный вклад в построение теории, посвященной прогнозированию стоимостей финансовых активов [6–8]. Наряду с зарубежными работами по прогнозированию финансовых активов можно выделить и работы отечественных исследователей [5; 9]. Обзор научных и статистических источников показал, что на стоимость финансовых активов влияют следующие ключевые факторы [4]: финансовые и экономические показатели компании, геополитические и политические события, отраслевые факторы и др. Все перечисленные факторы взаимосвязаны между собой, и то, какие из них надо более, а какие менее учитывать, зависит от целей инвесторов. Объектом настоящего исследования являются исторические данные Московской биржи о стоимостях финансовых активов крупных компаний Российской Федерации.
Цель исследования – сравнить методы классификации, применяемые в машинном обучении, для предсказания тренда стоимостей акций российских компаний на Московской бирже в предстоящем временном интервале, применить полученные результаты для выбора стратегии поведения участников финансового рынка и использовать их для создания в последующем «торгового помощника» методами машинного обучения, реализованными на языке программирования Python в интегрированной среде разработки Google Colaboratory в режиме Jupyter Notebook.
Материалы и методы исследования
В качестве тестовых данных для исследования прогнозных стоимостей акций рассмотрены компании «Сбербанк» и «Газпром» в период с 2013 по 2025 г. Каждая из выбранных компаний является крупнейшим представителем в своей сфере деятельности. Финансовый портфель участников финансового рынка, как правило, состоит из 80 % акций «Сбера» и «Газпрома». В связи с тем, что многие интернет-платформы, продвигающие услуги банков, перестали функционировать на территории Российской Федерации, а внимание к российским акциям осталось высоким, данное исследование является достаточно актуальным.
Прогнозирование трендов рынка – это сложный процесс, требующий использования различных методов и подходов [7]. Методы предсказания будущих цен финансовых активов разрабатываются участниками рынка постоянно. Для этого применяются специальные алгоритмы, программные решения, а также методы машинного обучения или внешние сервисы, такие как Google Trends. Однако эффективной техники прогнозирования, гарантирующей 100 % точность предсказания, пока не существует. Когда речь идет о применении методов машинного обучения [10; 11] для обработки данных работы Московской биржи, то чаще всего используется метод технического анализа [3, с. 807–813]. Метод технического анализа позволяет выявить возможности алгоритмов методов машинного обучения и определить закономерности поведения стоимостей финансовых активов во времени. Однако наиболее эффективным методом автоматического предсказания цен на акции и другие финансовые активы является гибридный подход, сочетающий в себе подходы фундаментального и технического анализа [11].
Для автоматической классификации данных существуют различные алгоритмы машинного обучения, включающие в себя современные методы классификации, к примеру [10; 12, с. 125–138]: логистическая регрессия, метод опорных векторов (SVM); алгоритм случайного леса (Random Forest); деревья решений (Decision Trees); метод k-ближайших соседей (KNN); байесовские сети (Bayesian Networks). В [4] показано, что не каждая из моделей классификации подходит для классификации тренда цены акций. Наиболее подходящими моделями для прогнозирования тренда цены акций являются методы опорных векторов и нейронные сети (Neural Networks). Также необходимо отметить, что использование глубокого обучения [12, c. 355–370] значительно улучшает показатели качества и точность прогнозирования трендов стоимости акций. Это возможно за счет широкого использования графических процессоров – Graphics Processing Units (GPU), которые используются в большинстве современных алгоритмов машинного обучения и способствуют сокращению времени, необходимого для обучения нейронных сетей [12, c. 373–380]. Современные методы классификации, такие как ансамблевое моделирование [13] и гибридные методы, все чаще используются для достижения наилучшего результата. Такие методы позволяют учитывать все факторы, включая неструктурированные данные, и способны адаптироваться к изменениям на рынке. Однако они требуют большего количества данных и вычислительных ресурсов, а также опыта и знаний в области машинного обучения и искусственного интеллекта. В целом эти методы являются более точными и универсальными, чем классические методы классификации.
Исходные материалы получены посредством библиотеки apimoex с информационно-статистического сайта Московской Биржи (https://www.moex.com/). Обработка и визуализация исторических данных о стоимостях финансовых активов осуществлены и визуализированы посредством библиотеки pandas_datareader языка программирования Python в средах разработки Google Colaboratory в режиме Jupyter Notebook.
Результаты исследования и их обсуждение
Этапы обработки данных включают в себя разработку модулей загрузки данных, их предобработки, реализацию индикаторов, нормализацию данных, модулей модели машинного обучения и аналитического сравнения (рис. 1).
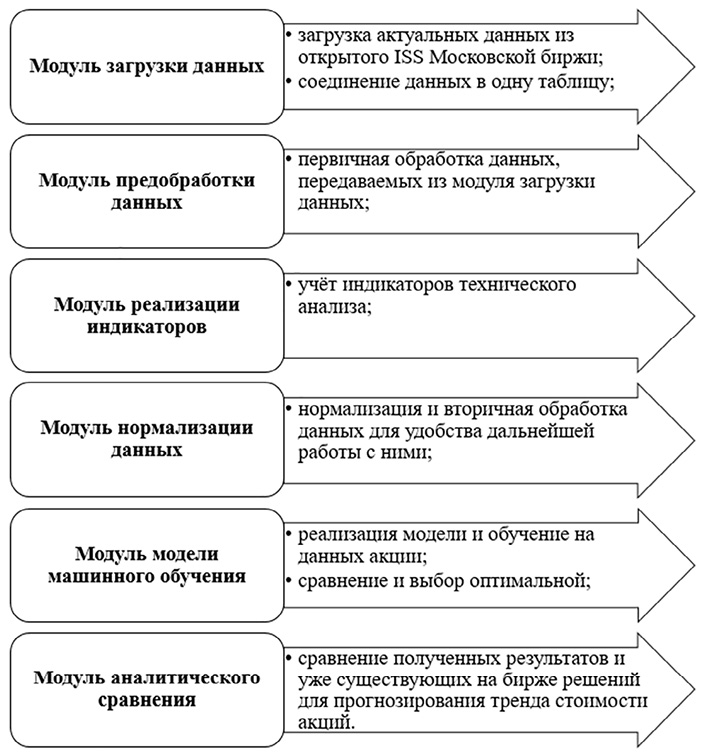
Рис. 1. Этапы обработки данных Примечание: составлена автором по результатам данного исследования
Основными проблемами, с которыми обычно сталкиваются при получении данных, являются:
1) качество данных (финансовые данные могут содержать ошибки, пропущенные значения или несоответствия поставленной задаче, поэтому перед использованием данных в модели прогнозирования произведена их очистка и предварительная обработка);
2) нестационарность финансовых временных рядов (затрудняет построение точных моделей прогнозирования) [14; 15];
3) структурные сдвиги (сложная совокупность различных факторов, что является внутренним источником развития экономической структуры).
Загрузка исторических данных стоимостей акций выполнена при помощи библиотеки pandas_datareader в период с 2013 по 2025 г. Использован дневной режим торгов (остальные типы режимов достаточно «шумные» и понижают качество моделей). В исследовании предсказания движения стоимостей акций сделаны на день вперед (во всех рассмотренных моделях ширина окна анализируемой информации равна 10 торговым дням). Дальнейшая обработка данных и прогнозирование стоимостей акций сделаны по данным столбца «CLOSE» (табл. 1). Кроме того, в исследовании введен синтетический показатель
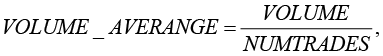 (1)
(1)
где VOLUME и NUMTRADES – объем торгов в единицах финансового инструмента и количество сделок соответственно (табл. 1). Расчет этого показателя для ежедневных продаж акций «Сбера» (2013–2025) приведен на рис. 2.
Формула (1) для вычисления показателя VOLUME_AVERANGE показывает ликвидность акций относительно других ценных бумаг на финансовом рынке и позволяет инвесторам оперативно реагировать на текущую ситуацию на Бирже (продавать или покупать акции).
Отдельно опишем процесс разметки данных.
Рис. 2. Данные среднего объема ежедневных продаж акций «Сбера» (2013–2025) Примечание: составлен автором по результатам данного исследования
Таблица 1
Описание основных данных из выгруженного датасета
|
Наименование |
Расшифровка |
Наименование |
Расшифровка |
|
SHORTNAME |
Короткое название акции |
NUMTRADES |
Количество сделок |
|
OPEN |
Цена открытия |
CLOSE |
Цена закрытия |
|
ADMITTEDQUOTE |
Признаваемая котировка |
ADMITTEDVALUE |
Объем сделок для расчета признаваемой котировки |
|
TRADEDATE |
Дата сделок |
TRENDCLSPR |
Изменение цены последней сделки по сравнению с соответствующей ценой предыдущего торгового дня (в %) |
|
VALUE |
Совокупный объем, выраженный в валюте расчетов |
VOLUME |
Объем торгов в единицах финансового инструмента |
Примечание: составлена автором на основе источника: URL: https://www.moex.com/

Рис. 3. Код для подбора гиперпараметров Примечание: составлен автором по результатам данного исследования
После всех преобразований с данными на основе столбца «CLOSE» создается переменная predicted (рис. 3). Поясним коротко работу этого фрагмента кода: задается интервал, на который будет проводиться прогнозирование движения тренда. В третьей строке выбираются две ближайшие строки данных, и если прошедшая строка меньше, чем последующая, то будет выводиться 1 (1 – цена акции вырастет), если последующая строка меньше, то будет выводиться 0 (0 – цена акции упадет).
Для оценки качества моделей регрессии существуют различные метрики, такие как accuracy (ACC), Precision (PPV), F1_score, AUC-ROC и др. [4]:
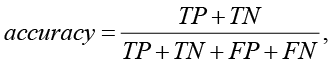
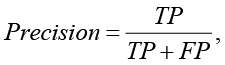 (2)
(2)
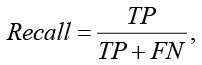
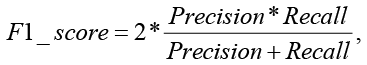
где TP (TruePositive) – верно предсказанные положительные случаи;
FP (FalsePositive) – отрицательные случаи, ошибочно предсказанные как положительные;
TN (TrueNegative) – верно предсказанные отрицательные случаи;
FN (FalseNegative) – положительные случаи, ошибочно предсказанные как отрицательные.
Рассмотрим каждую модель по отдельности, чтобы оценить точность и метрики для задач классификации. В качестве тестового набора данных возьмем сначала акции «Газпрома» в период с 2013 по 2025 г. Результаты работы моделей и метрики качества для задачи прогнозирования приведены в табл. 2, причем лучший результат по обучениям дали Catboost и BaggingClassifier. Заметим, что модель не переобучалась при изначальных параметрах модели. Такой эффект получился из-за того, что исходные параметры моделей не были оптимальными. Для наилучшего качества модели были подобраны гиперпараметры модели, проведено сравнение различных моделей и оптимизированы гиперпараметры с помощью GridSearchCV библиотеки sklearn.model_selection.
Стоит отметить, что универсальной модели для всех финансовых активов не существует, поскольку данные имеют разные распределения и в них существуют структурные изменения. Для подтверждения этого факта проведено сравнение моделей на тестовых данных котировок SBER и получены иные значения их метрик качества (табл. 3).
Результаты вычислительных экспериментов продемонстрировали, что для алгоритма Catboost средний показатель Precision составляет 0,72 (табл. 3). Также достаточно высокие результаты показывают алгоритмы LSTM и GRU, которые в среднем имеют показатель Precision равный 0,70. Для модели Catboost, которая показала достаточно высокие значения метрики качества для акций «Сбера» (табл. 3), с помощью Catboost grid_search библиотеки Catboost были подобраны гиперпараметры. Начальные условия для подбора гиперпараметров задаются программным кодом, представленным на рис. 4. После подбора оптимальных параметров был подобран результат: depth’: 4, ‘l2_leaf_reg’: 7, ‘learning_rate’: 0.1 и получены лучшие значения метрик (табл. 4).
Таблица 2
Метрики качества моделей для акций «Газпрома» (2013–2025)
|
Модель |
Catboost |
LSTM (100 эпох) |
GRU (100 эпох) |
Random Forest Classifier |
Метод опорных векторов |
AdaBoost ADB |
Bagging Classifier |
|
accuracy |
0,790131 |
0,740323 |
0,730323 |
0,741935 |
0,721935 |
0,72043 |
0,810526 |
|
Precision |
0,738768 |
0,748786 |
0,738768 |
0,694023 |
0,654023 |
0,698413 |
0,863635 |
|
f1_score |
0,77453 |
0,7403 |
0,74412 |
0,725614 |
0,712714 |
0,723304 |
0,8125 |
|
AUC-ROC |
0,792357 |
0,740457 |
0,740457 |
0,745226 |
0,712217 |
0,721057 |
0,813333 |
Примечание: составлена автором на основе полученных данных в ходе исследования
Таблица 3
Метрики качества моделей для акций SBER (2013–2025)
|
Модель |
Catboost |
LSTM (100 эпох) |
GRU (100 эпох) |
Random Forest Classifier |
Метод опорных векторов |
AdaBoost ADB |
Bagging Classifier |
|
accuracy |
0,75406 |
0,700213 |
0,710433 |
0,668213 |
0,648213 |
0,689095 |
0,649652 |
|
Precision |
0,716667 |
0,698728 |
0,701223 |
0,629344 |
0,629344 |
0,716757 |
0,628821 |
|
f1_score |
0,742718 |
0,69556 |
0,692718 |
0,636132 |
0,636132 |
0,734127 |
0,643026 |
|
AUC-ROC |
0,755678 |
0,70411 |
0,710423 |
0,670901 |
0,670901 |
0,685219 |
0,650549 |
Примечание: составлена автором на основе полученных данных в ходе исследования
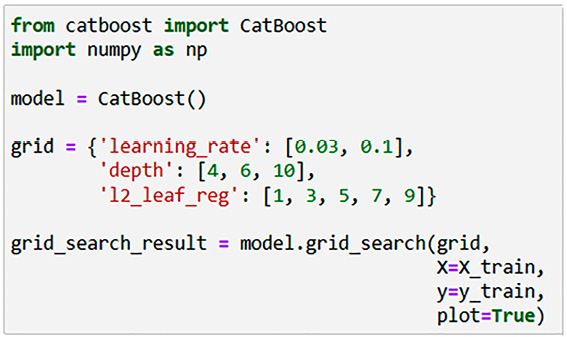
Рис. 4. Код для подбора гиперпараметров для Catboost Примечание: составлен автором по результатам данного исследования
Таблица 4
Метрики качества для Catboost акций SBER (2013–2025)
|
accuracy |
Precision |
f1_score |
AUC-ROC |
|
0,771022 |
0,752091 |
0,771022 |
0,771521 |
Примечание: составлена автором на основе полученных данных в ходе исследования.
Заметим, что при подстановке оптимальных гиперпараметров, значение accuracy увеличилось до 0,77, тем не менее точность оценки остается невысокой (табл. 4), и для эффективной помощи инвесторам или другим участникам рынка она недостаточно высокая. Это можно объяснить тем, что российский рынок достаточно волатильный, для прогноза нужно иметь больше исторических данных, а также внедрить новостной окрас для активных участников рынка.
Для сопоставления предсказаний и действительности построены матрицы ошибок (функция confusion_matrix() библиотеки sklearn.metrics). Матрица ошибок – таблица, в которой отображается число предсказанных и фактических классов для классификационной модели [16]. В случае бинарной классификации матрица ошибок имеет следующую структуру:
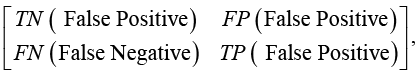
где обозначения для TN, FP, FN, TP те же, что и в (2).
На рис. 5 визуализирована матрица ошибок по данным котировок акций «Сбера». В данном случае модель предсказала положительный результат, а на самом деле он отрицательный (FP) и, когда модель предсказала отрицательный результат, но на самом деле он положительный (FN) примерно одинаковое количество, что означает, что модель не переобучалась.
На основании результатов работы моделей и значений их метрик замечено, что выбирать одну из перечисленных моделей (табл. 2, 3) для последующего использования на каждой акции неверно: каждая модель по-своему хороша для тех или иных целей, поэтому не следует после загрузки данных обучать каждый раз выбранные модели.
Проведенное исследование показало, что модели машинного обучения и глубокого обучения при хорошей предобработке данных подходят для использования в качестве «торгового помощника» для помощи трейдерам и инвесторам. Однако при создании такого помощника необходимо учитывать то, что его можно интерпретировать только как торговый индикатор, который поможет выбрать стратегию поведения участникам рынка.

Рис. 5. Матрица ошибок, построенная по данным котировок акций «Сбера» Примечание: составлен автором по результатам данного исследования
Основная цель этой статьи состояла в том, чтобы сравнить методы классификации, применяемые в машинном обучении, для предсказания тренда стоимостей акций российских компаний. В итоге сделан вывод, что модели машинного обучения и глубокого обучения при хорошей предобработке исторических данных подходят для использования в качестве первоначального инструмента помощи участникам рынка. Решены вспомогательные задачи и получены следующие результаты: подготовлены данные для применения машинного обучения; применены исследуемые методы машинного обучения на предобработанных данных; проведен анализ полученных результатов.
Ниже представлены основные рекомендации автора исследования:
1. Применять модель следует для оценки стоимостей акций российских компаний.
2. Создание «торгового помощника» рекомендуется при условии его интеграции с другими финансовыми инструментами Московской биржи, поскольку созданная в исследовании модель хорошо «отрабатывает» предсказания на одних акциях, но показывает средний или даже плохой результат на других акциях.
3. Внедрить в модель новости с эмоциональной окраской, увеличить использование технических индикаторов и расширить объем исторических данных, что повысит точность прогнозов.
4. Разработать интуитивно понятное интерактивное веб-приложение. Веб-приложение позволит участникам финансового рынка лишь применять готовую модель для предсказания изменений стоимостей акций, не имея при этом навыков программирования и знаний о нейросетях.
Заключение
В мировом сообществе намечается возрастающая тенденция применения методов машинного обучения во многих отраслях человеческой деятельности, в том числе в сфере финансовой деятельности в целом. Российский рынок акций на Московской бирже – это подходящая платформа для краткосрочного прогнозирования их стоимостей. Программный инструмент «Торговый помощник», при условии грамотного подбора моделей машинного обучения, совместно с другими финансовыми инструментами, имеющимися на Московской бирже, позволит участникам рынка получать прогнозы изменения стоимостей акций на одни сутки вперед. Информация о полученных прогнозных оценках стоимостей финансовых активов может позволить инвесторам, трейдерам и другим участникам рынка принимать более взвешенные инвестиционные решения.
Конфликт интересов
Финансирование
Библиографическая ссылка
Шамраева В.В. ПРОГНОЗИРОВАНИЕ СТОИМОСТЕЙ ФИНАНСОВЫХ АКТИВОВ МОСКОВСКОЙ БИРЖИ МЕТОДАМИ МАШИННОГО ОБУЧЕНИЯ // Фундаментальные исследования. 2026. № 3. С. 118-125;URL: https://fundamental-research.ru/ru/article/view?id=44000 (дата обращения: 10.07.2026).
DOI: https://doi.org/10.17513/fr.44000